

Jak zainstalować i skonfigurować Apache Hadoop na Centos i Fedora

- 4387
- 128
- Ignacy Modzelewski
Byłem już od jakiegoś czasu, Hadoop stał się jednym z najpopularniejszych rozwiązań Big Data w otwartym poziomie. Przetwarza dane w partiach i słynie z skalowalnych, opłacalnych i rozproszonych możliwości obliczeniowych. Jest to jedna z najpopularniejszych ram open source w przestrzeni analizy danych i pamięci. Jako użytkownik możesz go używać do zarządzania danymi, analizowania tych danych i przechowywania ich ponownie - wszystko w zautomatyzowany sposób. Po zainstalowaniu Hadoop w systemie Fedora możesz z łatwością uzyskać dostęp do ważnych usług analitycznych.
W tym artykule obejmuje sposób zainstalowania Apache Hadoop w Centos i Fedora Systems. W tym artykule pokażemy, jak zainstalować Apache Hadoop na Fedorę w celu użycia lokalnego, a także serwera produkcyjnego.
1. PRZYKŁADY
Java jest głównym wymogiem uruchamiania Hadoop w dowolnym systemie, więc upewnij się, że Java zainstalował w systemie za pomocą następującego polecenia. Jeśli nie masz zainstalowanej Java w swoim systemie, użyj jednego z następujących linków, aby go najpierw zainstalować.
- Jak zainstalować Java 8 na Centos/RHEL 7/6/5
2. Utwórz użytkownika Hadoop
Zalecamy utworzenie normalnego (ani root) konta dla Hadoop działającej. Aby utworzyć konto za pomocą następującego polecenia.
Adduser Hadoop Passwd Hadoop
Po utworzeniu konta wymagał również skonfigurowania SSH opartych na kluczu na własne konto. Aby to zrobić, użyj wykonania następujących poleceń.
su -hadoop ssh -keygen -t rsa -p "-f ~//.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/autoryzowane_keys chmod 0600 ~/.ssh/autoryzowane_keys
Sprawdźmy logowanie oparte na kluczu. Poniższe polecenie nie powinno prosić o hasło, ale po raz pierwszy wyświetli monit o dodanie RSA do listy znanych hostów.
SSH LocalHost Exit
3. Pobierz Hadoop 3.1 Archiwum
W tym kroku pobierz Hadoop 3.1 plik archiwum źródłowego za pomocą komendy poniżej. Możesz także wybrać alternatywne lustro pobierania w celu zwiększenia prędkości pobierania.
cd ~ wget http: // www-eu.Apache.org/dist/hadoop/common/hadoop-3.1.0/Hadoop-3.1.0.smoła.GZ TAR XZF HADOOP-3.1.0.smoła.GZ MV Hadoop-3.1.0 Hadoop
4. Konfiguracja tryb pseudo-dystrybucji hadoop
4.1. Konfiguruj zmienne środowiskowe Hadoop
Najpierw musimy ustawić zastosowania zmiennych środowiskowych przez Hadoop. Edytować ~/.Bashrc Plik i dołącz następujące wartości na końcu pliku.
Eksport hadoop_home =/home/hadoop/hadoop eksport hadoop_install = $ hadoop_home eksport hadoop_mapred_home = $ hadoop_home export hadoop_common_home = $ hadoop_home eksport hadoop_hdfs_home = $ hadoop_home export yarn_home Hadoop_home/sbin: $ hadoop_home/bin
Teraz zastosuj zmiany w bieżącym środowisku działającym
Źródło ~/.Bashrc
Teraz edytuj $ Hadoop_home/etc/hadoop/hadoop-env.cii plik i zestaw Java_home Zmienna środowiskowa. Zmień ścieżkę Java zgodnie z instalacją w systemie. Ta ścieżka może się różnić w zależności od wersji systemu operacyjnego i źródła instalacji. Upewnij się, że używasz poprawnej ścieżki.
Eksportuj java_home =/usr/lib/jvm/java-8-ojciec
4.2. Konfiguruj pliki konfiguracyjne Hadoop
Hadoop ma wiele plików konfiguracyjnych, które muszą skonfigurować zgodnie z wymaganiami infrastruktury Hadoop. Zacznijmy od konfiguracji z konfiguracją klastra klastra pojedynczego węzła Basic Hadoop. Najpierw przejdź do poniżej lokalizacji
cd $ hadoop_home/etc/hadoop
Edytuj stronę Core.XML
fs.domyślny.Nazwa HDFS: // LocalHost: 9000
Edytuj stronę HDFS.XML
DFS.Replikacja 1 DFS.nazwa.Dir Plik: /// home/hadoop/hadoopdata/hdfs/namenode dfs.dane.Plik dir: /// home/hadoop/hadoopdata/hdfs/dataanode
Edytuj stronę Mapred.XML
MapReduce.struktura.Imię Parn
Edytuj stronę przędzy.XML
przędza.Nodemanager.Aux-Services MAPREDUCE_SHUFLE
4.3. Formatuj nazewniowy
Teraz sformatuj nazwy za pomocą następującego polecenia, upewnij się, że katalog pamięci jest
HDFS Namenode -Format
Przykładowy wyjście:
OSTRZEŻENIE:/Home/Hadoop/Hadoop/Logs nie istnieje. Tworzenie. 2018-05-02 17: 52: 09 678 Info Namenode.Namenode: startup_msg: /*********************************************** *************** Startup_msg: Uruchamianie Namenode startup_msg: host = Tecadmin/127.0.1.1 startup_msg: args = [-format] startup_msg: wersja = 3.1.0… 2018-05-02 17: 52: 13 717 Info Wspólne.Pamięć: katalog pamięci/home/hadoop/hadoopdata/hdfs/namenode został pomyślnie sformatowany. 2018-05-02 17: 52: 13 806 Info Namenode.FsimageFormatProtobuf: Zapisywanie pliku obrazu/home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.CKPT_0000000000000000000 Używając kompresji 2018-05-02 17: 52: 14 161 Info Namenode.FsimageFormatProtobuf: Plik obrazu/home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.CKPT_0000000000000000000 Rozmiar 391 bajtów zapisanych w 0 sekund . 2018-05-02 17: 52: 14 224 Info Namenode.NNSTORAGERETENTENT MANAGER: Zastosowanie 1 obrazów z txid> = 0 2018-05-02 17: 52: 14 282 Info Namenode.Namenode: supdown_msg: /*********************************************** ***************.0.1.1 ************************************************* ***********/
5. Rozpocznij klaster Hadoop
Zacznijmy twój klaster Hadoop przy użyciu skryptów dostarczanych przez Hadoop. Po prostu przejdź do swojego katalogu $ hadoop_home/sbin i wykonaj skrypty jeden po drugim.
cd $ hadoop_home/sbin/
Teraz biegnij start-DFS.cii scenariusz.
./start-DFS.cii
Przykładowy wyjście:
Rozpoczęcie nazwisk na [LocalHost] Uruchamianie danych Data rozpoczynającego nazwy wtórne [Tecadmin] 2018-05-02 18: 00: 32 565 ostrzegawcze.NativeCodeloader: Nie można załadować natywnej biblioteki hadoop
Teraz biegnij Start-Yarn.cii scenariusz.
./start-yarn.cii
Przykładowy wyjście:
Początek ResourceManager Początkowa godemanagers
6. Uzyskaj dostęp do usług Hadoop w przeglądarce
Hadoop Namenode rozpoczął się w porcie 9870 domyślnie. Uzyskaj dostęp do serwera na porcie 9870 w ulubionej przeglądarce internetowej.
http: // svr1.tecadmin.netto: 9870/
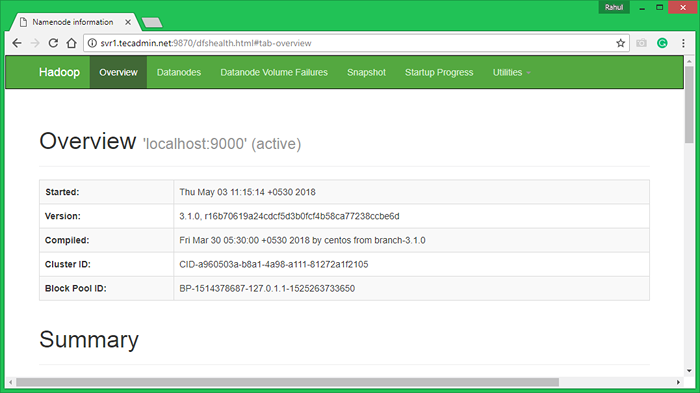
Teraz uzyskaj dostęp do portu 8042, aby uzyskać informacje o klastrze i wszystkich aplikacjach
http: // svr1.tecadmin.netto: 8042/
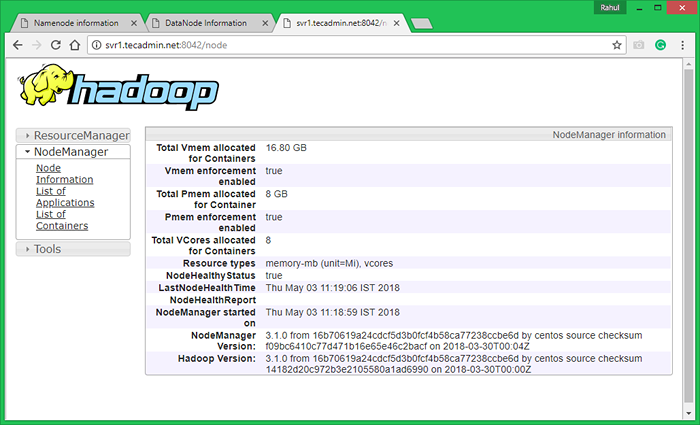
Dostęp do portu 9864, aby uzyskać szczegółowe informacje na temat węzła Hadoop.
http: // svr1.tecadmin.netto: 9864/
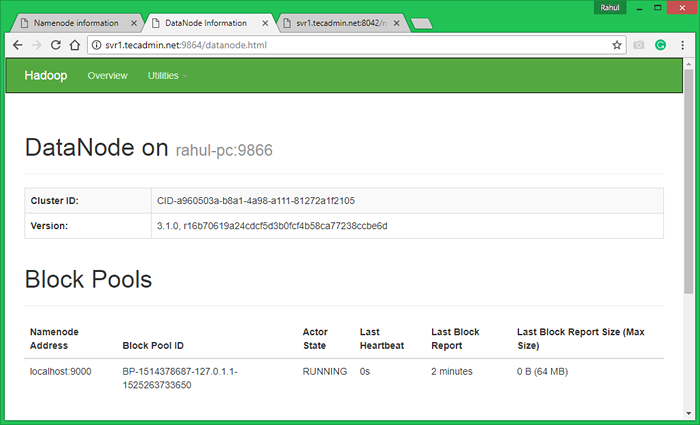
7. Test konfiguracji pojedynczego węzła Hadoop
7.1. Spraw, aby katalogi HDFS wymagane za pomocą następujących poleceń.
bin/hdfs dfs -mkdir/użytkownik bin/hdfs dfs -mkdir/użytkownik/hadoop
7.2. Skopiuj wszystkie pliki z lokalnego systemu plików/var/log/httpd do hadoop rozproszonego systemu plików za pomocą poniższego polecenia
bin/hdfs dfs -put/var/log/apache2 logs
7.3. Przeglądaj system plików rozproszony Hadoop, otwierając poniżej URL w przeglądarce. Zobaczysz folder Apache2 na liście. Kliknij nazwę folderu, aby otworzyć, a znajdziesz tam wszystkie pliki dziennika.
http: // svr1.tecadmin.Netto: 9870/Explorer.html#/user/hadoop/logs/
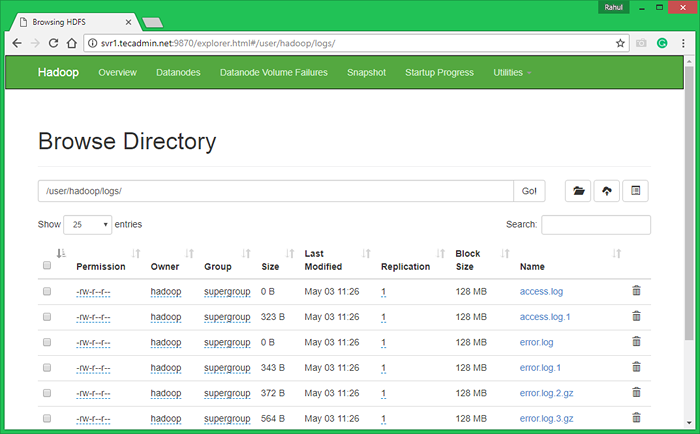
7.4 - Teraz kopiuj katalog dzienników dla Hadoop rozproszony system plików do lokalnego systemu plików.
bin/hdfs dfs -et logs/tmp/logs ls -l/tmp/logs/
Możesz także sprawdzić ten samouczek, aby uruchomić WordCount MapReduce EDMAT ZADANIA za pomocą wiersza poleceń.
- « 10 rzeczy do zrobienia po zainstalowaniu Ubuntu & Linux Mint
- Jak usunąć element tablicy JavaScript według wartości »