

Jak policzyć zdarzenia słów w pliku tekstowym
- 4263
- 323
- Pan Jeremiasz Więcek
Graficzny interfejs użytkownika Procesory tekstu i aplikacje do notatki mają wskaźniki informacji lub szczegółów szczegółów dokumentów, takich jak liczba stron, słowa, I postacie, Lista nagłówków w edytorach tekstu, tabela treści u niektórych redaktorów Markdown itp. a znalezienie wystąpienia słów lub fraz jest tak łatwe, jak uderzenie Ctrl + f i wpisując postacie, których chcesz wyszukać.
A GUI czyni wszystko łatwym, ale co się dzieje, gdy możesz pracować tylko z wiersza poleceń i chcesz sprawdzić liczbę razy słowo, fraza lub znak w pliku tekstowym? Jest to prawie tak proste, jak podczas korzystania z GUI, o ile masz odpowiednie polecenie i zamierzam ci opowiedzieć, jak to się robi.
Załóżmy, że masz przykład.tekst plik zawierający zdania:
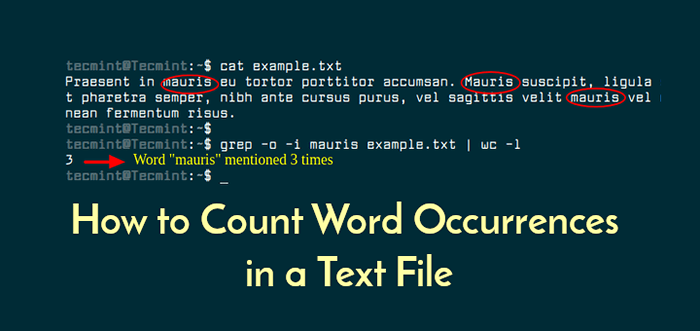
Praesent in Mauris UE Tortor Porttitor Accumsan. Mauris Suscipit, Ligula Sit Amet Pharetra Semper, Nibh Ante Cursus Purus, Vel Sagittis Velit Mauris Vel Metus enean fermentum risus.
Możesz użyć polecenia GREP, aby policzyć liczbę razy „Mauris” pojawia się w pliku, jak pokazano.
Przykład $ grep -o -i mauris.txt | WC -L
 Występowanie słów w pliku Linux
Występowanie słów w pliku Linux Za pomocą GREP -C sam będzie liczyć liczbę linii zawierających pasujące słowo zamiast liczby łącznych dopasowań. -o Opcja jest tym, co każe Grepowi wyświetlić każdy dopasowanie w unikalnej linii, a następnie WC -L mówi WC, aby policzył liczbę linii. W ten sposób wywnioskowana jest całkowita liczba dopasowanych słów.
Innym podejściem jest przekształcenie zawartości pliku wejściowego za pomocą polecenia TR, aby wszystkie słowa znajdowały się w jednym wierszu, a następnie użyć GREP -C liczyć ten mecz.
$ tr '[: space:] "[\ n*]' ' < example.txt | grep -i -c mauris
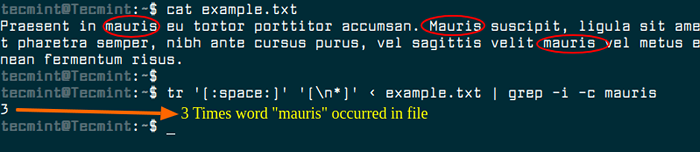 Policz występowanie słowa w pliku
Policz występowanie słowa w pliku Czy w ten sposób sprawdzisz występowanie słowa z terminala? Podziel się z nami swoimi doświadczeniami i daj nam znać, jeśli masz inny sposób wykonania zadania.
- « Najlepszy wiersz poleceń Klienci HTTP dla Linux
- Jak skonfigurować stacja robocza programisty w RHEL 8 »