

Jak zainstalować Apache Kafka na Ubuntu 22.04

- 3120
- 712
- Klaudia Woś
Apache Kafka to open source, rozproszona platforma strumieniowego zdarzeń opracowana przez Apache Software Foundation. Jest to napisane w językach programowania Scali i Java. Możesz zainstalować Kafkę na dowolnej platformie obsługującej język programowania Java.
Ten samouczek zawiera instrukcje krok po kroku w celu zainstalowania Apache Kafka na Ubuntu 22.04 LTS Linux System. Nauczysz się także tworzyć tematy w Kafka i uruchomić producent i węzły konsumenckie.
Wymagania wstępne
Musisz mieć uprzywilejowane konto dostęp do Ubuntu 22.04 System Linux.
Krok 1 - Instalowanie Java
Możemy uruchomić serwer Apache Kafka w systemach, które obsługują Java. Upewnij się, że w systemie Ubuntu zainstalowano Java.
Użyj następujących poleceń, aby zainstalować OpenJDK w systemie Ubuntu z oficjalnych repozytoriów.
Aktualizacja sudo aptsudo apt zainstaluj domyślne-jdk
Sprawdź aktualną aktywną wersję Java.
java --version Wyjście: wersja OpenJdk "11.0.15 "2022-04-19 Environme Runtime Environment (Build 11.0.15+10-ubuntu-0ubuntu0.22.04.1) Openjdk 64-bitowy serwer VM (kompilacja 11.0.15+10-ubuntu-0ubuntu0.22.04.1, tryb mieszany, udostępnianie)
Krok 2 - Pobierz najnowszą Apache Kafka
Możesz pobrać najnowsze pliki binarne Apache Kafka z oficjalnej strony pobierania. Alternativali możesz pobrać Kafka 3.2.0 z poniższym poleceniem.
wget https: // dlcdn.Apache.org/kafka/3.2.0/kafka_2.13-3.2.0.TGZ Następnie wyodrębnij pobrany plik archiwum i umieść je pod /USR/Local/Kafka informator.
TAR XZF KAFKA_2.13-3.2.0.TGZsudo mv kafka_2.13-3.2.0/usr/local/kafka
Krok 3 - Utwórz Systemd Scripts Startup
Teraz utwórz pliki jednostek systemowych dla usług Zookeeper i Kafka. To pomoże ci w łatwy sposób uruchomić/zatrzymać usługę Kafka.
Najpierw utwórz plik jednostki SystemD dla Zookeeper:
sudo nano/etc/systemd/system/zookeeper.praca I dodaj następującą zawartość:
[Jednostka] Opis = Apache Zookeeper Server Dokumentacja = http: // Zookeeper.Apache.org wymaga = sieć.celowe zdalne fs.Target po = sieć.celowe zdalne fs.Target [Service] Type = Simple ExecStart =/usr/local/kafka/bin/zookeeper-server-start.sh/usr/local/kafka/config/zookeeper.Właściwości execstop =/usr/local/kafka/bin/zookeeper-server-stop.SH RESTART = on-Abnormal [instalacja] Wantedby = Multi-User.cel
Zapisz plik i zamknij go.
Następnie utwórz plik jednostki SystemD dla usługi Kafka:
sudo nano/etc/systemd/system/kafka.praca Dodaj poniższą zawartość. Pamiętaj, aby ustawić poprawne Java_home ścieżka zgodnie z instalacją Java w twoim systemie.
[Jednostka] Opis = Apache Kafka Server Documentation = http: // kafka.Apache.org/dokumentacja.html wymaga = Zookeeper.Service [Service] Type = proste środowisko = "java_home =/usr/lib/jvm/java-11-openjdk-amd64" execStart =/usr/kafka/bin/kafka-server-start.sh/usr/local/kafka/config/serwer.Właściwości execstop =/usr/local/kafka/bin/kafka-server-stop.sh [instalacja] WantedBy = Multi-użytkownik.cel
Zapisz plik i zamknij.
Załaduj demona systemu, aby zastosować nowe zmiany.
Sudo Systemctl Demon-Reload To ponownie załaduje wszystkie pliki SystemD w środowisku systemowym.
Krok 4 - Rozpocznij usługi Zookeeper i Kafka
Rozpocznijmy obie usługi jeden po drugim. Najpierw musisz założyć usługę Zookeeper, a następnie uruchomić Kafkę. Użyj polecenia SystemCtl, aby uruchomić instancję Zookeeper z pojedynczym węzłem.
sudo systemctl start zookeepersudo systemctl start kafka
Sprawdź oba status usług:
Sudo SystemCtl Status ZookeeperSUDO Systemctl Status Kafka
Otóż to. Pomyślnie zainstalowałeś serwer Apache Kafka na Ubuntu 22.04 System. Następnie utworzymy tematy na serwerze Kafka.
Krok 5 - Utwórz temat w Kafka
Kafka zapewnia na nim wiele wstępnie zbudowanego skryptu powłoki. Najpierw utwórz temat o nazwie „TestTopic” z pojedynczą partycją z jedną repliką:
CD/USR/Local/KafkaBin/Kafka-Topics.sh-Create-bootstrap-server localhost: 9092-Odreplikacja-fakt 1-działki 1-Topic Testtopic
Wyjście utworzone w tematyce Testtopic.
Tutaj:
- Używać
--tworzyćopcja utworzenia nowego tematu -
--współczynnik replikacjiopisuje, ile kopii danych zostanie utworzonych. Gdy działa z jednym instancją, zachowaj tę wartość 1. - Ustaw
--partycjeopcje jako liczbę brokerów, które chcesz podzielić dane. Gdy działa z jednym brokerem, zachowaj tę wartość 1. -
--tematZdefiniuj nazwę tematu
Możesz tworzyć wiele tematów, uruchamiając to samo polecenie jak powyżej. Następnie możesz zobaczyć utworzone tematy na Kafce za pomocą komendy uruchomionego poniżej:
Bin/Kafka-Topics.sh--list-bootstrap-server localhost: 9092 Wyjście wygląda jak poniższy zrzut ekranu:
 Lista tematów Kafka
Lista tematów KafkaAlternatywnie, zamiast ręcznego tworzenia tematy.
Krok 6 - Wyślij i odbieraj wiadomości w Kafka
„Producent” to proces odpowiedzialny za umieszczanie danych w naszej Kafce. Kafka jest wyposażona w klienta wiersza poleceń, który przyjmie dane wejściowe z pliku lub ze standardowego wejścia i wyśle go jako wiadomości do klastra Kafka. Domyślna Kafka wysyła każdą wiersz jako osobną wiadomość.
Uruchommy producent, a następnie wpiszmy kilka wiadomości do konsoli, aby wysłać na serwer.
Bin/Kafka-Consol-Producer.SH-Broker-List LocalHost: 9092-Topic Testtopic > Witaj w Kafka> To jest mój pierwszy temat> Możesz wyjść z tego polecenia lub utrzymać ten terminal w celu dalszego testowania. Teraz otwórz nowy terminal do procesu konsumenckiego Kafka na następnym kroku.
Kafka ma również konsumenta z wiersza poleceń do odczytu danych z klastra Kafka i wyświetlanie komunikatów do standardowego wyjścia.
Bin/Kafka-Console-Consumer.sh-bootstrap-server localhost: 9092-Topic Testtopic-z-beginning Witaj w Kafka, to mój pierwszy temat Teraz, jeśli nadal prowadzisz producent Kafka w innym terminalu. Po prostu wpisz trochę tekstu na tym terminalu producenta. Będzie to natychmiast widoczne na terminalu konsumenckim. Zobacz poniższy zrzut ekranu producenta i konsumenta Kafka w pracy:
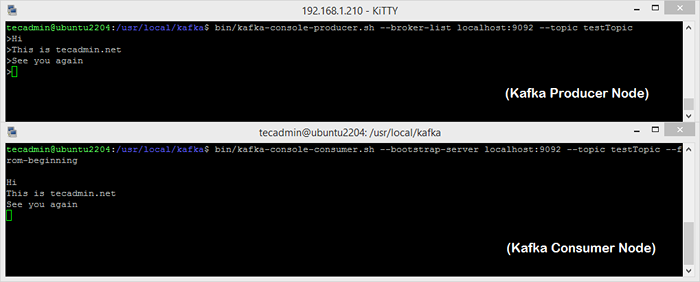 Uruchamianie producenta Apache Kafka i węzła konsumenckiego
Uruchamianie producenta Apache Kafka i węzła konsumenckiegoWniosek
Ten samouczek pomógł ci zainstalować i skonfigurować serwer Apache Kafka na Ubuntu 22.04 System Linux. Dodatkowo nauczyłeś się tworzyć nowy temat na serwerze Kafka i uruchomić przykładowy proces produkcji i konsumentów z Apache Kafka.