

Jak zainstalować klaster ElasticSearch (Multi Node) na Centos/Rhel, Ubuntu & Debian

- 4563
- 1478
- Maria Piwowarczyk
ElasticSearch jest elastyczne i potężne open source, rozproszonym wyszukiwaniem w czasie rzeczywistym i silnikiem analitycznym. Korzystając z prostego zestawu interfejsów API, zapewnia możliwość wyszukiwania pełnotekstowego. Wyszukiwanie elastyczne jest bezpłatnie dostępne na podstawie licencji Apache 2, co zapewnia największą elastyczność.
Ten artykuł pomoże Ci w konfigurowaniu klastra Elasticearch Multi Węzły w Centos, Rhel, Ubuntu i Debian Systems. W Elasticsearch Multi Node Cluster po prostu konfiguruje wiele klastrów pojedynczych węzłów o tej samej nazwie klastra w tej samej sieci.
Scenerio sieciowe
Mamy trzy serwer z następującymi IPS i nazwami hostów. Cały serwer działają w tym samym sieci LAN i mają pełny dostęp do siebie serwer za pomocą IP i nazwy hosta obu.
192.168.10.101 Node_1 192.168.10.102 Node_2 192.168.10.103 Node_3
Sprawdź Java (wszystkie węzły)
Java jest głównym wymogiem instalacji ElasticSearch. Upewnij się, że masz zainstalowane Java na wszystkich węzłach.
# Java -version Java wersja „1.8.0_31 "Java (TM) SE Środowisko środowiskowe (kompilacja 1.8.0_31-B13) Java Hotspot (TM) 64-bitowy serwer VM (kompilacja 25.31-B07, tryb mieszany)
Jeśli nie masz zainstalowanej Java w żadnym systemie węzłów, użyj jednego z następujących linków, aby go najpierw zainstalować.
Zainstaluj Java 8 na Centos/RHEL 7/6/5
Zainstaluj Java 8 na Ubuntu
Pobierz ElasticSearch (wszystkie węzły)
Teraz pobierz najnowsze archiwum ElasticSearch na wszystkich systemach węzłów z oficjalnej strony pobierania. W chwili ostatniej aktualizacji tego artykułu ElasticSearch 1.4.2 wersja to najnowsza wersja dostępna do pobrania. Użyj następującego polecenia, aby pobrać ElasticSearch 1.4.2.
$ wget https: // pobierz.ElasticSearch.org/elasticsearch/elasticsearch/elasticsearch-1.4.2.smoła.GZ
Teraz wyodrębnij ElasticSearch na wszystkich systemach węzłów.
$ TAR XZF ELASTICSEARCH-1.4.2.smoła.GZ
Skonfiguruj ElasticSearch
Teraz musimy skonfigurować elasticsearch na wszystkich systemach węzłów. ElasticSearch używa „ElasticSearch” jako domyślnej nazwy klastra. Zalecamy zmianę go zgodnie z rozmową z nazewnictwem.
$ mv ElasticSearch-1.4.2/usr/share/elasticsearch $ cd/usr/share/elasticsearch
Aby zmienić klaster o nazwie Edytuj config/elasticsearch.yml Plik w każdym węźle i aktualizuj następujące wartości. Nazwy węzłów są dynamicznie generowane, ale aby zachować stałą przyjazną nazwę nazwę.
Na Node_1
Edytuj konfigurację klastra klastra ElasticSearch na Node_1 (192.168.10.101) system.
$ vim config/elasticSearch.yml
grupa.Nazwa: węzeł TecadMincluster.Nazwa: „Node_1”
Na Node_2
Edytuj konfigurację klastra klastra ElasticSearch na Node_2 (192.168.10.102) system.
$ vim config/elasticSearch.yml
grupa.Nazwa: węzeł TecadMincluster.Nazwa: „Node_2”
Na Node_3
Edytuj konfigurację klastra klastra ElasticSearch na Node_3 (192.168.10.103) system.
$ vim config/elasticSearch.yml
grupa.Nazwa: węzeł TecadMincluster.Nazwa: „Node_3”
Zainstaluj wtyczkę Elasticearch-Head (wszystkie węzły)
ElasticSearch-Head to interfejs internetowy do przeglądania i interakcji z elastycznym klastrem wyszukiwania. Użyj następującego polecenia, aby zainstalować tę wtyczkę we wszystkich systemach węzłów.
$ bin/wtyczka-install mobz/elasticsearch-head
Rozpoczęcie klastra ElasticSearch (wszystkie węzły)
W miarę zakończenia konfiguracji klastra ElasticSearch. Niech uruchom klaster elasticsearch za pomocą następującego polecenia we wszystkich węzłach.
$ ./bin/elasticsearch &
Domyślnie ElasticSerch słuchaj na porcie 9200 i 9300. Więc połącz się z Node_1 Na porcie 9200, takim jak następujący adres URL, zobaczysz wszystkie trzy węzły w klastrze.
http: // node_1: 9200/_plugin/head/
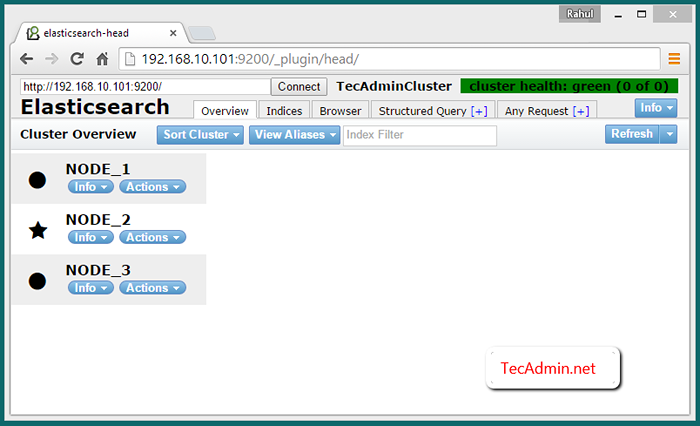
Sprawdź klaster wielu węzłów
Aby sprawdzić, czy klaster działa poprawnie. Włóż niektóre dane w jednym węźle, a jeśli te same dane są dostępne w innych węzłach, oznacza to, że klaster działa poprawnie.
Wstaw dane na Node_1
Aby zweryfikować klaster Utwórz wiadro w Node_1 i dodaj kilka danych.
$ curl -xput http: // node_1: 9200/mybucket $ curl -xput 'http: // node_1: 9200/mybucket/user/rahul' -d '"name": "Rahul Kumar"'
$ curl -xput 'http: // node_1: 9200/mybucket/post/1' -d '„użytkownik”: „rahul”, „postdate”: „01-16-2015”, „body”: „Dodawanie danych” W klastrze ElasticSearch ”,„ Title ”:„ ElasticSearch Claster Test ” '
Wyszukaj dane na wszystkich węzłach
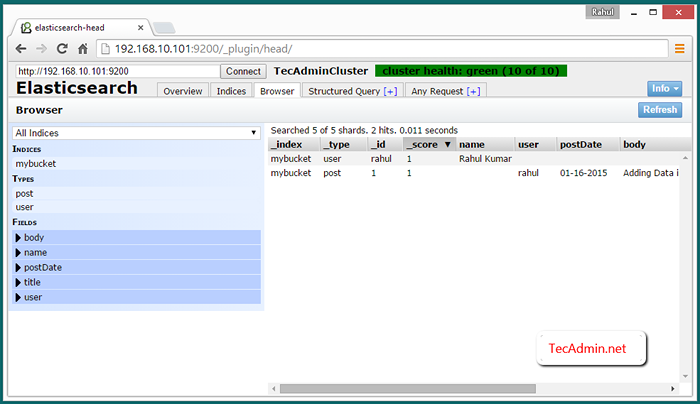
Teraz przeszukaj te same dane z Node_2 I Node_3 i sprawdź, czy te same dane są replikowane do innych węzłów klastra. Zgodnie z powyższymi poleceniami utworzyliśmy użytkownika o imieniu Rahul i dodaliśmy tam niektóre dane. Użyj więc następujących poleceń do wyszukiwania danych powiązanych z użytkownikiem Rahul.
$ curl 'http: // node_1: 9200/mybucket/post/_search?q = użytkownik: Rahul & Pretty = true '$ curl' http: // node_2: 9200/mybucket/post/_search?q = użytkownik: Rahul & Pretty = true '$ curl' http: // node_3: 9200/mybucket/post/_search?Q = użytkownik: Rahul & Pretty = True '
I otrzymasz wyniki coś w rodzaju poniżej dla wszystkich powyższych poleceń.
„wziął”: 69, „timed_out”: false, „_Shards”: „Total”: 5, „Success”: 5, „nieudany”: 0, „Hits”: „Total”: 1, „Max_Score ": 1.0, „Hits”: [„_INDEX”: „MYBUCKET”, „_TYPE”: „Post”, „_id”: „1”, „_score”: 1.0, „_Source”: „User”: „Rahul”, „PostDate”: „01-16-2015”, „Body”: „Dodawanie danych w klastrze ElasticSearch”, „Title”: „Test klastra ElastiCearch” ]
Wyświetl dane klastra w przeglądarce internetowej
Aby wyświetlić dane na temat ElasticSearch Cluster Dostęp do wtyczki Elasticsearch-Head za pomocą jednego z IP klastrowych na poniżej URL. Następnie kliknij Przeglądarka patka.
http: // node_1: 9200/_plugin/head/
- « Jak korzystać z polecenia SystemCtl do zarządzania usługami SystemD
- Dodanie dodatkowego EPEL repozytorium i REMI do systemu opartego na REL »