

Jak zainstalować i skonfigurować Hadoop na Ubuntu 20.04

- 1927
- 41
- Juliusz Sienkiewicz
Hadoop to bezpłatne, oparte na open source i oparte na Javie ramy oprogramowania używane do przechowywania i przetwarzania dużych zestawów danych na klastrach maszyn. Wykorzystuje HDFS do przechowywania swoich danych i przetwarzania tych danych za pomocą MapReduce. Jest to ekosystem narzędzi dużych zbiorów danych, które są używane przede wszystkim do eksploracji danych i uczenia maszynowego.
Apache Hadoop 3.3 ma zauważalne ulepszenia i wiele poprawek błędów w poprzednich wydaniach. Ma cztery główne elementy, takie jak Hadoop Common, HDFS, przędza i MapReduce.
Ten samouczek wyjaśni, jak zainstalować i skonfigurować Apache Hadoop na Ubuntu 20.04 LTS Linux System.
Krok 1 - Instalowanie Java
Hadoop jest napisany w Javie i obsługuje tylko Java w wersji 8. Hadoop wersja 3.3 i najnowsze również obsługują czas wykonawczy Java 11, a także Java 8.
Możesz zainstalować OpenJDK 11 z domyślnych repozytoriów Apt:
Aktualizacja sudo aptsudo apt instint openjdk-11-jdk
Po zainstalowaniu zweryfikuj zainstalowaną wersję Java za pomocą następującego polecenia:
Java -version Powinieneś uzyskać następujące dane wyjściowe:
Wersja OpenJdk "11.0.11 "2021-04-20 Environme Runtime Environment (Build 11.0.11+9-ubuntu-0ubuntu2.20.04) Openjdk 64-bit serwer VM (kompilacja 11.0.11+9-ubuntu-0ubuntu2.20.04, tryb mieszany, udostępnianie)
Krok 2 - Utwórz użytkownika Hadoop
Dobrym pomysłem jest utworzenie osobnego użytkownika, aby uruchomić Hadoop ze względów bezpieczeństwa.
Uruchom następujące polecenie, aby utworzyć nowego użytkownika o nazwie Hadoop:
Sudo Adduser Hadoop Podaj i potwierdź nowe hasło, jak pokazano poniżej:
Dodanie użytkownika „Hadoop”… dodanie nowej grupy „Hadoop” (1002)… Dodanie nowego użytkownika „Hadoop” (1002) z grupą „Hadoop”… Tworzenie Direktory Home ”/Home/Hadoop”… kopiowanie plików z „/etc/skel” … Nowe hasło: Ponownie ponownie hasło: Passwd: Zaktualizowano hasło pomyślnie zmieniając informacje użytkownika do Hadoop Wpisz nową wartość lub naciśnij Enter, aby uzyskać domyślną nazwę []: Numer pokoju []: Work Phone []: Phone Phone []: Inne []: Czy informacje są prawidłowe? [Y/n] y
Krok 3 - Skonfiguruj uwierzytelnianie oparte na klawiszach SSH
Następnie musisz skonfigurować uwierzytelnianie SSH bez hasła dla systemu lokalnego.
Najpierw zmień użytkownika na Hadoop za pomocą następującego polecenia:
Su - Hadoop Następnie uruchom następujące polecenie, aby wygenerować pary kluczy publicznych i prywatnych:
SSH -KEYGEN -T RSA Zostaniesz poproszony o wprowadzenie nazwy pliku. Po prostu naciśnij Enter, aby ukończyć proces:
Generowanie publicznej/prywatnej pary kluczy RSA. Wprowadź plik, w którym można zapisać klucz (/home/hadoop/.SSH/ID_RSA): Utworzono katalog '/home/hadoop/.ssh '. Wprowadź hasło (pusta dla braku hasła): Wprowadź ponownie tę samą hasło: Twoja identyfikacja została zapisana w/home/hadoop/.ssh/id_rsa Twój klucz publiczny został zapisany w/home/hadoop/.ssh/id_rsa.Pub Kluczowy odcisk palca to: SHA256: QSA2SYEISWP0HD+UXXXI0J9MSORJKDGIBKFBM3EJYIK [PROJEKTOWANY OBECNICZNE KLUCZU to:+--- [RSA 3072] ----+|.+ |. |… Oo++.O | |. oo. B . |. | o… + o * . |. | = ++ O o s | |.++o+ o | |.+.+ + . O | | o . o * o . |. |. mi + . |. +---- [SHA256]-----+
Następnie dołącz wygenerowane klucze publiczne z ID_RSA.pub do autoryzowanych_keysów i ustal właściwe pozwolenie:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/autoryzowane_keysCHMOD 640 ~/.ssh/autoryzowane_keys
Następnie sprawdź uwierzytelnianie SSH bez hasła za pomocą następującego polecenia:
SSH Localhost Zostaniesz poproszony o uwierzytelnienie hostów poprzez dodanie kluczy RSA do znanych hostów. Wpisz tak i naciśnij Enter, aby uwierzytelnić Host Local:
Autentyczność lokalnego hosta (127.0.0.1) „Nie można ustalić. Kluczowy odcisk palca ECDSA to SHA256: JFQDVBM3ZTPHUPGD5OMJ4CLVIH6TZirz2GD3BDNQGMQ. Czy na pewno chcesz kontynuować łączenie (tak/nie/[odcisk palca])? Tak
Krok 4 - Instalowanie Hadoop
Najpierw zmień użytkownika na Hadoop za pomocą następującego polecenia:
Su - Hadoop Następnie pobierz najnowszą wersję Hadoop za pomocą polecenia WGET:
wget https: // pobieranie.Apache.org/hadoop/common/hadoop-3.3.0/Hadoop-3.3.0.smoła.GZ Po pobraniu wyodrębnij pobrany plik:
TAR -xVZF HADOOP -3.3.0.smoła.GZ Następnie zmień nazwę wyodrębnionego katalogu Hadoop:
MV Hadoop-3.3.0 Hadoop Następnie będziesz musiał skonfigurować zmienne środowiskowe Hadoop i Java w systemie.
Otworzyć ~/.Bashrc Plik w ulubionym edytorze tekstu:
nano ~/.Bashrc Dodaj poniższe wiersze do pliku. Można znaleźć lokalizację Java_Home, uruchamiając dirname $ (dirname $ (readLink -f $ (który java)))) polecenie na terminalu.
Eksport java_home =/usr/lib/jvm/java-11-openjdk-amd64 eksport hadoop_home =/home/hadoop/hadoop export hadoop_install = $ hadoop_home export hadoop_mapred_home = $ hadoop_home export hadoop_common_home = $ hadoop_home hadoop_hd_home = $ hadoop_home = $ hadoop_home export hadoop_common_home = $ hadoop_home Hadoop_home eksport hadoop_common_lib_native_dir = $ hadoop_home/lib/natywna ścieżka eksportu = $ ścieżka: $ hadoop_home/sbin: $ hadoop_home/bin eksport hadoop_opts = "-djava.biblioteka.ścieżka = $ hadoop_home/lib/Native "
Zapisz i zamknij plik. Następnie aktywuj zmienne środowiskowe za pomocą następującego polecenia:
Źródło ~/.Bashrc Następnie otwórz plik zmiennej środowiska Hadoop:
nano $ hadoop_home/etc/hadoop/hadoop-env.cii Ponownie ustaw Java_Home w środowisku Hadoop.
Eksport java_home =/usr/lib/jvm/java-11-openjdk-amd64
Zapisz i zamknij plik po zakończeniu.
Krok 5 - Konfigurowanie Hadoop
Najpierw musisz utworzyć katalogi Namenode i Datanode w katalogu Hadoop Home:
Uruchom następujące polecenie, aby utworzyć oba katalogi:
mkdir -p ~/hadoopdata/hdfs/namenodemkdir -p ~/hadoopdata/hdfs/datanode
Następnie edytuj Site Core.XML PLIK I Aktualizuj nazwę hosta systemu:
nano $ hadoop_home/etc/hadoop/rdzeń.XML Zmień następującą nazwę zgodnie z nazwą hosta systemu:
fs.Defaultfs hdfs: // hadoop.tecadmin.com: 9000| 123456 | fs.Defaultfs hdfs: // hadoop.tecadmin.com: 9000 |
Zapisz i zamknij plik. Następnie edytuj Site HDFS.XML plik:
nano $ hadoop_home/etc/hadoop/hdfs-witryna.XML Zmień ścieżkę katalogu Namenode i Datanode, jak pokazano poniżej:
DFS.Replikacja 1 DFS.nazwa.Dir Plik: /// home/hadoop/hadoopdata/hdfs/namenode dfs.dane.Plik dir: /// home/hadoop/hadoopdata/hdfs/dataanode| 1234567891011121314151617 | DFS.Replikacja 1 DFS.nazwa.Dir Plik: /// home/hadoop/hadoopdata/hdfs/namenode dfs.dane.Plik dir: /// home/hadoop/hadoopdata/hdfs/dataanode |
Zapisz i zamknij plik. Następnie edytuj Mapred.XML plik:
nano $ hadoop_home/etc/hadoop/mapred.XML Dokonaj następujących zmian:
MapReduce.struktura.Imię Parn| 123456 | MapReduce.struktura.Imię Parn |
Zapisz i zamknij plik. Następnie edytuj strona przędzy.XML plik:
nano $ hadoop_home/etc/hadoop/przędza.XML Dokonaj następujących zmian:
przędza.Nodemanager.Aux-Services MAPREDUCE_SHUFLE| 123456 | przędza.Nodemanager.Aux-Services MAPREDUCE_SHUFLE |
Zapisz i zamknij plik po zakończeniu.
Krok 6 - Rozpocznij klaster Hadoop
Przed rozpoczęciem klastra Hadoop. Będziesz musiał sformatować nazwy jako użytkownik Hadoop.
Uruchom następujące polecenie, aby sformatować nazwę hadoop:
HDFS Namenode -Format Powinieneś uzyskać następujące dane wyjściowe:
2020-11-23 10: 31: 51 318 Info Namenode.NnstorageretententionManager: Zachowaj 1 obrazy z txid> = 0 2020-11-23 10: 31: 51 323 Info Namenode.FSIMAGE: FSIMAGESAVER CZYSTA Punkt kontrolny: TXID = 0 Po zamknięciu. 2020-11-23 10: 31: 51 323 Info Namenode.Namenode: supdown_msg: /*********************************************** ***************.tecadmin.Net/127.0.1.1 ************************************************* ***********/
Po sformatowaniu nazwy, uruchom następujące polecenie, aby uruchomić klaster Hadoop:
start-DFS.cii Gdy HDFS zaczął pomyślnie, powinieneś uzyskać następujące dane wyjściowe:
Rozpoczynając nazwy na [Hadoop.tecadmin.com] hadoop.tecadmin.com: Ostrzeżenie: stale dodane „hadoop.tecadmin.Com, Fe80 :: 200: 2dff: Fe3a: 26CA%ETH0 '(ECDSA) do listy znanych gospodarzy. Rozpoczęcie datanodów Rozpoczynając wtórne nazwy [Hadoop.tecadmin.com]
Następnie uruchom usługę przędzy, jak pokazano poniżej:
Start-Yarn.cii Powinieneś uzyskać następujące dane wyjściowe:
Początek ResourceManager Początkowa godemanagers
Możesz teraz sprawdzić status wszystkich usług Hadoop za pomocą polecenia JPS:
JPS Powinieneś zobaczyć wszystkie uruchomione usługi przy następujących wyjściach:
18194 Namenode 18822 NodeManager 17911 SecondaryNamenode 17720 DataNode 18669 ResourceManager 19151 JPS
Krok 7 - Dostosuj zaporę ogniową
Hadoop zaczyna teraz i słucha na portach 9870 i 8088. Następnie będziesz musiał zezwolić na te porty przez zaporę ogniową.
Uruchom następujące polecenie, aby umożliwić połączenia Hadoop za pośrednictwem zapory:
Firewall-CMD --Permanent --add-port = 9870/tcpFirewall-CMD --Permanent --add-port = 8088/tcp
Następnie ponownie załaduj usługę zapory, aby zastosować zmiany:
Firewall-CMD-RELOOD Krok 8 - Dostęp Hadoop Namenode and Resource Manager
Aby uzyskać dostęp do nazwy, otwórz przeglądarkę internetową i odwiedź adres URL http: // Your-Server-IP: 9870. Powinieneś zobaczyć następujący ekran:
http: // hadoop.tecadmin.Net: 9870
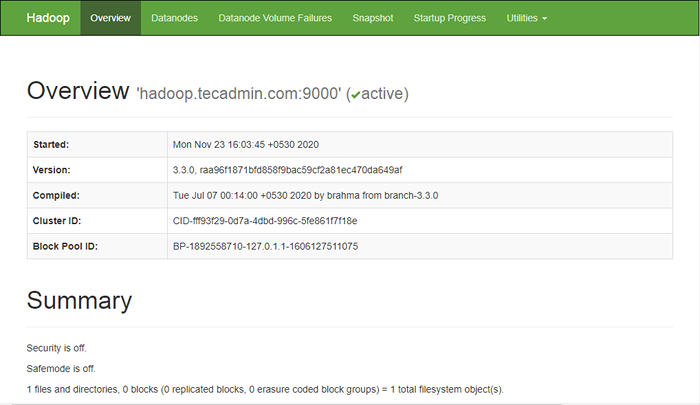
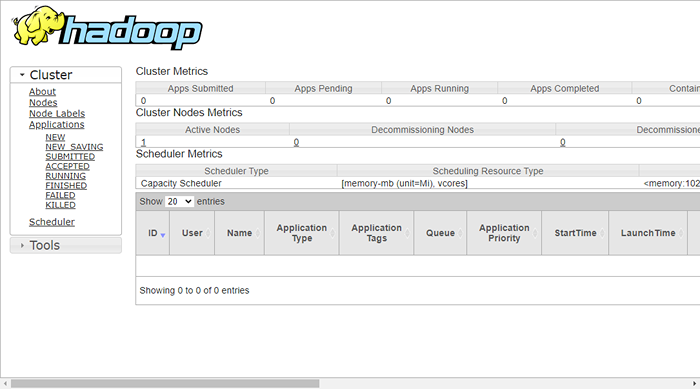
Aby uzyskać dostęp do zasobów, otwórz przeglądarkę internetową i odwiedź adres URL http: // Your-Server-IP: 8088. Powinieneś zobaczyć następujący ekran:
http: // hadoop.tecadmin.netto: 8088
Krok 9 - Sprawdź klaster Hadoop
W tym momencie klaster Hadoop jest zainstalowany i konfigurowany. Następnie utworzymy niektóre katalogi w systemie plików HDFS, aby przetestować Hadoop.
Utwórzmy niektóre katalogi w systemie plików HDFS za pomocą następującego polecenia:
HDFS DFS -MKDIR /TEST1HDFS dfs -mkdir /logs
Następnie uruchom następujące polecenie, aby wymienić powyższy katalog:
HDFS DFS -LS / Powinieneś uzyskać następujące dane wyjściowe:
Znaleziono 3 pozycje DRWXR-XR-X-Hadoop Supergroup 0 2020-11-23 10:56 /Logs Drwxr-Xr-X-Hadoop Supergroup 0 2020-11-23 10:51 /TEST1
Umieść także niektóre pliki do systemu plików Hadoop. Na przykład umieszczanie plików dziennika z komputera hosta do systemu plików Hadoop.
HDFS dfs -put/var/log/*/logs/ Możesz także zweryfikować powyższe pliki i katalog w interfejsie internetowym Hadoop Namenode.
Przejdź do interfejsu internetowego Namenode, kliknij narzędzia => Przeglądaj system plików. Powinieneś zobaczyć swoje katalogi, które stworzyłeś wcześniej na poniższym ekranie:
http: // hadoop.tecadmin.Netto: 9870/Explorer.html
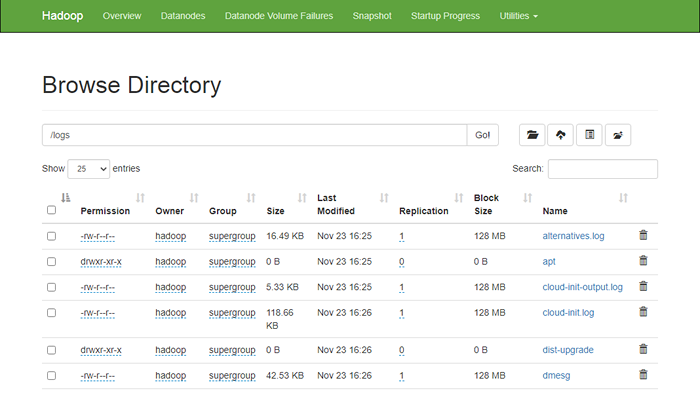
Krok 10 - Zatrzymaj klaster Hadoop
Możesz także zatrzymać usługę nazwy i przędzy Hadoop w dowolnym momencie, uruchamiając stop-DFS.cii I Stop-Yarn.cii skrypt jako użytkownik Hadoop.
Aby zatrzymać usługę Namenode Hadoop, uruchom następujące polecenie jako użytkownik Hadoop:
stop-DFS.cii Aby zatrzymać usługę Hadoop Resource Manager, uruchom następujące polecenie:
Stop-Yarn.cii Wniosek
Ten samouczek wyjaśnił ci samouczek krok po kroku, aby zainstalować i skonfigurować Hadoop na Ubuntu 20.04 System Linux.