

Jak zainstalować i skonfigurować Apache Hadoop w jednym węźle w Centos 7

- 2594
- 751
- Tacjana Karpiński
Apache Hadoop to kompilacja frameworka typu open source dla rozproszonych danych dotyczących pamięci i przetwarzania dużych danych w klastrach komputerowych. Projekt opiera się na następujących komponentach:
- Hadoop Common - Zawiera biblioteki i narzędzia Java potrzebne do innych modułów Hadoop.
- HDFS - Hadoop rozproszony system plików - skalowalny system plików oparty na Javie dystrybuowany w wielu węzłach.
- MapReduce - Framework przędzy do równoległego przetwarzania dużych zbiorów danych.
- Hadoop Yarn: Ramy zarządzania zasobami klastrowymi.
Zainstaluj Hadoop w Centos 7 W tym artykule poprowadzi Cię, w jaki sposób możesz zainstalować Apache Hadoop w klastrze jednego węzła w Centos 7 (również pracuje dla RHEL 7 I Fedora 23+ wersje). Ten typ konfiguracji jest również nazywany Hadoop pseudo dystrybuowany tryb.
Krok 1: Zainstaluj Java na Centos 7
1. Przed przystąpieniem do instalacji Java najpierw zaloguj się z użytkownikiem roota lub użytkownika z uprawnieniami korzeniowymi Ustawienie nazwy hosta komputera za pomocą następującego polecenia.
# hostnamectl set-hostname master
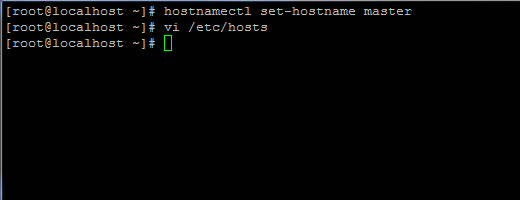 Ustaw nazwę hosta w Centos 7
Ustaw nazwę hosta w Centos 7 Dodaj także nowy rekord w pliku hostów do własnego komputera FQDN, aby wskazać swój adres IP systemu.
# vi /etc /hosts
Dodaj poniższą linię:
192.168.1.41 Master.Hadoop.Lan
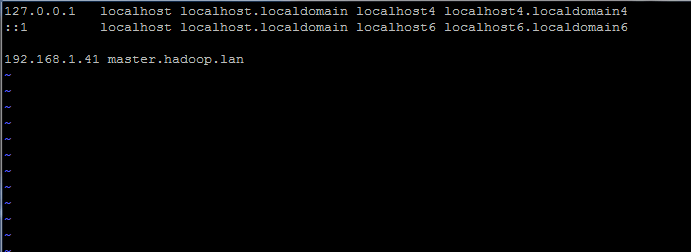 Ustaw nazwę hosta w pliku /etc /hosts
Ustaw nazwę hosta w pliku /etc /hosts Wymień powyższe rekordy hosta i fqdn własnymi ustawieniami.
2. Następnie przejdź do strony pobierania Oracle Java i weź najnowszą wersję Zestaw rozwoju Java SE 8 w twoim systemie za pomocą kędzior Komenda:
# curl -lo -h "Cookie: oraclelicense = Accept -Secureback -Cookie" „http: // pobierz.wyrocznia.com/otn-pub/java/jdk/8u92-b14/jdk-8u92-linux-x64.RPM ”
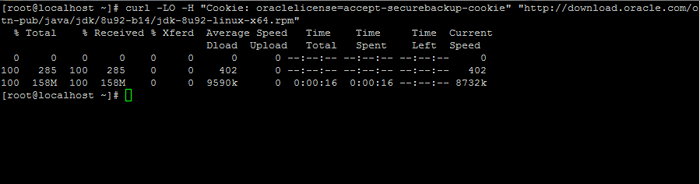 Pobierz Zestaw rozwoju Java SE 8
Pobierz Zestaw rozwoju Java SE 8 3. Po zakończeniu pobierania binarnego Java zainstaluj pakiet, wydając poniższe polecenie:
# rpm -uvh JDK-8U92-Linux-x64.RPM
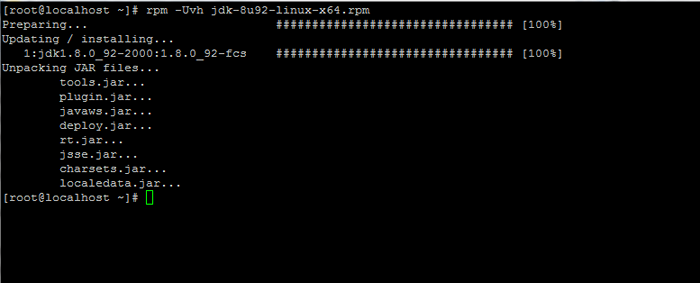 Zainstaluj Java w Centos 7
Zainstaluj Java w Centos 7 Krok 2: Zainstaluj framework Hadoop w Centos 7
4. Następnie utwórz nowe konto użytkownika w systemie bez mocy głównych, które użyjemy do ścieżki instalacji Hadoop i środowiska pracy. Nowy katalog domowy konta będzie przebywać /Opt/Hadoop informator.
# useradd -d /opt /hadoop hadoop # passwd hadoop
5. Na następnym kroku odwiedź stronę Apache Hadoop, aby uzyskać link do najnowszej stabilnej wersji i pobierz archiwum w swoim systemie.
# curl -o http: // apache.Javapipe.com/hadoop/common/hadoop-2.7.2/Hadoop-2.7.2.smoła.GZ
 Pobierz pakiet Hadoop
Pobierz pakiet Hadoop 6. Wyodrębnij archiwum Kopiuj zawartość katalogu do Hadoop Conta Home Path. Upewnij się również, że odpowiednio zmieniłeś skopiowane uprawnienia.
# tar xfz hadoop-2.7.2.smoła.GZ # CP -RF HADOOP -2.7.2/*/opt/hadoop/ # chown -r hadoop: hadoop/opt/hadoop/
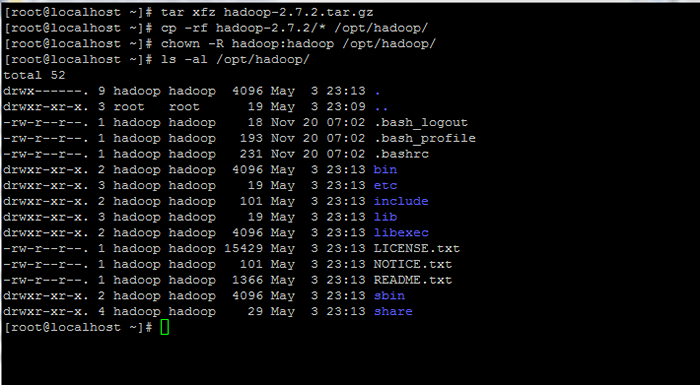 Wyodrębnij i ustawiaj uprawnienia do Hadoop
Wyodrębnij i ustawiaj uprawnienia do Hadoop 7. Następnie zaloguj się z Hadoop użytkownik i konfiguruj Hadoop I Zmienne środowiskowe Java w twoim systemie, edytując .bash_profile plik.
# su - hadoop $ vi .bash_profile
Dołącz następujące wiersze na końcu pliku:
## Java Env zmienne Eksport java_home =/usr/java/default eksport ścieżka = $ ścieżka: $ java_home/bin export classPath =.: $ Java_home/jre/lib: $ java_home/lib: $ java_home/lib/tools.słoik ## Hadoop Zmienne Env Eksport hadoop_home =/opt/hadoop eksport hadoop_common_home = $ hadoop_home export hadoop_hdfs_home = $ hadoop_home eksport hadoop_mapred_home = $ hadoop_home export hadoop_yarn_home = $ hadoop_home eksport hadoop_opts = "-DJava.biblioteka.ścieżka = $ hadoop_home/lib/natywna "eksport hadoop_common_lib_native_dir = $ hadoop_home/lib/natywna ścieżka eksportu = $ ścieżka: $ hadoop_home/sbin: $ hadoop_home/bin
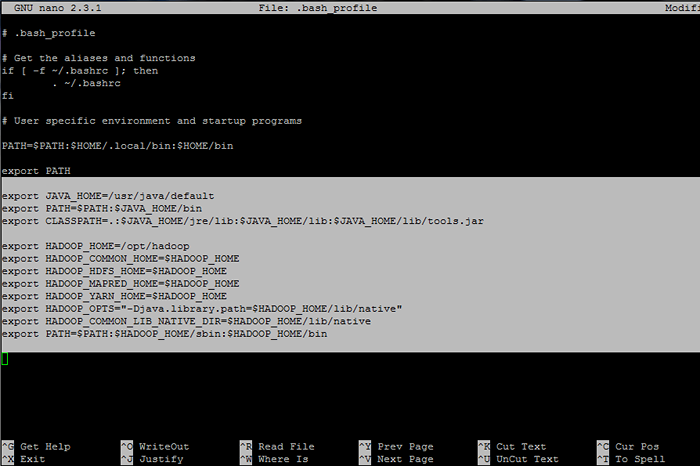 Skonfiguruj zmienne środowiskowe Hadoop i Java
Skonfiguruj zmienne środowiskowe Hadoop i Java 8. Teraz zainicjuj zmienne środowiskowe i sprawdź ich status, wydając poniższe polecenia:
$ źródło .bash_profile $ echo $ hadoop_home $ echo $ java_home
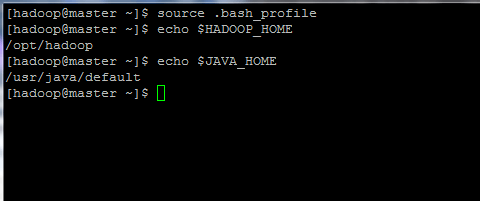 Zainicjuj zmienne środowiskowe Linux
Zainicjuj zmienne środowiskowe Linux 9. Na koniec skonfiguruj uwierzytelnianie oparte na kluczu SSH dla Hadoop konto przez uruchamianie poniższych poleceń (wymień plik Nazwa hosta Lub Fqdn niezgodne z ssh-copy-id Polecenie odpowiednio).
Pozostaw także fraza złożone puste w celu automatycznego zalogowania się za pośrednictwem SSH.
$ ssh-keygen -t rsa $ ssh-copy-id mistrz.Hadoop.Lan
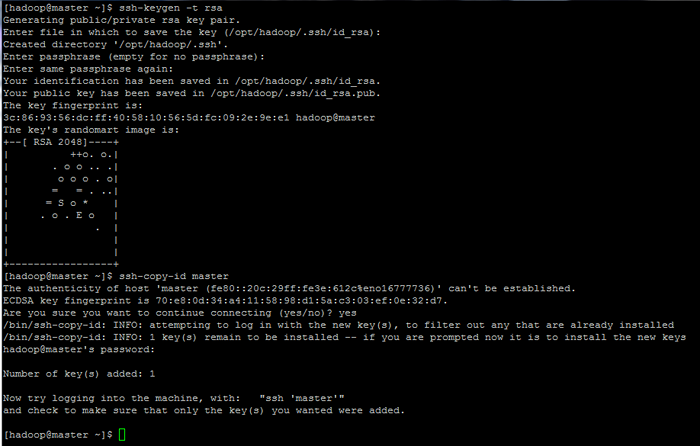 Skonfiguruj strony uwierzytelniania oparte na kluczu SSH: 1 2 3
Skonfiguruj strony uwierzytelniania oparte na kluczu SSH: 1 2 3
- « Znajdź 10 najważniejszych adresów IP uzyskujących dostęp do serwera WWW Apache
- 10 Przydatnych pytań dotyczących wywiadu na temat usług Linux i Demonów »