

Jak stworzyć gorący tryb gotowości z PostgreSQL
- 1490
- 279
- Klaudia Woś
Cel
Naszym celem jest utworzenie kopii bazy danych PostgreSQL, która stale synchronizuje się z oryginalną i akceptuje zapytania tylko do odczytu.
Wersje systemu operacyjnego i oprogramowania
- System operacyjny: Red Hat Enterprise Linux 7.5
- Oprogramowanie: PostgreSQL Server 9.2
Wymagania
Uprzywilejowany dostęp zarówno do systemów głównych, jak i niewolników
Konwencje
- # - Wymaga, aby podane polecenia Linux są wykonywane z uprawnieniami root bezpośrednio jako użytkownik root lub za pomocą
sudoKomenda - $ - Biorąc pod uwagę polecenia Linux, które mają być wykonywane jako zwykły użytkownik niepewny
Wstęp
PostgreSQL to RDBMS open source (relacyjny system zarządzania bazą danych), a przy dowolnych bazach danych potrzeba może powstać w celu skalowania i zapewnienia HA (wysoka dostępność). Pojedynczy system świadczący usługi jest zawsze możliwym pojedynczym punktem awarii - a nawet w przypadku systemów wirtualnych może być czas, w którym nie można dodać więcej zasobów do jednej maszyny, aby poradzić sobie z coraz większym obciążeniem. Może być również potrzeba innej kopii zawartości bazy danych, którą można zapytać o długotrwałe analityki, które nie są odpowiednie do uruchomienia w bazie danych produkcyjnych o wysoce transakcji. Ta kopia może być prostym przywracaniem z najnowszej kopii zapasowej na innym komputerze, ale dane byłyby przestarzałe, gdy tylko zostaną przywrócone.
Tworząc kopię bazy danych, która nieustannie replikuje swoją zawartość z oryginalnym (zwanym master lub podstawowym), ale wykonując to akceptację i zwracając wyniki do zapytań tylko do odczytu, możemy utworzyć Gorący tryb gotowości które mają dokładnie tę samą zawartość.
W przypadku awarii w Master, rezerwowa (lub niewolnik) baza danych może przejąć rolę podstawowej, zatrzymać synchronizację i zaakceptować żądania odczytu i zapisu, aby operacje mogą kontynuować, a nieudany mistrz może zostać zwrócony do życia (być może nieudany mistrz może zostać zwrócony do życia (być może nieudany mistrz może zostać zwrócony (być jako gotowość poprzez zmianę sposobu synchronizacji). Kiedy uruchomi się zarówno podstawowy, jak i gotowy, zapytania, które nie próbują modyfikować treści bazy danych, mogą zostać odniesione do gotowości, aby ogólny system był w stanie obsłużyć większe obciążenie. Należy jednak zauważyć, że nastąpi opóźnienie - w trybie gotowości będzie za mistrzem, do ilości czasu potrzebnego na zsynchronizację zmian. Opóźnienie to może się nie oszukać w zależności od konfiguracji.
Istnieje wiele sposobów na zbudowanie synchronizacji master-niewolnicy (a nawet mistrza-mistrza) z PostgreSQL, ale w tym samouczku skonfigurujemy replikację przesyłania strumieniowego, przy użyciu najnowszego serwera PostgreSQL dostępnego w repozytoriach Red Hat. Ten sam proces jest ogólnie dotyczy innych dystrybucji i wersji RDMBS, ale mogą istnieć różnice dotyczące ścieżek systemu plików, menedżerów pakietów i usług i takich.
Instalowanie wymaganego oprogramowania
Zainstalujmy PostgreSQL z mniam Do obu systemów:
Yum Instal PostgreSQL-Server
Po udanej instalacji musimy zainicjować oba klastry bazy danych:
# PostgreSQL-SETUP Initdb Inicjowanie bazy danych… . OK Aby zapewnić automatyczny uruchamianie baz danych w rozruchu, możemy włączyć usługę w Systemd:
Systemctl Włącz PostgreSQL
Użyjemy 10.10.10.100 jako podstawowy i 10.10.10.101 Jako adres IP maszyny rezerwowej.
Skonfiguruj mistrz
Zasadniczo dobrym pomysłem jest wykonanie kopii zapasowej dowolnych plików konfiguracyjnych przed wprowadzeniem zmian. Nie zajmują miejsca, o których warto wspomnieć, a jeśli coś pójdzie nie tak, kopia zapasowa działającego pliku konfiguracyjnego może być ratunkiem.
Musimy edytować PG_HBA.conf z edytorem plików tekstowych, takim jak vi Lub Nano. Musimy dodać regułę, która pozwoli użytkownikowi bazy danych z gotowości w celu uzyskania dostępu do pierwotnego. To jest ustawienie po stronie serwera, użytkownik nie istnieje jeszcze w bazie danych. Przykłady można znaleźć na końcu skomentowanego pliku, które są powiązane z Replikacja Baza danych:
# Zezwalaj na połączenia z replikacją od LocalHost, przez użytkownika z uprawnieniem do replikacji #. #Local Replikacja Postgres Peer #host replikacja Postgres 127.0.0.1/32 Identyfikator #host replikacja Postgres :: 1/128 Identyfikator
Dodajmy kolejną linię na koniec pliku i zaznacz ją komentarzem, aby można go było łatwo zobaczyć, co zostało zmienione z domyślnych:
## MyConf: Replikacja replikacji replikacji replikacji 10.10.10.101/32 MD5
Na smakach Red Hat plik znajduje się domyślnie pod /var/lib/pgsql/data/ informator.
Musimy również wprowadzić zmiany w głównym pliku konfiguracyjnym serwera bazy danych, PostgreSQL.conf, który znajduje się w tym samym katalogu, który znaleźliśmy PG_HBA.conf.
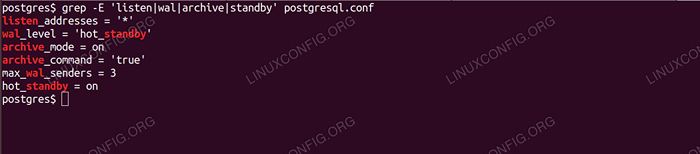
Znajdź ustawienia znalezione w poniższej tabeli i zmodyfikuj je w następujący sposób:
| Sekcja | Ustawienia domyślne | Zmodyfikowane ustawienie |
|---|---|---|
| Połączenia i uwierzytelnianie | #Listen_Addresses = „LocalHost” | Listen_Addresses = '*' |
| Napisz dziennik z wyprzedzeniem | #wal_level = minimalny | Wal_Level = „hot_standby” |
| Napisz dziennik z wyprzedzeniem | #archive_mode = off | Archive_mode = ON |
| Napisz dziennik z wyprzedzeniem | #archive_command = ” | Archive_Command = „True” |
| Replikacja | #max_wal_senders = 0 | max_wal_senders = 3 |
| Replikacja | #hot_standby = off | hot_standby = on |
Zauważ, że powyższe ustawienia są domyślnie skomentowane; Musisz się porzucić I zmień ich wartości.
Możesz Grep zmodyfikowane wartości weryfikacji. Powinieneś uzyskać coś takiego:
Weryfikacja zmian w przypadku GREP Teraz, gdy ustawienia są w porządku, uruchommy serwer podstawowy:
# SystemCtl Start PostgreSQL
I użyć PSQL Aby utworzyć użytkownika bazy danych, który obsługuje replikację:
# Su -Postgres -Bash -4.2 $ PSQL PSQL (9.2.23) Wpisz „pomoc” o pomoc. Postgres =# Utwórz replikację użytkownika Replikacja Logowanie zaszyfrowane hasło „SecretPassword” Limit połączenia -1; Stwórz rolę
Zwróć uwagę na hasło, które podajesz Repuser, będziemy go potrzebować po stronie rezerwowej.
Skonfiguruj niewolnika
Zostawiliśmy tryb gotowości z initdb krok. Będziemy pracować jako Postgres użytkownik, który jest superuser w kontekście bazy danych. Będziemy potrzebować wstępnej kopii podstawowej bazy danych i otrzymamy to z PG_BASEBAKUP Komenda. Najpierw wyczywamy katalog danych w trybie gotowości (wcześniej wykonaj kopię, jeśli chcesz, ale jest to tylko pusta baza danych):
$ rm -rf/var/lib/pgsql/data/*
Teraz jesteśmy gotowi stworzyć spójną kopię podstawowej do gotowości:
$ PG_BASEBAKUP -H 10.10.10.100 -U repuser -d/var/lib/pgsql/data/hasło: W tym przypadku musimy określić adres IP Mistrza, a użytkownik, który utworzyliśmy do replikacji, w tym przypadku Repuser. Ponieważ podstawowy jest pusty oprócz tego użytkownika, który stworzyliśmy, PG_BASEBAKUP powinien zakończyć się w kilka sekund (w zależności od przepustowości sieci). Jeśli coś pójdzie nie tak, sprawdź zasadę HBA na podstawie podstawowej, poprawność adresu IP podanego na PG_BASEBAKUP polecenie, a ten port 5432 na podstawie jest osiągalny z rezerwatu (na przykład z Telnet).
Po zakończeniu kopii zapasowej zauważysz, że katalog danych jest wypełniony na niewolniku, w tym pliki konfiguracyjne (pamiętaj, usunęliśmy wszystko z tego katalogu):
# ls/var/lib/pgsql/data/backup_label.stary PG_CLOG PG_LOG PG_SERIAL PG_SUBTRANS PG_VERSION Postmaster.Opts Base PG_HBA.conf pg_multixact pg_snapshots pg_tblspc pg_xlog postmaster.PID Global PG_IDENT.conf pg_notify PG_STAT_TMP PG_TWOPHASE Postgresql.Conf Recovery.conf Teraz musimy wprowadzić pewne regulacje konfiguracji gotowości. Adres IP włączony dla repusera do połączenia z koniecznością jest adres serwera głównego w PG_HBA.conf:
# Tail -n2/var/lib/pgsql/data/pg_hba.Conf ## myConf: replikacja replikacji replikacji hosta 10.10.10.100/32 MD5 Zmiany w PostgreSQL.conf są takie same jak na Master, ponieważ skopiowaliśmy ten plik z kopią zapasową. W ten sposób oba systemy mogą podjąć rolę głównego lub gotowości w odniesieniu do tych plików konfiguracyjnych.
W tym samym katalogu musimy utworzyć nazywany plik tekstowy powrót do zdrowia.conf, i dodaj następujące ustawienia:
# cat/var/lib/pGSQL/Data/Recovery.Conf Standby_Mode = 'on' Primary_Conninfo = 'host = 10.10.10.100 port = 5432 User = repuser hasło = SecretPassword 'Trigger_file ='/var/lib/pgsql/Trigger_file ' Zauważ, że dla Primary_Conninfo Ustawienie użyliśmy adresu IP podstawowy i hasło, które podaliśmy Repuser W głównej bazie danych. Plik spustowy może być praktycznie w dowolnym miejscu przez Postgres Użytkownik systemu operacyjnego, z dowolną prawidłową nazwą pliku - w przypadku awarii pierwotnej można utworzyć plik (z za pomocą dotykać na przykład), który uruchomi przełączanie awaryjne w trybie gotowości, co oznacza, że baza danych zaczyna również akceptować operacje zapisu.
Jeśli ten plik powrót do zdrowia.conf jest obecny, serwer wprowadzi tryb odzyskiwania podczas uruchamiania. Mamy wszystko na miejscu, abyśmy mogli uruchomić gotowość i sprawdzić, czy wszystko działa tak, jak powinno być:
# SystemCtl Start PostgreSQL
Odzyskanie podpowiedzi powinno zająć trochę więcej czasu. Powodem jest to, że baza danych wykonuje odzyskiwanie do spójnego stanu w tle. Możesz zobaczyć postęp w głównym pliku dziennika bazy danych (nazwa pliku będzie się różnić w zależności od dnia tygodnia):
$ tailf/var/lib/pgsql/data/pg_log/postgresql-thu.Dziennik dziennika: Wprowadzanie dziennika trybu trybu gotowości: Replikacja przesyłania strumieniowego pomyślnie podłączona do dziennika pierwotnego: Reto rozpoczyna się od 300000020 dziennika: Spójny stan odzyskiwania osiągnięty przy dzienniku 0/30000E0: System bazy danych jest gotowy do przyjęcia odczytu tylko połączeń Weryfikacja konfiguracji
Teraz, gdy obie bazy danych są uruchomione, przetestujmy konfigurację, tworząc niektóre obiekty na podstawie podstawowej. Jeśli wszystko pójdzie dobrze, obiekty te powinny ostatecznie pojawić się w gotowości.
Możemy stworzyć kilka prostych obiektów na podstawie podstawowej (które mój wygląd znajomy) PSQL. Możemy utworzyć poniższy prosty skrypt SQL nazywany próbka.SQL:
-- Utwórz sekwencję, która będzie służyć jako PK tabeli pracowników Utwórz sekwencję pracowników_seq Zacznij od 1 przyrostu przez 1 Brak pamięci MinValue 1 pamięć podręczna 1; - Utwórz tabelę pracowników Utwórz tabelę Pracownicy (EMP_ID NUMERIC KLUCZ DECALT NEXTVAL ('EORMATORE_SEQ' :: RegClass), Tekst pierwszej nazwy nie null, Last_name Tekst Not Null, Birth_year Numer nie null, Numernonnt Numer nie null, Birth_dayofmonth Numeric) ; - Włóż dane do tabeli Włóż do pracowników (pierwsza nazwa_namalna, nazwa last_name, Birth_year, Birth_month, Birth_dayofmonth) wartości („Emily”, „James”, 1983,03,20); Wstaw do pracowników (First_name, Last_name, Birth_year, Birth_month, Birth_dayofonth) Wartości („John”, „Smith”, 1990,08,12); Dobrą praktyką jest przechowywanie modyfikacji struktury bazy danych w skryptach (opcjonalnie wepchnięte również do repozytorium kodu), w celu późniejszego odniesienia. Opłaca się, gdy musisz wiedzieć, co zmodyfikowałeś i kiedy. Możemy teraz załadować skrypt do bazy danych:
$ psql < sample.sql CREATE SEQUENCE NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "employees_pkey" for table "employees" CREATE TABLE INSERT 0 1 INSERT 0 1 I możemy zapytać o stół, który stworzyliśmy, z wstawieniem dwóch rekordów:
postgres =# Wybierz * od pracowników; emp_id | First_name | Last_name | Birth_year | Birth_month | Birth_dayofmonth --------+------------+-----------+------------+- -----------+------------------ 1 | Emily | James | 1983 | 3 | 20 2 | John | Smith | 1990 | 8 | 12 (2 wiersze) Przejrzyjmy w trybie gotowości w sprawie danych, które oczekujemy, że będą identyczne z pierwotnym. W trybie gotowości możemy uruchomić powyższe zapytanie:
postgres =# Wybierz * od pracowników; emp_id | First_name | Last_name | Birth_year | Birth_month | Birth_dayofmonth --------+------------+-----------+------------+- -----------+------------------ 1 | Emily | James | 1983 | 3 | 20 2 | John | Smith | 1990 | 8 | 12 (2 wiersze) A po zakończeniu, mamy działającą gorącą konfigurację gotowości z jednym serwerem głównym i jednym serwerem w trybie gotowości, synchronizując się od master do niewolnika, a zapytania tylko do odczytu są dozwolone w Slave.
Wniosek
Istnieje wiele sposobów tworzenia replikacji za pomocą PostgreSQL i istnieje wiele tunelek dotyczących replikacji przesyłania strumieniowego, który skonfigurowaliśmy również, aby konfiguracja była bardziej solidna, nieudana, a nawet mieć więcej członków. Ten samouczek nie ma zastosowania do systemu produkcyjnego - ma na celu pokazanie niektórych ogólnych wytycznych dotyczących tego, co jest zaangażowane w taką konfigurację.
Pamiętaj, że narzędzie PG_BASEBAKUP jest dostępny tylko z PostgreSQL w wersji 9.1+. Możesz także rozważyć dodanie prawidłowego archiwizacji Wal do konfiguracji, ale ze względu na prostotę pominęliśmy to w tym samouczku, aby sprawować minimalne, osiągając działającą parę synchronizacji systemów. I wreszcie jeszcze jedna rzecz do zauważenia: nie kopia zapasowa. Miej ważną kopię zapasową przez cały czas.
Powiązane samouczki Linux:
- Rzeczy do zainstalowania na Ubuntu 20.04
- Ubuntu 20.04 Instalacja PostgreSQL
- Ubuntu 22.04 Instalacja PostgreSQL
- Wprowadzenie do automatyzacji, narzędzi i technik Linuksa
- Rzeczy do zrobienia po zainstalowaniu Ubuntu 20.04 Focal Fossa Linux
- Linux Pliki konfiguracyjne: Top 30 Najważniejsze
- Pobierz Linux
- Czy Linux może uzyskać wirusy? Badanie podatności Linuksa…
- Mint 20: Lepsze niż Ubuntu i Microsoft Windows?
- Rzeczy do zainstalowania na Ubuntu 22.04