

Jak tworzyć kopię zapasową plików do Amazon S3 za pomocą kopii zapasowej CloudBerry w Linux

- 2234
- 92
- Tomasz Szatkowski
Amazon Simple Storage Service (S3) pozwala nowoczesnym firmom przechowywać swoje dane, zbierać je z wielu różnych źródeł i łatwo je analizować z dowolnego miejsca. Dzięki solidnym bezpieczeństwu, możliwościom zgodności, zarządzaniu i natywnym narzędziom analitycznym, Amazon S3 wyróżnia się w branży przechowywania w chmurze.
Ponadto dane są przechowywane zbędnie w wielu, fizycznie oddzielonych centrach danych z niezależnymi podstacjiami mocy. Innymi słowy, S3 Zabiera cię bez względu na wszystko.
Co może być doskonalsze niż to? Cloudberry, #1 Splatform Cloud Backup Software może być płynnie zintegrowane z Amazon S3. Daje to doświadczenie, wsparcie i funkcjonalność 2 ciężkich ciężarów w jednym miejscu. Poświęćmy kilka minut, aby odkryć, w jaki sposób możesz wykorzystać moc tych rozwiązań do tworzenia kopii zapasowych plików w chmurze.
Instalowanie i aktywowanie licencji CloudBerry
W tym artykule zainstalujemy i skonfigurujemy Cloudberry na Centos 7 System komputerowy. Instrukcje dostarczone w CloudBerry Backup for Linux: Recenzja i instalacja powinny mieć zastosowanie z minimalnymi (jeśli w ogóle) modyfikacji w innych rozkładach komputerów stacjonarnych, takich jak Ubuntu, Fedora, Lub Debian.
Proces instalacji można podsumować w następujący sposób:
-
- Pobierz bezpłatną próbę ze strony rozwiązania kopii zapasowej Cloudberry Linux.
- Kliknij dwukrotnie plik i wybierz zainstalować.
- Wyjmij plik instalacyjny.
- Aby aktywować licencję próbną, otwórz terminal i uruchom następujące polecenia (zwróć uwagę na parę pojedynczych cytatów wokół kopii zapasowej CloudBerry w pierwszym):
# cd/opt/local/'cloudberry backup'/bin # ./CBB Activatelicense -e "[chroniony e -mail]„-t„ Ultimate ”
- Idź do Internet Lub Biuro sekcja pod Twoim Aplikacje menu.
- Wybierać Kopia zapasowa Cloudberry I Kontynuować proces, a następnie kliknij Skończyć.
To wszystko - teraz skonfigurujmy Cloudberry używać Amazon S3 Jako nasze rozwiązanie do przechowywania w chmurze.
Konfigurowanie Cloudberry + Amazon S3
Integracja Cloudberry I Amazon S3 to spacer po parku:
Aby rozpocząć, kliknij Ustawienia menu i wybierz Amazon S3 i lodowiec z listy. Będziesz także musiał wybrać opisowy Wyświetlana nazwa, i wprowadź swój Dostęp i sekret Klucze.
Powinny być dostępne w Twoim Amazon S3 konto, podobnie jak Wiaderko gdzie będziesz przechowywać swoje dane. Kiedy skończysz, spójrz pod Pamięć kopii zapasowej Aby znaleźć nowo utworzone rozwiązanie do tworzenia kopii zapasowych:
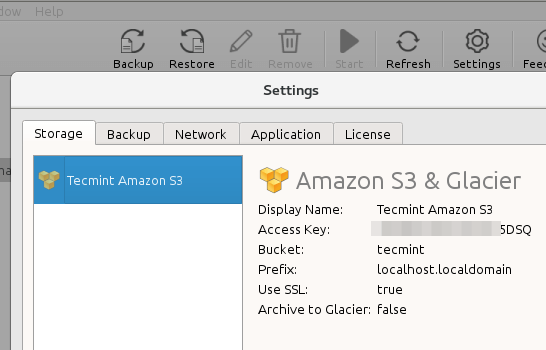 Amazon S3 Storage
Amazon S3 Storage Wskazówka: Możesz teraz przejść do Kopia zapasowa Tab, aby wskazać, ile wersji plików chcesz zachować, i czy chcesz podążać miękkie linki, czy nie, między innymi ustawieniami.
Następnie, aby utworzyć plan kopii zapasowej, wybierz Kopia zapasowa Menu i pamięć w chmurze, którą utworzyliśmy wcześniej:
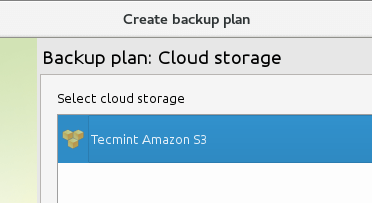 Wybierz kopię zapasową Amazon S3
Wybierz kopię zapasową Amazon S3 Teraz podaj nazwę planu:
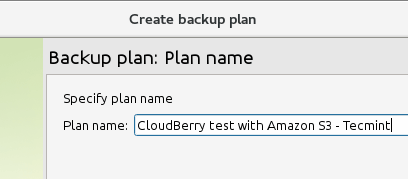 Dodaj nazwę planu kopii zapasowej Amazon S3
Dodaj nazwę planu kopii zapasowej Amazon S3 i wskaż lokalizację, którą chcesz wykonać kopię zapasową:
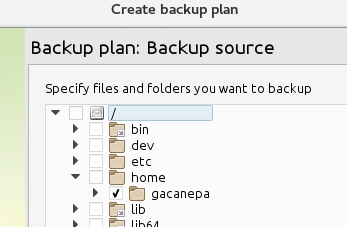 Wybierz lokalizację kopii zapasowej
Wybierz lokalizację kopii zapasowej Czy chcesz wykluczyć niektóre typy plików? To nie jest problem:
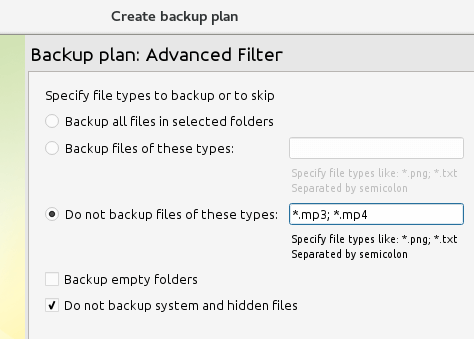 Wyklucz pliki do kopii zapasowej
Wyklucz pliki do kopii zapasowej Szyfrowanie i kompresja w celu zwiększenia prędkości transferu danych i bezpieczeństwa? Założysz się:
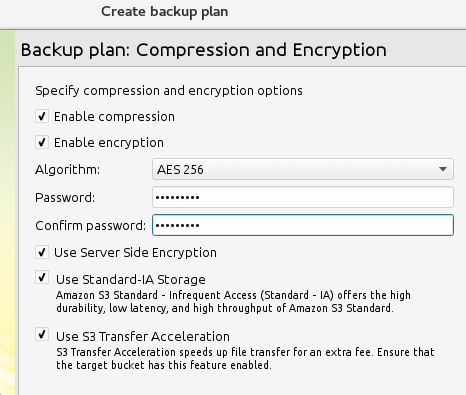 Włącz kompresję i szyfrowanie podczas kopii zapasowej
Włącz kompresję i szyfrowanie podczas kopii zapasowej Możesz albo skorzystać z zasady retencji kopii zapasowej zdefiniowanej dla całego produktu lub utworzyć je specjalnie dla bieżącego planu. Pójdziemy z pierwszymi tutaj. Na koniec określmy częstotliwość kopii zapasowej lub metodę, która najlepiej odpowiada naszym potrzebom:
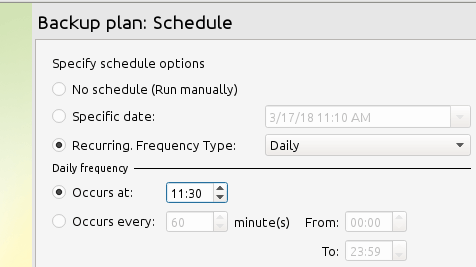 Określ częstotliwość kopii zapasowej
Określ częstotliwość kopii zapasowej Pod koniec stworzenia planu, Cloudberry Pozwala to uruchomić. Możesz to zrobić lub poczekać, aż nastąpi następny zaplanowany kopia zapasowa. Jeśli wystąpią jakiekolwiek błędy, otrzymasz powiadomienie na zarejestrowany adres e -mail, który wyświetla poprawienie, co jest nie tak.
Na poniższym obrazie możemy to zobaczyć S3 przyspieszenie transferu nie jest włączony w Tecmint wiaderko. Możemy albo włączyć go zgodnie z instrukcjami podanymi na stronie przyspieszenia transferu Amazon S3, albo usunąć tę funkcję z aktualnej konfiguracji naszego planu.
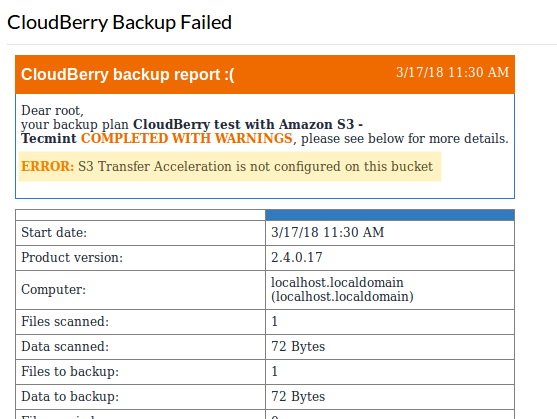 Opcja przyspieszenia transferu Amazon S3
Opcja przyspieszenia transferu Amazon S3 Po poprawieniu powyższego problemu, uruchommy ponownie kopię zapasową. Tym razem się powiedzie:
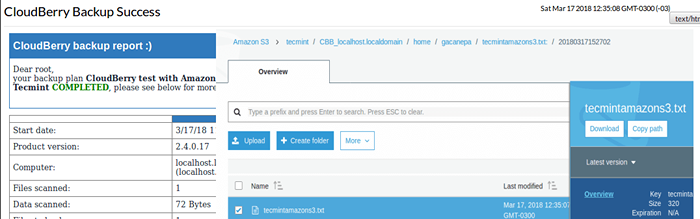 Raport kopii zapasowej Cloudberry
Raport kopii zapasowej Cloudberry Zauważ, że możesz przechowywać wiele wersji tych samych plików, jak wskazano wcześniej. Aby odróżnić się od drugiego, na końcu ścieżki dodaje się znacznik czasu (20180317152702) Jak widać na powyższym obrazie.
Przywracanie plików z Amazon S3
Oczywiście, tworzenie kopii zapasowej naszych plików byłoby bezużyteczne, gdybyśmy nie mogli ich przywrócić, gdy ich potrzebujemy. Aby skonfigurować proces odbudowy, kliknij Przywrócić menu i wybierz plan, którego będziesz używać. Ponieważ zaangażowane kroki są dość proste, nie będziemy tutaj szczegółowo omawiać. Podsumujmy jednak kroki jako szybkie odniesienie:
- Wskaż metodę przywracania: Przywróć raz (po naciśnięciu Skończyć w ostatnim kroku czarodzieja) lub stwórz Przywrócić planuj uruchomić w określonym czasie.
- Jeśli przechowujesz wiele wersji swoich plików, musisz powiedzieć Cloudberry Jeśli chcesz przywrócić najnowszą wersję lub tę w określonym momencie.
- Określ pliki i katalogi, które chcesz przywrócić.
- Wprowadź hasło do deszyfrowania. To samo, co było używane do szyfrowania plików (-ów).
Po zakończeniu przywracanie zostanie wykonane automatycznie. Jak widać na poniższym obrazie, plik Tecmintamazons3.tekst został przywrócony po usunięciu ręcznie z /dom/gacanepa:
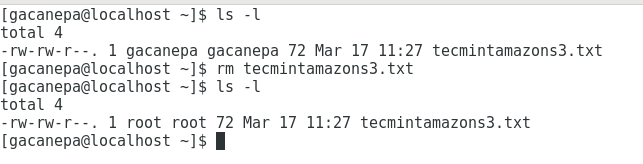 Przywróć pliki z Amazon S3
Przywróć pliki z Amazon S3 Gratulacje! Skonfigurowałeś kompletne rozwiązanie do tworzenia kopii zapasowych i przywracasz w mniej niż 30 minut.
Streszczenie
W tym poście wyjaśniliśmy, jak wykonać kopię zapasową plików (-ów) do iz i od Amazon S3 za pomocą Cloudberry. Ze wszystkimi funkcjami oferowanymi przez te 2 narzędzia, nie musisz szukać żadnych potrzeb dla twoich potrzeb twoich.
Jeśli masz jakieś pytania, skontaktuj się z nami za pomocą formularza komentarza.
- « Jak losowo wyświetlać ASCII Art na terminalu Linux
- GOTO - Szybko przejdź do aliasowych katalogów z wsparciem automatycznego komplecji »