

Hadoop - Uruchamianie przykładu MapReduce WordCount
- 2406
- 610
- Maria Piwowarczyk
Ten samouczek pomoże ci uruchomić przykład MapReduce WordCount w Hadoop za pomocą wiersza poleceń. Może to być również wstępny test testowania konfiguracji Hadoop.
1. Wymagania wstępne
Musisz mieć konfigurację Hadoop w swoim systemie. Jeśli nie zainstalowałeś Hadoop, odwiedź instalację Hadoop w samouczku Linux.
2. Skopiuj pliki do systemu plików Namenode
Po pomyślnym sformatowaniu nazwy, musisz poprawnie rozpocząć wszystkie usługi Hadoop. Teraz utwórz katalog w systemie plików Hadoop.
$ hdfs dfs -mkdir -p/użytkownik/hadoop/wejście
Skopiuj skopiuj plik tekstowy do systemu plików Hadoop Inside Directory. Tutaj kopiuję licencję.txt do tego. Możesz skopiować więcej plików.
Licencja $ HDFS DFS -PUT.txt/user/hadoop/input/
3. Uruchamianie polecenia WordCount
Teraz uruchom przykład WordCount MapReduce za pomocą następującego polecenia. Poniższe polecenie odczytuje wszystkie pliki z folderu wejściowego i przetwarzaj z plik MapReduce JAR. Po pomyślnym zakończeniu wyników zadań zostanie umieszczone w katalogu wyjściowym.
$ cd $ hadoop_home $ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.Wyjście wejściowe jar WordCount
4. Pokaż wyniki
Po raz pierwszy sprawdź nazwy pliku wyników utworzonych w [e -mail chroniony]/user/hadoop/wyjście system plików za pomocą następującego polecenia.
$ HDFS DFS -LS/User/Hadoop/wyjście
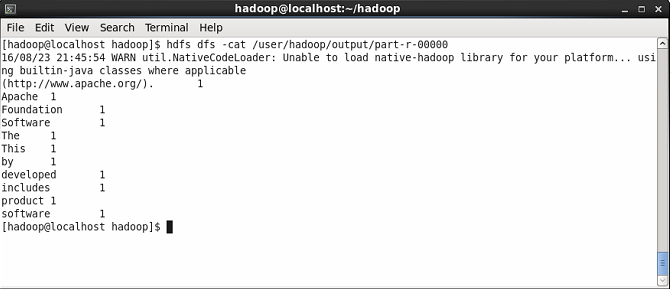
Teraz pokaż treść pliku wyników, w którym zobaczysz wynik WordCount. Zobaczysz liczbę każdego słowa.
$ hdfs dfs -cat/user/hadoop/wyjście/część-r-00000
- « Jak zainstalować 1.19 O Fedora 36/35 i Centos/Rhel 8/7
- Jak zainstalować Apache Maven na Centos/RHEL 8/7 »