

Jak zainstalować i skonfigurować „CollectD” i „CollectD-WEB” do monitorowania zasobów serwerów w Linux

- 691
- 35
- Tomasz Szatkowski
Collectd-Web jest narzędziem monitorowania front-end opartego na RRDTool (ROund-RObin Database Narzędzie), który interpretuje i graficzne dane wyjściowe dane zebrane przez Zbieranie Usługa systemów Linux.
Zbieranie Usługa jest domyślnie jest domyślnie z ogromną kolekcją dostępnych wtyczek do domyślnego pliku konfiguracyjnego, niektóre z nich są domyślnie aktywowane po zainstalowaniu pakietu oprogramowania.
COLLETD-WEB CGI Skrypty, które interpretują i generują graficzną statystyki strony HTML, można po prostu wykonać przez Apache CGI brama z minimalnymi konfiguracją wymaganą po stronie serwera WWW Apache.
Jednak graficzny interfejs internetowy z wygenerowanymi statystykami może być również wykonywany przez samodzielny serwer WWW oferowany przez Python cgihttpserver skrypt, który jest wstępnie zainstalowany z głównym Git magazyn.
Ten samouczek obejmie proces instalacji Zbieranie usługa i Collectd-Web interfejs na RHEL/CENTOS/FEDORA I Ubuntu/Debian oparte na systemach z minimalnymi konfiguracją, które trzeba było wykonać w celu uruchamiania Usług i włączenia Zbieranie Wtyczka serwisowa.
Przejrzyj następujące artykuły Zbieranie seria.
Część 1: Zainstaluj i skonfiguruj „CollectD” i „Collectd-Web”, aby monitorować zasoby Linux Część 2: Monitoruj zasoby Linux za pomocą kolekcji WEB i Apache CGI Część 3: Skonfiguruj kolekcję jako centralny serwer monitorowania dla klientówKrok 1: - Zainstaluj usługę kolekcjonowania
1. Zasadniczo Zbieranie Zadaniem Daemon jest gromadzenie i przechowywanie statystyk danych w systemie, na którym działa. Zbieranie Pakiet można pobrać i zainstalować z domyślnych repozytoriów dystrybucji opartych na Debian, wydając następujące polecenie:
Na Ubuntu/Debian
# apt-get install collectd [on Debian systemy oparte]
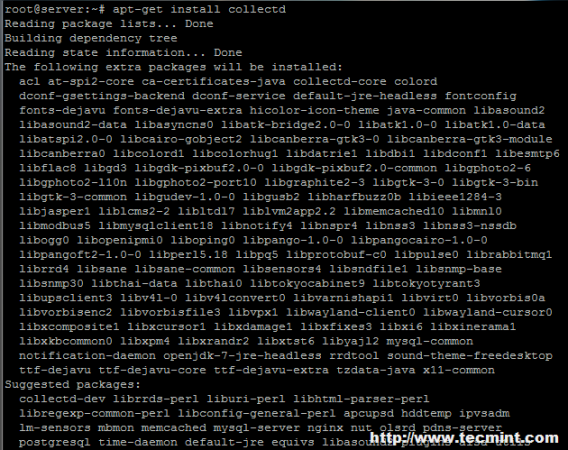 Zainstaluj kolekcję na Debian/Ubuntu
Zainstaluj kolekcję na Debian/Ubuntu Na RHEL/CENTOS 6.X/5.X
Na starszych Czerwony kapelusz systemy oparte na Centos/Fedora, Najpierw musisz włączyć repozytorium EPEL w swoim systemie, a następnie możesz zainstalować Zbieranie pakiet z repozytorium EPEL.
# mniam instalacja kolekcji
Na RHEL/CENTOS 7.X
O najnowszej wersji RHEL/CENTOS 7.x, możesz zainstalować i włączyć repozytorium EPEL z domyślnych repozytorium Yum, jak pokazano poniżej.
# Yum Instal Epel-Release # Yum Instaluj kolekcję
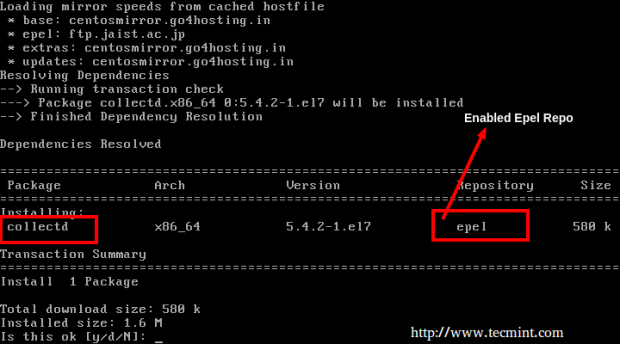 Zainstaluj Collectd na Centos/Rhel/Fedora
Zainstaluj Collectd na Centos/Rhel/Fedora Notatka: Dla użytkowników Fedory nie ma potrzeby włączania żadnych repozytoriów stron trzecich, proste mni.
2. Po zainstalowaniu pakietu w systemie uruchom poniższe polecenie, aby uruchomić usługę.
# usługa zbierania start [on Debian Systemy oparte] # usługa zbierania start [ON RHEL/CENTOS 6.X/5.X Systemy] # SystemCtl Start Collectd.usługa [on RHEL/CENTOS 7.X Systemy]
Krok 2: Zainstaluj kolekcję i zależności
3. Przed rozpoczęciem importowania Collectd-Web Git Repozytorium, najpierw musisz to zapewnić Git Pakiet oprogramowania i następujące wymagane zależności są instalowane na twoim komputerze:
----------------- NA Debian / Ubuntu Systemy ---------------- # apt-get instaluj git # apt-get instaluj librds-perl libJson-perl libhtml-parser-perl
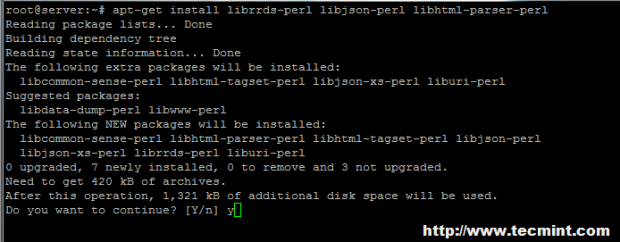 Zainstaluj Git na Debian/Ubuntu
Zainstaluj Git na Debian/Ubuntu ----------------- NA Redhat/Centos/Fedora Systemy oparte -------------- # Yum Zainstaluj git # yum instaluj rrdtool rrdtool-devel rrdtool-perl perl-html-parser perl-json
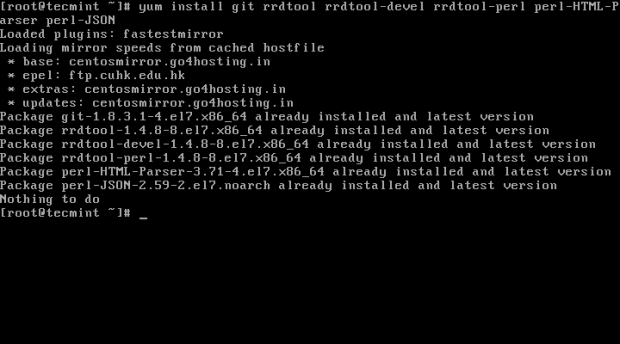 Zainstaluj git i zależności
Zainstaluj git i zależności Krok 3: Importuj Repozytorium Git-WEB i modyfikuj samodzielny serwer Python Server
4. W następnym kroku wybierz i zmień katalog na ścieżkę systemową z hierarchii drzew Linux, w której chcesz zaimportować projekt GIT (możesz użyć /usr/lokalny/ ścieżka), a następnie uruchom następujące polecenie, aby klon Collectd-Web Repozytorium GIT:
# cd/usr/local/ # git klon https: // github.com/httpdss/collectd-eB.git
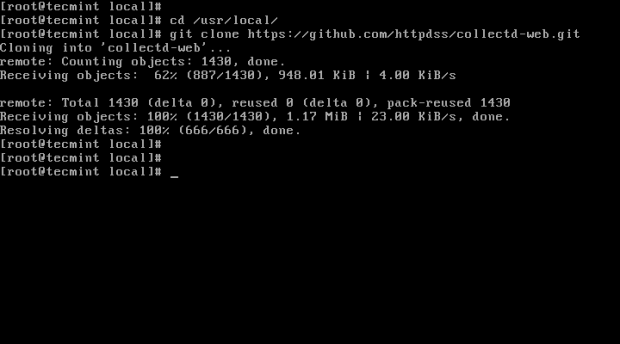 Git Clone Collectd-Web
Git Clone Collectd-Web 5. Po zaimportowaniu repozytorium GIT do systemu, idź dalej Collectd-Web katalog i wymień swoją zawartość w celu zidentyfikowania skryptu serwera Python (Runserver.py), który zostanie zmodyfikowany na następnym kroku. Dodaj także uprawnienia do wykonania do następującego skryptu CGI: Graphdefs.CGI.
# CD Collectd-Web/ # LS # CHMOD +X CGI-Bin/ GraphDefs.CGI
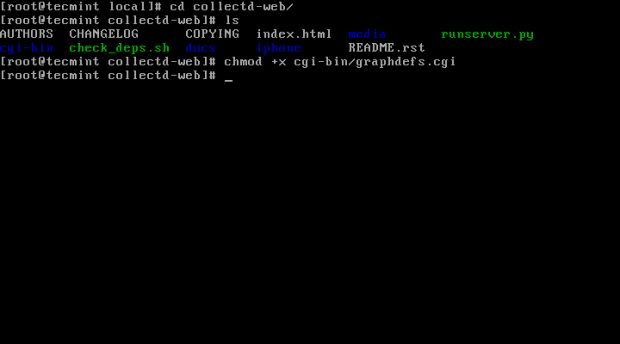 Ustaw uprawnienie Wykonaj
Ustaw uprawnienie Wykonaj 6. Collectd-Web Skrypt niezależnego serwera Python jest domyślnie skonfigurowany do uruchamiania i wiązania tylko Adres Loopback (127.0.0.1).
Aby uzyskać dostęp Collectd-Web interfejs z zdalnej przeglądarki, musisz edytować Runserver.py skryptu i zmień 127.0.1.1 ip Adresować do 0.0.0.0, Aby powiązać wszystkie interfejsy sieciowe adresy IP.
Jeśli chcesz powiązać tylko na określonym interfejsie, użyj tego adresu IP interfejsu (nie zalecane użycie tej opcji w przypadku, gdy adres interfejsu sieciowego jest dynamicznie przydzielany przez serwer DHCP). Użyj poniższego zrzutu ekranu jako fragmentu, w jaki sposób ostateczny Runserver.py Skrypt powinien wyglądać:
# Nano Runserver.py
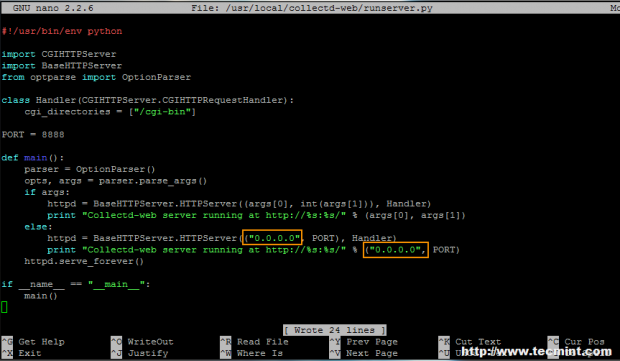 Skonfiguruj kolekcję-Web
Skonfiguruj kolekcję-Web Jeśli chcesz użyć innego portu sieciowego, niż 8888, Zmodyfikuj wartość zmiennej portu.
Krok 4: Uruchom Python CGI Standalone Server i przeglądaj interfejs kolekcjonowania WEB
7. Po zmodyfikowaniu samodzielnego wiązania adresu IP Skrypt Python Serwer Serwer, śmiało i rozpocznij serwer w tle, wydając następujące polecenie:
# ./runserver.py &
Opcjonalnie, jako alternatywna metoda, którą możesz wywołać interpreter Python, aby uruchomić serwer:
# Python Runserver.py &
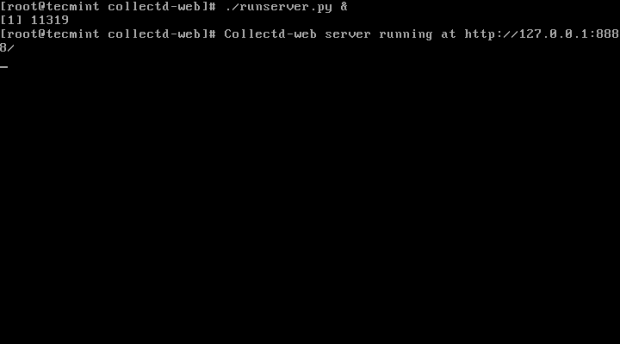 Rozpocznij zebranie stron serwerowych: 1 2
Rozpocznij zebranie stron serwerowych: 1 2
- « Skonfiguruj kolekcję jako centralny serwer monitorowania dla klientów
- AutOjump - zaawansowane polecenie „CD”, aby szybko poruszać system plików Linux »