

Jak zainstalować Hadoop na RHEL 8 / Centos 8 Linux
- 750
- 188
- Juliusz Sienkiewicz
Apache Hadoop to struktura typu open source używana do pamięci rozproszonej, a także rozproszone przetwarzanie dużych zbiorów danych na temat klastrów komputerów, które działają na twardości towarowej. Hadoop przechowuje dane w Hadoop rozproszonym systemie plików (HDFS), a przetwarzanie tych danych odbywa się za pomocą MapReduce. Przędza zapewnia API do żądania i przydzielania zasobów w klastrze Hadoop.
Framework Apache Hadoop składa się z następujących modułów:
- Hadoop Common
- Hadoop rozproszony system plików (HDFS)
- PRZĘDZA
- MapReduce
W tym artykule wyjaśniono, jak zainstalować Hadoop wersję 2 w RHEL 8 lub Centos 8. Zainstalujemy HDFS (Namenode i DataNode), Yarn, MapReduce w klastrze pojedynczego węzła w trybie Pseudo rozproszonym, który jest rozproszony symulacja na jednym komputerze. Każdy demon Hadoop, taki jak HDFS, przędza, mapier. będzie działał jako osobny/indywidualny proces Java.
W tym samouczku nauczysz się:
- Jak dodać użytkowników do środowiska Hadoop
- Jak zainstalować i skonfigurować Oracle JDK
- Jak skonfigurować SSH bez hasła
- Jak zainstalować Hadoop i skonfigurować niezbędne powiązane pliki XML
- Jak rozpocząć klaster Hadoop
- Jak uzyskać dostęp do interfejsu internetowego Namenode i ResourceManager
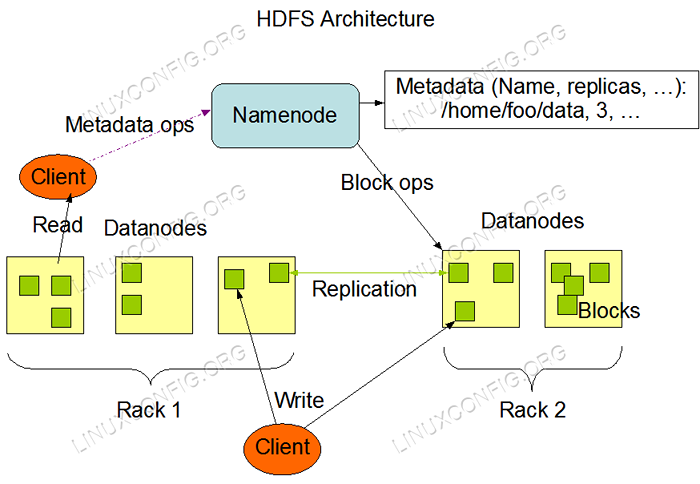
Architektura HDFS. Zastosowane wymagania i konwencje oprogramowania
| Kategoria | Wymagania, konwencje lub wersja oprogramowania |
|---|---|
| System | RHEL 8 / CENTOS 8 |
| Oprogramowanie | Hadoop 2.8.5, Oracle JDK 1.8 |
| Inny | Uprzywilejowany dostęp do systemu Linux jako root lub za pośrednictwem sudo Komenda. |
| Konwencje | # - Wymaga, aby podane polecenia Linux są wykonywane z uprawnieniami root bezpośrednio jako użytkownik root lub za pomocą sudo Komenda$ - Wymaga, aby podane polecenia Linux zostały wykonane jako zwykły użytkownik niepewny |
Dodaj użytkowników środowiska Hadoop
Utwórz nowego użytkownika i grupę za pomocą polecenia:
# useradd Hadoop # Passwd Hadoop
[root@hadoop ~]# useradd hadoop [root@hadoop ~]# passwd hadoop zmienia hasło dla użytkownika Hadoop. Nowe hasło: Ponownie przestawić nowe hasło: Passwd: Wszystkie tokeny uwierzytelniania zostały pomyślnie zaktualizowane. [root@hadoop ~]# cat /etc /passwd | Grep Hadoop Hadoop: x: 1000: 1000 ::/home/hadoop:/bin/bash
Zainstaluj i skonfiguruj Oracle JDK
Pobierz i zainstaluj JDK-8U202-Linux-X64.Oficjalny pakiet RPM w celu zainstalowania Oracle JDK.
[root@hadoop ~]# rpm -ivh jdk-8U202-Linux-x64.OSTRZEŻENIE RPM: JDK-8U202-Linux-X64.RPM: Nagłówek V3 RSA/SHA256 Podpis, Klucz ID EC551F03: NoKey Verifying… ############################### [ 100%] Przygotowanie… ########################################################.8-2000: 1.8.0_202-fcs ########################################### 00%] rozpakowywanie plików słoików… Narzędzia.słoik… wtyczka.Jar… Javaws.słoik… rozmieścić.słoik… rt.słoik… jsse.Jar… Charsety.słoik… lokocedata.słoik…
Po instalacji w celu sprawdzenia Java została pomyślnie skonfigurowana, uruchom następujące polecenia:
[root@hadoop ~]# java -version Java wersja "1.8.0_202 "Java (TM) SE Środowisko środowiskowe (kompilacja 1.8.0_202-B08) Java Hotspot (TM) 64-bitowy serwer VM (kompilacja 25.202-B08, tryb miksowany) [root@hadoop ~]# aktualizacja-alternatives-config java Jest 1 program, który zapewnia „java”. Polecenie wyboru ------------------------------------------- * + 1/usr/java/jdk1.8.0_202-AMD64/JRE/BIN/Java
Skonfiguruj SSH bez hasła
Zainstaluj otwarty serwer SSH i otwórz klienta SSH lub jeśli już zainstalowano, wyświetla poniższe pakiety.
[root@hadoop ~]# rpm -qa | Grep Openssh* OpenSsh-Server-7.8p1-3.El8.x86_64 OpenSsl-libs-1.1.1-6.El8.x86_64 OpenSSL-1.1.1-6.El8.x86_64 OpenSsh-Clients-7.8p1-3.El8.x86_64 OpenSSH-7.8p1-3.El8.x86_64 OpenSSL-PKCS11-0.4.8-2.El8.x86_64
Generuj pary kluczy publicznych i prywatnych z następującym poleceniem. Terminal będzie monitowany o wprowadzenie nazwy pliku. Naciskać WCHODZIĆ i postępuj. Po tym skopiowaniu formularza kluczy publicznych id_rsa.pub Do autoryzowane_keys.
$ ssh -keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/autoryzowane_keys $ chmod 640 ~/.ssh/autoryzowane_keys
[hadoop@hadoop ~] $ ssh -keygen -t RSA generowanie publicznej/prywatnej pary kluczy RSA. Wprowadź plik, w którym można zapisać klucz (/home/hadoop/.SSH/ID_RSA): Utworzono katalog '/home/hadoop/.ssh '. Wprowadź hasło (pusta dla braku hasła): Wprowadź ponownie tę samą hasło: Twoja identyfikacja została zapisana w/home/hadoop/.ssh/id_rsa. Twój klucz publiczny został zapisany w/Home/Hadoop/.ssh/id_rsa.pub. Kluczowy odcisk palca to: SHA256: H+LLPKAJJDD7B0F0JE/NFJRP5/FUEJSWMMZPJFXOELG [email protected] Losowy obraz klucza to: +--- [RSA 2048] ---- +|… ++*o .O | |. O… +.O.+o.+|. |. +… * +Oo == | | . O o . mi .oo | | . = .S.* O | | . o.O = O | |… O | | .o. |. |. o+. |. + ---- [SHA256] -----+ [hadoop@hadoop ~] $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/autoryzowane_keys [hadoop@hadoop ~] $ chmod 640 ~/.ssh/autoryzowane_keys
Sprawdź konfigurację SSH bez hasła za pomocą polecenia:
$ ssh
[hadoop@hadoop ~] $ ssh hadoop.Sandbox.Com Console Web: https: // hadoop.Sandbox.com: 9090/lub https: // 192.168.1.108: 9090/ Ostatni logowanie: Sobota 13 kwietnia 12:09:55 2019 [hadoop@hadoop ~] $
Zainstaluj hadoop i skonfiguruj powiązane pliki XML
Pobierz i wyodrębnij Hadoop 2.8.5 z oficjalnej strony internetowej Apache.
# wget https: // archiwum.Apache.org/dist/hadoop/common/hadoop-2.8.5/Hadoop-2.8.5.smoła.GZ # TAR -XZVF HADOOP -2.8.5.smoła.GZ
[root@rhel8-sandbox ~]# wget https: // archiwum.Apache.org/dist/hadoop/common/hadoop-2.8.5/Hadoop-2.8.5.smoła.GZ-2019-04-13 11: 14: 03-- https: // archiwum.Apache.org/dist/hadoop/common/hadoop-2.8.5/Hadoop-2.8.5.smoła.GZ rozwiązuje archiwum.Apache.org (archiwum.Apache.org)… 163.172.17.199 łączenie się z archiwum.Apache.org (archiwum.Apache.org) | 163.172.17.199 |: 443… Połączone. Wysłane żądanie HTTP, czekając na odpowiedź… 200 OK Długość: 246543928 (235 m) [Aplikacja/X-GZIP] Oszczędzanie na: „Hadoop-2.8.5.smoła.GZ 'Hadoop-2.8.5.smoła.GZ 100%[======================================================================== ======================================>] 235.12m 1.47 MB/s w 2M 53S 2019-04-13 11:16:57 (1.36 MB/s) - „Hadoop -2.8.5.smoła.GZ „uratował [246543928/246543928]
Konfigurowanie zmiennych środowiskowych
Edytuj Bashrc Dla użytkownika Hadoop poprzez konfigurowanie następujących zmiennych środowiskowych Hadoop:
Eksport hadoop_home =/home/hadoop/hadoop-2.8.5 Eksportuj hadoop_install = $ hadoop_home eksport hadoop_mapred_home = $ hadoop_home eksport hadoop_common_home = $ hadoop_home eksport hadoop_hdfs_home = $ hadoop_home export yarn_home = $ hadoop_home export hadoop_common_lib_native_dir = $ hadoop_home/lib/lib/$ export export export $ = export export $/$ hadoop_ hadoop_ hadoop_ hadoop_ hadoops export pather = export thast/lib/$ export thast = export thast/ Eksport Hadoop_Opts = "-Djava.biblioteka.ścieżka = $ hadoop_home/lib/Native " Źródło .Bashrc W bieżącej sesji logowania.
$ źródło ~/.Bashrc
Edytuj Hadoop-env.cii plik, który jest w /etc/hadoop wewnątrz katalogu instalacji Hadoop i dokonaj następujących zmian i sprawdź, czy chcesz zmienić inne konfiguracje.
Eksport java_home = $ java_home:-"/usr/java/jdk1.8.0_202-AMD64 " Eksport Hadoop_conf_dir = $ Hadoop_conf_dir:-"/home/hadoop/hadoop-2.8.5/etc/hadoop " Zmiany konfiguracji w witrynie rdzeniowym.plik XML
Edytuj Site Core.XML z vim lub możesz użyć dowolnego z redaktorów. Plik jest poniżej /etc/hadoop wewnątrz Hadoop Directory Home i dodaj następujące wpisy.
fs.defaultfs hdfs: // hadoop.Sandbox.com: 9000 Hadoop.TMP.reż /home/hadoop/hadooptmpdata Ponadto utwórz katalog poniżej Hadoop Folder domowy.
$ mkdir hadooptmpdata
Zmiany konfiguracji w witrynie HDFS.plik XML
Edytuj Site HDFS.XML który jest obecny w tej samej lokalizacji i.mi /etc/hadoop wewnątrz Hadoop katalog instalacyjny i utwórz Namenode/DataNode katalogi pod Hadoop Katalog domów użytkownika.
$ mkdir -p hdfs/namenode $ mkdir -p hdfs/datanode
DFS.Replikacja 1 DFS.nazwa.reż Plik: /// home/hadoop/hdfs/namenode DFS.dane.reż Plik: /// home/hadoop/hdfs/datanode Zmiany konfiguracyjne w witrynie Mapred.plik XML
Skopiuj Mapred.XML z Mapred.XML.szablon za pomocą CP polecenie, a następnie edytuj Mapred.XML położone w /etc/hadoop pod Hadoop Directory inpnelation z następującymi zmianami.
$ CP Mapred Site.XML.szablon Mapred-Site.XML
MapReduce.struktura.nazwa przędza Zmiany konfiguracji w witrynie przędzy.plik XML
Edytować strona przędzy.XML z następującymi wpisami.
MapReduceyarn.Nodemanager.Usługi aux MAPREDUCE_SHUFLE Rozpoczynając klaster Hadoop
Sformatuj nazanodę przed użyciem go po raz pierwszy. Jak użytkownik Hadoop uruchamia poniższe polecenie, aby sformatować nazwy mienod.
$ hdfs namenode -Format
[hadoop@hadoop ~] $ hdfs namenode -Format 19/04/13 11:54:10 Info Namenode.Namenode: startup_msg: /*********************************************** *************Gł.Sandbox.com/192.168.1.108 startup_msg: args = [-format] startup_msg: wersja = 2.8.5 19/04/13 11:54:17 Info Namenode.FSNamesystem: DFS.Namenode.tryb bezpieczeństwa.próg-pct = 0.9990000128746033 19/04/13 11:54:17 Info Namenode.FSNamesystem: DFS.Namenode.tryb bezpieczeństwa.min.DataNodes = 0 19/04/13 11:54:17 Info Namenode.FSNamesystem: DFS.Namenode.tryb bezpieczeństwa.rozszerzenie = 30000 19/04/13 11:54:18 Metryki informacji.Topmetrics: Nntop Conf: DFS.Namenode.szczyt.okno.num.wiadra = 10 19/04/13 11:54:18 Metryki informacji.Topmetrics: Nntop Conf: DFS.Namenode.szczyt.num.Użytkownicy = 10 19/04/13 11:54:18 Metryki informacji.Topmetrics: Nntop Conf: DFS.Namenode.szczyt.okna.minuty = 1,5,25 19/04/13 11:54:18 Info Namenode.FsnameSystem: Retry pamięć podręczna na nazwa jest włączona 19/04/13 11:54:18 Info Namenode.FSNameSystem: Retry Cache użyje 0.03 Całkowita sterta i ponowna pamięć podręczna Wejście Wejścia wynosi 600000 młynów 19/04/13 11:54:18 Info Util.GSET: Pojemność obliczeniowa dla mapa nazwaonoderetriccache 19/04/13 11:54:18 Info Util.GSET: typ VM = 64-bitowy 19/04/13 11:54:18 Info Util.GSet: 0.02999999329447746% MAX MAME 966.7 MB = 297.0 kb 19/04/13 11:54:18 Info Util.GSET: Pojemność = 2^15 = 32768 wpisów 19/04/13 11:54:18 Info Namenode.FSIMAGE: Przydzielony nowy blokpoolid: BP-415167234-192.168.1.108-1555142058167 19/04/13 11:54:18 Info Wspólne.Pamięć: katalog pamięci/home/hadoop/hdfs/namenode został pomyślnie sformatowany. 19/04/13 11:54:18 Info Namenode.FsimageformatProtobuf: Zapisywanie pliku obrazu/home/hadoop/hdfs/namenode/current/fsimage.CKPT_0000000000000000000 Używając kompresji 19/04/13 11:54:18 Info Namenode.FsimageFormatProtobuf: Plik obrazu/home/hadoop/hdfs/namenode/current/fsimage.CKPT_0000000000000000000 wielkości 323 bajtów zapisanych w 0 sekund. 19/04/13 11:54:18 Info Namenode.NnstorageTention Manager: Zachowaj 1 obrazy z txid> = 0 19/04/13 11:54:18 Info Util.EXITUTIL: Wyjście ze statusem 0 19/04/13 11:54:18 Info Namenode.Namenode: supdown_msg: /*********************************************** ***************.Sandbox.com/192.168.1.108 *************************************************** ***********/
Po sformatowaniu nazwy, a następnie uruchom HDFS za pomocą start-DFS.cii scenariusz.
$ start-dfs.cii
[hadoop@hadoop ~] $ start-dfs.sh rozpoczynają nazenody na [Hadoop.Sandbox.com] hadoop.Sandbox.com: Uruchamianie nazwy, logowanie do/home/hadoop/hadoop-2.8.5/Logs/Hadoop-Hadoop-Namenode-Hadoop.Sandbox.com.Out Hadoop.Sandbox.Com: Uruchamianie danych, logowanie do/home/hadoop/hadoop-2.8.5/logs/hadoop-hadoop-datanode-hadoop.Sandbox.com.Uruchamianie wtórnych mianod [0.0.0.0] Autentyczność hosta '0.0.0.0 (0.0.0.0) „Nie można ustalić. Kluczowy odcisk palca Ecdsa to SHA256: E+NFCEK/KVNIGNWDHGFVIKHJBWWWHIIJJKFJYGR7NKI. Czy na pewno chcesz kontynuować łączenie (tak/nie)? Tak 0.0.0.0: Ostrzeżenie: stale dodane „0.0.0.0 '(ECDSA) do listy znanych gospodarzy. [email protected]ło 0: 0.0.0.0: Uruchamianie SecondaryNamenode, logowanie do/Home/Hadoop/Hadoop-2.8.5/Logs/Hadoop-Hadoop-Secondarynamenode-Hadoop.Sandbox.com.na zewnątrz
Aby uruchomić usługi przędzy, musisz wykonać skrypt początkowy przędzy i.mi. Start-Yarn.cii
$ start-yarn.cii
[hadoop@hadoop ~] $ start-yarn.SH Start Yarn Demons Uruchamianie ResourceManager, logowanie do/Home/Hadoop/Hadoop-2.8.5/logs/przędza-hadoop-resourcemanager-hadoop.Sandbox.com.Out Hadoop.Sandbox.com: początek godemanager, logowanie do/home/hadoop/hadoop-2.8.5/logs/przędza-hadoop-nodemanager-hadoop.Sandbox.com.na zewnątrz
Aby sprawdzić, czy wszystkie usługi/demony Hadoop zostały uruchomione z powodzeniem, możesz użyć JPS Komenda.
$ JPS 2033 Namenode 2340 SecondaryNamenode 2566 ResourceManager 2983 JPS 2139 DataNode 2671 NodeManager
Teraz możemy sprawdzić bieżącą wersję Hadoop, której możesz użyć poniżej polecenia:
Wersja $ Hadoop
Lub
Wersja $ HDFS
[hadoop@hadoop ~] $ hadoop wersja Hadoop 2.8.5 Subversion https: // GIT-WIP-US.Apache.org/repo/asf/hadoop.GIT -R 0B8464D75227FCEE2C6E7F2410377B3D53D3D5F8 Opracowany przez JDU w dniu 2018-09-10T03: 32Z opracowany z protokcją 2.5.0 ze źródła z Sumą kontrolną 9942CA5C745417C14E318835F420733 To polecenie zostało uruchomione za pomocą/Home/Hadoop/Hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.JAR [hadoop@hadoop ~] $ hdfs wersja Hadoop 2.8.5 Subversion https: // GIT-WIP-US.Apache.org/repo/asf/hadoop.GIT -R 0B8464D75227FCEE2C6E7F2410377B3D53D3D5F8 Opracowany przez JDU w dniu 2018-09-10T03: 32Z opracowany z protokcją 2.5.0 ze źródła z Sumą kontrolną 9942CA5C745417C14E318835F420733 To polecenie zostało uruchomione za pomocą/Home/Hadoop/Hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.słoik [hadoop@hadoop ~] $
Interfejs wiersza poleceń HDFS
Aby uzyskać dostęp do HDF i utworzyć niektóre katalogi DFS, możesz użyć HDFS CLI.
$ hdfs dfs -mkdir /testData $ hdfs dfs -mkdir /hadoopdata $ hdfs dfs -ls /
[hadoop@hadoop ~] $ hdfs dfs -ls / znalezione 2 pozycje drwxr-xr-x-hadoop supergroup 0 2019-04-13 11:58 / hadoopdata drwxr-xr-x-hadoop supergroup 0 2019-04-13 11: 59 /testData
Uzyskaj dostęp do nazwy i przędzy z przeglądarki
Możesz uzyskać dostęp zarówno do interfejsu internetowego dla Namenode, jak i Menedżer zasobów przędzy za pośrednictwem dowolnej przeglądarki, takiej jak Google Chrome/Mozilla Firefox.
Namenode Web interfejs - http: //: 50070
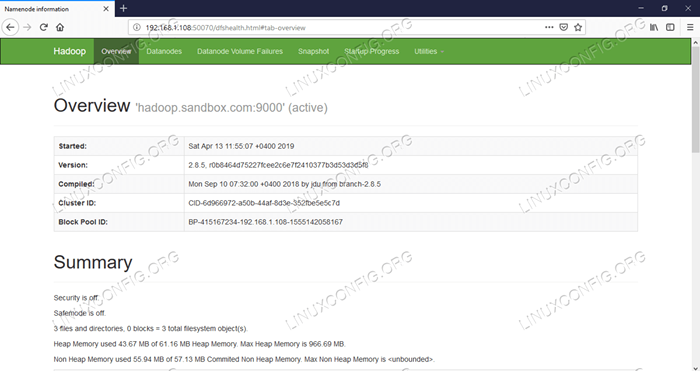 Interfejs użytkownika Namenode Web.
Interfejs użytkownika Namenode Web. 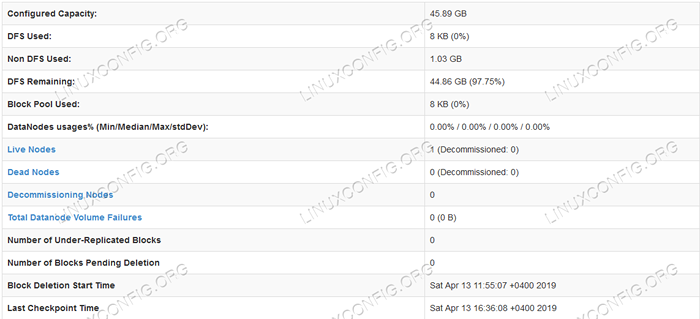 Informacje dotyczące szczegółowych informacji HDFS.
Informacje dotyczące szczegółowych informacji HDFS. 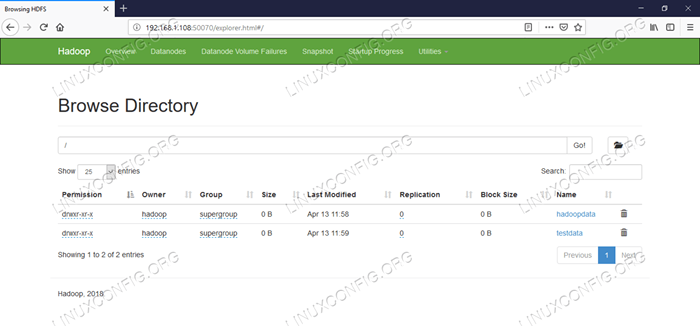 HDFS Directory Browing.
HDFS Directory Browing. Interfejs internetowy YARN Resource Manager (RM) wyświetli wszystkie uruchomione zadania w bieżącym klastrze Hadoop.
Interfejs internetowy menedżera zasobów - http: //: 8088
 Menedżer zasobów (YARN) Interfejs użytkownika internetowego.
Menedżer zasobów (YARN) Interfejs użytkownika internetowego. Wniosek
Świat zmienia sposób, w jaki obecnie działa, a Big-Data odgrywa ważną rolę w tej fazie. Hadoop to ramy, które ułatwia nasz życie podczas pracy nad dużymi zestawami danych. Istnieją ulepszenia na wszystkich frontach. Przyszłość jest ekscytująca.
Powiązane samouczki Linux:
- Ubuntu 20.04 Hadoop
- Rzeczy do zainstalowania na Ubuntu 20.04
- Jak utworzyć klaster Kubernetes
- Jak zainstalować Kubernetes na Ubuntu 20.04 Focal Fossa Linux
- Jak zainstalować Kubernetes na Ubuntu 22.04 JAMMY Jellyfish…
- Rzeczy do zrobienia po zainstalowaniu Ubuntu 20.04 Focal Fossa Linux
- Rzeczy do zainstalowania na Ubuntu 22.04
- Jak pracować z WooCommerce Rest API z Pythonem
- Jak zarządzać klastrami Kubernetes z Kubectl
- Wprowadzenie do automatyzacji, narzędzi i technik Linuksa
- « Jak zainstalować WordPress.Aplikacja komputerowa na Ubuntu 19.04 DISCO DINGO LINUX
- Jak zainstalować Redmine na RHEL 8 / Centos 8 Linux »