

Jak zainstalować Apache Hadoop na Ubuntu 22.04

- 3586
- 573
- Maurycy Napierała
Zrozumienie nieustrukturyzowanych danych i analiza ogromnych ilości danych to dziś inna gra w piłkę. I tak firmy uciekły się do Apache Hadoop i innych powiązanych technologii w celu bardziej efektywnego zarządzania nieustrukturyzowanymi danymi. Nie tylko firmy, ale także osoby fizyczne używają Apache Hadoop do różnych celów, takich jak analiza dużych zestawów danych lub tworzenie strony internetowej, która może przetwarzać zapytania użytkowników. Jednak instalacja Apache Hadoop na Ubuntu może wydawać się trudnym zadaniem dla użytkowników nowych w świecie serwerów Linux. Na szczęście nie musisz być doświadczonym administratorem systemu, aby zainstalować Apache Hadoop na Ubuntu.
Poniższy przewodnik instalacji krok po kroku przejdzie przez cały proces od pobierania oprogramowania do konfigurowania serwera. W tym artykule wyjaśnimy, jak zainstalować Apache Hadoop na Ubuntu 22.System 04 LTS. Można to również użyć do innych wersji Ubuntu.
Krok 1: Zainstaluj zestaw programowy Java
Java jest niezbędnym elementem Apache Hadoop, więc musisz pobrać i zainstalować zestaw programistyczny Java na wszystkich węzłach w sieci, w której Hadoop zostanie zainstalowany. Możesz pobrać JRE lub JDK. Jeśli chcesz tylko uruchomić Hadoop, to JRE jest wystarczający, ale jeśli chcesz utworzyć aplikacje działające na Hadoop, musisz zainstalować JDK. Najnowsza wersja Java, którą obsługuje Hadoop, to Java 8 i 11. Możesz zweryfikować to na stronie Apache i pobrać odpowiednią wersję Java w zależności od systemu operacyjnego.
- Domyślne repozytoria Ubuntu zawierają Java 8 i Java 11. Użyj następującego polecenia, aby je zainstalować.
sudo apt aktualizacja && sudo apt Zainstaluj openjdk-11-jdk - Po pomyślnym zainstalowaniu sprawdź bieżącą wersję Java:
Java -version Sprawdź wersję Java
Sprawdź wersję Java - Lokalizacja katalogu Java_Home można znaleźć, uruchamiając następujące polecenie. To będzie wymagane najnowsze w tym artykule.
dirname $ (dirname $ (readLink -f $ (który java)))) Sprawdź lokalizację java_home
Sprawdź lokalizację java_home
Krok 2: Utwórz użytkownika dla Hadoop
Wszystkie komponenty Hadoop będą działać jako użytkownik, który tworzysz dla Apache Hadoop, a użytkownik będzie również używany do logowania się do interfejsu internetowego Hadoopa. Możesz utworzyć nowe konto użytkownika za pomocą polecenia „sudo” lub możesz utworzyć konto użytkownika z uprawnieniami „root”. Konto użytkownika z uprawnieniami root jest bezpieczniejsze, ale może nie być tak wygodne dla użytkowników, którzy nie są zaznajomieni z wierszem poleceń.
- Uruchom następujące polecenie, aby utworzyć nowego użytkownika o nazwie „Hadoop”:
Sudo Adduser Hadoop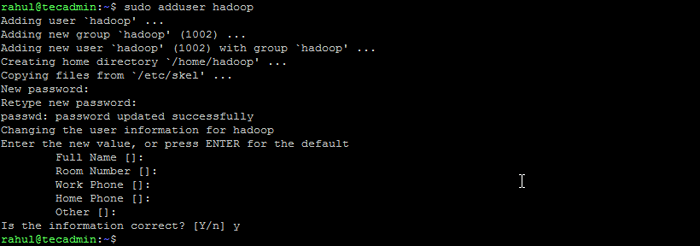 Utwórz użytkownika Hadoop
Utwórz użytkownika Hadoop - Przełącz się na nowo utworzony użytkownik Hadoop:
Su - Hadoop - Teraz skonfiguruj dostęp bez hasła SSH dla nowo utworzonego użytkownika Hadoop. Najpierw wygeneruj klawiaturę SSH:
SSH -KEYGEN -T RSA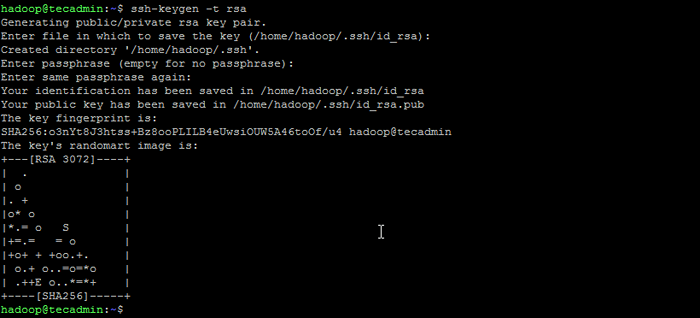 Wygeneruj parę kluczy SSH
Wygeneruj parę kluczy SSH - Skopiuj wygenerowany klucz publiczny do autoryzowanego pliku klucza i ustaw odpowiednie uprawnienia:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/autoryzowane_keysCHMOD 640 ~/.ssh/autoryzowane_keys - Teraz spróbuj ssh do lokalnego hostu.
SSH LocalhostZostaniesz poproszony o uwierzytelnienie hostów poprzez dodanie kluczy RSA do znanych hostów. Wpisz tak i naciśnij Enter, aby uwierzytelnić Host Local:
 Połącz SSH do LocalHost
Połącz SSH do LocalHost
Krok 3: Zainstaluj Hadoop na Ubuntu
Po zainstalowaniu Java możesz pobrać Apache Hadoop i wszystkie jego powiązane komponenty, w tym Hive, Pig, Sqoop itp. Najnowszą wersję można znaleźć na oficjalnej stronie pobierania Hadoopa. Pobierz archiwum binarne (nie źródło).
- Użyj następującego polecenia, aby pobrać Hadoop 3.3.4:
wget https: // dlcdn.Apache.org/hadoop/common/hadoop-3.3.4/Hadoop-3.3.4.smoła.GZ - Po pobraniu pliku możesz go rozpakować do folderu na dysku twardym.
TAR XZF HADOOP-3.3.4.smoła.GZ - Zmień nazwę wyodrębnionego folderu, aby usunąć informacje o wersji. Jest to opcjonalny krok, ale jeśli nie chcesz zmienić nazwy, dostosuj pozostałe ścieżki konfiguracyjne.
MV Hadoop-3.3.4 Hadoop - Następnie będziesz musiał skonfigurować zmienne środowiskowe Hadoop i Java w systemie. Otwórz ~/.plik bashrc w ulubionym edytorze tekstu:
nano ~/.BashrcDodaj poniższe wiersze do pliku. Można znaleźć lokalizację Java_Home, uruchamiając
Eksport java_home =/usr/lib/jvm/java-11-openjdk-amd64 eksport hadoop_home =/home/hadoop/hadoop export hadoop_install = $ hadoop_home export hadoop_mapred_home = $ hadoop_home export hadoop_common_home = $ hadoop_home hadoop_hd_home = $ hadoop_home = $ hadoop_home export hadoop_common_home = $ hadoop_home Hadoop_home eksport hadoop_common_lib_native_dir = $ hadoop_home/lib/natywna ścieżka eksportu = $ ścieżka: $ hadoop_home/sbin: $ hadoop_home/bin eksport hadoop_opts = "-djava.biblioteka.ścieżka = $ hadoop_home/lib/Native "dirname $ (dirname $ (readLink -f $ (który java))))polecenie na terminalu.12345678910 export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64export HADOOP_HOME=/home/hadoop/hadoopexport HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport HADOOP_YARN_HOME=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/ Lib/NativeExport Path = $ ścieżka: $ hadoop_home/sbin: $ hadoop_home/binexport hadoop_opts = "-djava.biblioteka.ścieżka = $ hadoop_home/lib/Native " Zapisz plik i zamknij go.
- Załaduj powyższą konfigurację w bieżącym środowisku.
Źródło ~/.Bashrc - Musisz także skonfigurować Java_home W Hadoop-env.cii plik. Edytuj plik zmiennej środowiska Hadoop w edytorze tekstu:
nano $ hadoop_home/etc/hadoop/hadoop-env.ciiWyszukaj „eksport java_home” i skonfiguruj go z wartością znalezioną w kroku 1. Zobacz poniższy zrzut ekranu:
 Ustaw java_home
Ustaw java_homeZapisz plik i zamknij go.
Krok 4: Konfigurowanie Hadoop
Następnie jest skonfigurowanie plików konfiguracyjnych Hadoop dostępnych w katalogu ETC.
- Najpierw będziesz musiał stworzyć Namenode I DataNode katalogi w katalogu domu użytkownika Hadoop użytkownika. Uruchom następujące polecenie, aby utworzyć oba katalogi:
mkdir -p ~/hadoopdata/hdfs/Namenode, Datanode - Następnie edytuj Site Core.XML PLIK I Aktualizuj nazwę hosta systemu:
nano $ hadoop_home/etc/hadoop/rdzeń.XMLZmień następującą nazwę zgodnie z nazwą hosta systemu:
fs.Defaultfs HDFS: // LocalHost: 9000123456 fs.Defaultfs HDFS: // LocalHost: 9000 Zapisz i zamknij plik.
- Następnie edytuj Site HDFS.XML plik:
nano $ hadoop_home/etc/hadoop/hdfs-witryna.XMLZmień ścieżki katalogu Namenode i Datanode, jak pokazano poniżej:
DFS.Replikacja 1 DFS.nazwa.Dir Plik: /// home/hadoop/hadoopdata/hdfs/namenode dfs.dane.Plik dir: /// home/hadoop/hadoopdata/hdfs/dataanode12345678910111213141516 DFS.Replikacja 1 DFS.nazwa.Dir Plik: /// home/hadoop/hadoopdata/hdfs/namenode dfs.dane.Plik dir: /// home/hadoop/hadoopdata/hdfs/dataanode Zapisz i zamknij plik.
- Następnie edytuj Mapred.XML plik:
nano $ hadoop_home/etc/hadoop/mapred.XMLDokonaj następujących zmian:
MapReduce.struktura.Imię Parn123456 MapReduce.struktura.Imię Parn Zapisz i zamknij plik.
- Następnie edytuj strona przędzy.XML plik:
nano $ hadoop_home/etc/hadoop/przędza.XMLDokonaj następujących zmian:
przędza.Nodemanager.Aux-Services MAPREDUCE_SHUFLE123456 przędza.Nodemanager.Aux-Services MAPREDUCE_SHUFLE Zapisz plik i zamknij go.
Krok 5: Rozpocznij klaster Hadoop
Przed rozpoczęciem klastra Hadoop. Będziesz musiał sformatować nazwy jako użytkownik Hadoop.
- Uruchom następujące polecenie, aby sformatować nazwę hadoop:
HDFS Namenode -FormatPo pomyślnym sformatowaniu katalogu Namenode za pomocą systemu plików HDFS zobaczysz wiadomość „Directory Storage/Home/Hadoop/Hadoopdata/HDFS/Namenode został pomyślnie sformatowany".
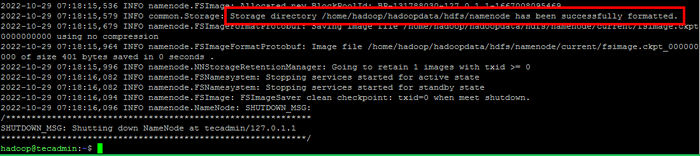 Formatuj nazewniowy
Formatuj nazewniowy - Następnie rozpocznij klaster Hadoop z następującym poleceniem.
start-all.cii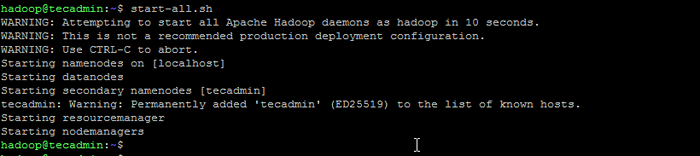 Rozpocznij usługi Hadoop
Rozpocznij usługi Hadoop - Po rozpoczęciu wszystkich usług możesz uzyskać dostęp do Hadoop pod adresem: http: // localhost: 9870

- A strona aplikacji Hadoop jest dostępna na stronie http: // localhost: 8088

Wniosek
Instalowanie Apache Hadoop na Ubuntu może być trudnym zadaniem dla początkujących, szczególnie jeśli postępują zgodnie z instrukcjami w dokumentacji. Na szczęście ten artykuł zawiera przewodnik krok po kroku, który pomoże ci z łatwością zainstalować Apache Hadoop na Ubuntu. Wszystko, co musisz zrobić, to postępować zgodnie z instrukcjami wymienionymi w tym artykule i możesz być pewien, że instalacja Hadoop będzie uruchomiona w krótkim czasie.