

Jak zainstalować i skonfigurować Apache Spark na Ubuntu/Debian

- 1142
- 26
- Pan Jeremiasz Więcek
Apache Spark to rozproszone ramy obliczeniowe rozproszone na otwartym poziomie, które są tworzone w celu zapewnienia szybszych wyników obliczeniowych. Jest to silnik obliczeniowy w pamięci, co oznacza, że dane będą przetwarzane w pamięci.
Iskra Obsługuje różne interfejsy API do przesyłania strumieniowego, przetwarzania wykresów, SQL, Mllib. Obsługuje także Javę, Python, Scala i R jako preferowane języki. Spark jest głównie instalowany w klastrach Hadoop, ale można również zainstalować i skonfigurować Spark w trybie samodzielnym.
W tym artykule będziemy zobaczyć, jak zainstalować Apache Spark W Debian I Ubuntu-rozkłady oparte na oparciu.
Zainstaluj Java i Scala w Ubuntu
Żeby zainstalować Apache Spark W Ubuntu musisz mieć Jawa I Scala zainstalowane na twoim komputerze. Większość nowoczesnych dystrybucji ma domyślnie zainstalowane Java i możesz je zweryfikować za pomocą następującego polecenia.
$ java -version
 Sprawdź wersję Java w Ubuntu
Sprawdź wersję Java w Ubuntu Jeśli nie ma wyjścia, możesz zainstalować Java za pomocą naszego artykułu na temat instalacji Java na Ubuntu lub po prostu uruchom następujące polecenia, aby zainstalować Java na dystrybucjach Ubuntu i Debian.
$ sudo apt aktualizacja $ sudo apt instontuj default -jre $ java -version
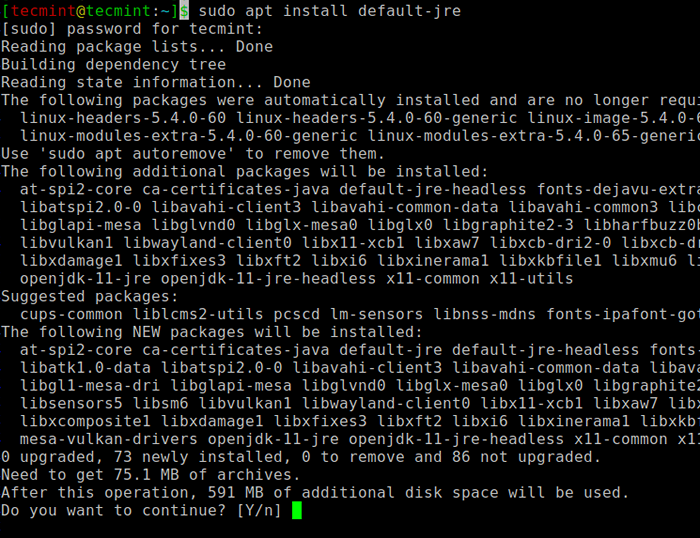 Zainstaluj Java w Ubuntu
Zainstaluj Java w Ubuntu Następnie możesz zainstalować Scala z repozytorium apt, uruchamiając następujące polecenia, aby wyszukać Scala i zainstalować.
$ sudo appt wyszukiwanie skala ⇒ Wyszukaj pakiet $ sudo apt instal instaluj scala ⇒ zainstaluj pakiet
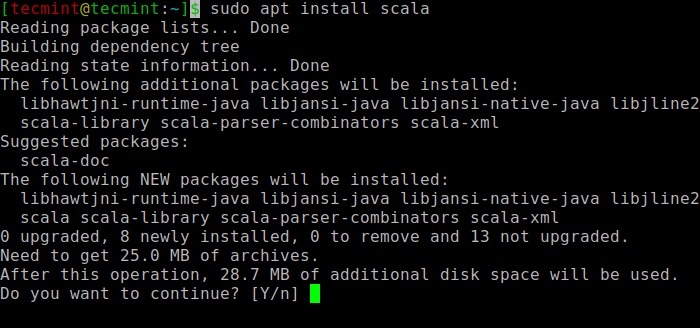 Zainstaluj Scala w Ubuntu
Zainstaluj Scala w Ubuntu Aby zweryfikować instalację Scala, Uruchom następujące polecenie.
$ scala -version Scala Code Runner Wersja 2.11.12-Copyright 2002-2017, lampa/EPFL
Zainstaluj Apache Spark w Ubuntu
Teraz przejdź do oficjalnej strony pobierania Apache Spark i weź najnowszą wersję (i.mi. 3.1.1) W momencie pisania tego artykułu. Alternatywnie możesz użyć polecenia WGET, aby pobrać plik bezpośrednio w terminalu.
$ wget https: // apachemirror.Wuchna.COM/Spark/Spark-3.1.1/Spark-3.1.1-bin-hadoop2.7.TGZ
Teraz otwórz swój terminal i przełącz się tam, gdzie umieszczony jest plik pobrany i uruchom następujące polecenie, aby wyodrębnić plik smar Apache Spark.
$ tar -xvzf Spark -3.1.1-bin-hadoop2.7.TGZ
Na koniec przenieś wyodrębnione Iskra katalog do /optować informator.
$ sudo mv spark-3.1.1-bin-hadoop2.7 /Opt /Spark
Skonfiguruj zmienne środowiskowe dla Spark
Teraz musisz ustawić kilka zmiennych środowiskowych w swoim .profil Plik przed uruchomieniem iskry.
$ echo "Export spark_home =/opt/spark" >> ~/.Profil $ echo "Export Path = $ ścieżka:/opt/spark/bin:/opt/spark/sbin" >> ~/.Profil $ echo "Export PYSPARK_PYTHON =/usr/bin/Python3" >> ~/.profil
Aby upewnić się, że te nowe zmienne środowiskowe są osiągalne w skorupce i dostępne dla Apache Spark, obowiązkowe jest również uruchomienie następującego polecenia, aby wprowadzić ostatnie zmiany w efekcie.
$ źródło ~/.profil
Wszystkie binaria związane z iskrą na początek i zatrzymanie usług są pod sbin teczka.
$ ls -l /opt /iskar
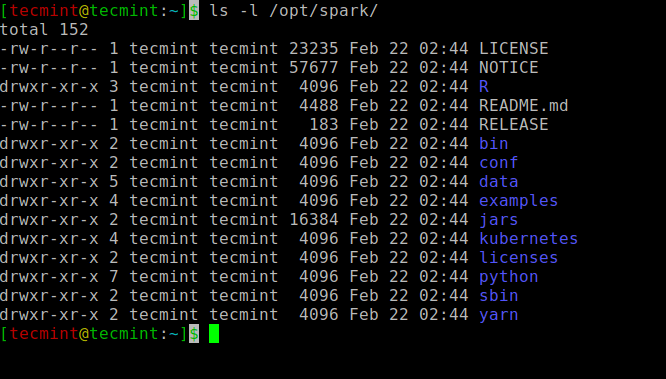 Spark binaria
Spark binaria Rozpocznij Apache Spark w Ubuntu
Uruchom następujące polecenie, aby rozpocząć Iskra Służba główna i usługa niewolników.
$ start-master.SH $ Start-Workers.SH Spark: // Localhost: 7077
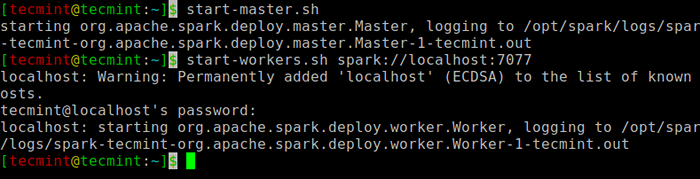 Rozpocznij usługę Spark
Rozpocznij usługę Spark Po uruchomieniu usługi przejdź do przeglądarki i wpisz następującą stronę Spark dostępu do URL. Na stronie możesz zobaczyć,.
http: // localhost: 8080/lub http: // 127.0.0.1: 8080
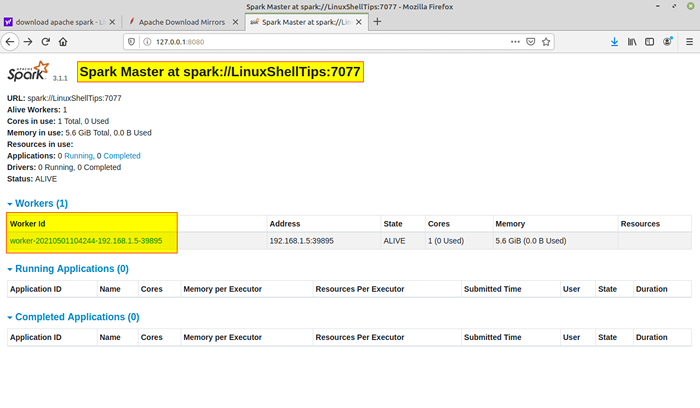 Spark Web Strona
Spark Web Strona Możesz także sprawdzić, czy Spar-Shell działa dobrze, uruchamiając Spar-Shell Komenda.
$ Spark-Shell
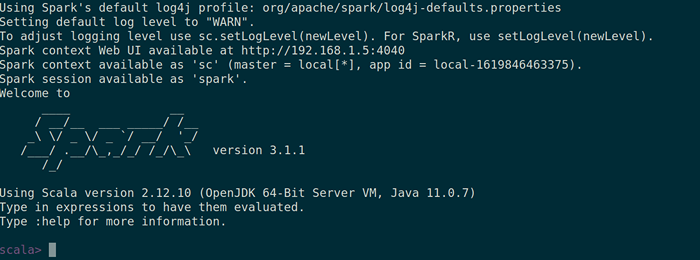 Spark Shell
Spark Shell To wszystko dla tego artykułu. Wkrótce złapiemy Cię kolejnym interesującym artykułem.
- « LFCA Poznaj koszty w chmurze i budżetowanie - część 16
- Jak monitorować serwer Linux i przetwarzać wskaźniki z przeglądarki »