

Jak zainstalować klaster pojedynczego węzła Hadoop (pseudonode) w Centos 7

- 3311
- 769
- Ignacy Modzelewski
Hadoop to ramy typu open source, które jest powszechnie używane do radzenia sobie Bigdata. Większość Bigdata/analityka danych projekty są budowane na szczycie Hadoop Eco-System. Składa się z dwupowastu, jeden jest dla Przechowywanie danych A drugi jest dla Przetwarzanie danych.
Składowanie Zajmie się jego własnym systemem plików nazywanych HDFS (Hadoop rozproszony system plików) I Przetwarzanie będzie zadbany przez PRZĘDZA (Kolejny negocjator zasobów). MapReduce to domyślny silnik przetwarzania Hadoop Eco-System.
W tym artykule opisano proces zainstalowania Pseudonode instalacja Hadoop, gdzie wszystkie Demony (JVMS) będzie działać Pojedynczy węzeł Klaster Centos 7.
Jest to głównie dla początkujących, aby nauczyć się Hadoop. W czasie rzeczywistym, Hadoop zostaną zainstalowane jako klaster wielonodowy, w którym dane będą rozmieszczone między serwerami jako bloki, a zadanie zostanie wykonane równolegle.
Wymagania wstępne
- Minimalna instalacja serwera CentOS 7.
- Java V1.8 Wydanie.
- Hadoop 2.x stabilne wydanie.
Na tej stronie
- Jak zainstalować Java w Centos 7
- Skonfiguruj logowanie bez hasła na CentOS 7
- Jak zainstalować pojedynczy węzeł Hadoop w Centos 7
- Jak skonfigurować Hadoop w Centos 7
- Formatowanie systemu plików HDFS za pośrednictwem nazwy
Instalowanie Java na Centos 7
1. Hadoop to ekologiczny system, z którego składa się Jawa. Potrzebujemy Jawa Zainstalowane w naszym systemie obowiązkowo do instalacji Hadoop.
# Yum Zainstaluj java-1.8.0-Openjdk
2. Następnie zweryfikuj zainstalowaną wersję Jawa w systemie.
# java -version
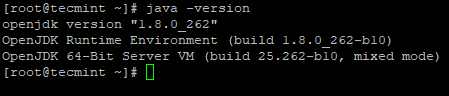 Sprawdź wersję Java
Sprawdź wersję Java Skonfiguruj logowanie bez hasła na Centos 7
Musimy skonfigurować SSH na naszym komputerze, Hadoop będzie zarządzał węzłami za pomocą Ssh. Węzeł główny używa Ssh Połączenie do podłączenia węzłów niewolników i wykonywania operacji, takich jak Start i Stop.
Musimy skonfigurować SSH bez hasła, aby Master mógł komunikować się z niewolnikami za pomocą SSH bez hasła. W przeciwnym razie dla każdego ustanowienia połączenia trzeba wprowadzić hasło.
W tym pojedynczym węzle, Gospodarz usługi (Namenode, Wtórny nazewnictwo I Menedżer zasobów) I Niewolnik usługi (DataNode I Nodemanager) będzie działać jako osobny JVMS. Mimo że jest to węzeł singowy, musimy mieć ssh bez hasła Gospodarz komunikować się Niewolnik bez uwierzytelnienia.
3. Skonfiguruj login SSH bez hasła za pomocą następujących poleceń na serwerze.
# ssh-keygen # ssh-copy-id -i localhost
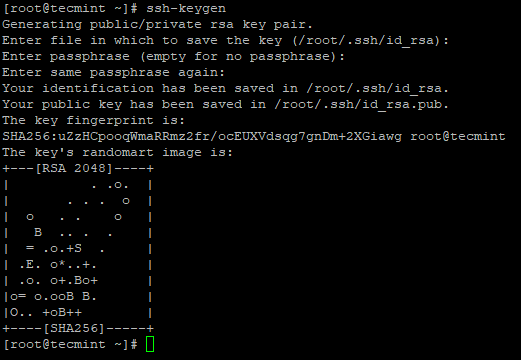 Utwórz ssh keygen w Centos 7
Utwórz ssh keygen w Centos 7 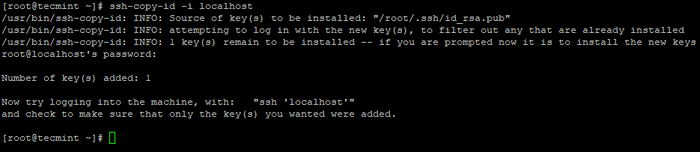 Skopiuj klucz SSH do Centos 7
Skopiuj klucz SSH do Centos 7 4. Po skonfigurowaniu loginu SSH bez hasła, spróbuj ponownie zalogować się, będziesz podłączony bez hasła.
# ssh localhost
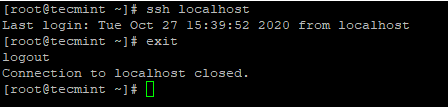 SSH Login bez hasła do Centos 7
SSH Login bez hasła do Centos 7 Instalowanie Hadoop w Centos 7
5. Przejdź do strony Apache Hadoop i pobierz stabilną wersję Hadoop za pomocą następującego polecenia WGET.
# wget https: // archiwum.Apache.org/dist/hadoop/core/hadoop-2.10.1/Hadoop-2.10.1.smoła.GZ # TAR XVPZF HADOOP-2.10.1.smoła.GZ
6. Następnie dodaj Hadoop Zmienne środowiskowe w ~/.Bashrc plik jak pokazano.
Hadoop_prefix =/root/hadoop-2.10.1 ścieżka = $ ścieżka: $ hadoop_prefix/bin eksport ścieżka java_home hadoop_prefix
7. Po dodaniu zmiennych środowiskowych do ~/.Bashrc plik, pozyskaj plik i zweryfikuj hadoop, uruchamiając następujące polecenia.
# Źródło ~/.Bashrc # cd $ hadoop_prefix # bin/hadoop wersja
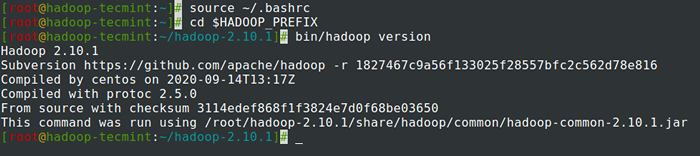 Sprawdź wersję Hadoop w Centos 7
Sprawdź wersję Hadoop w Centos 7 Konfigurowanie Hadoop w Centos 7
Musimy skonfigurować poniżej pliki konfiguracyjne Hadoop, aby dopasować się do komputera. W Hadoop, Każda usługa ma swój własny numer portu i własny katalog do przechowywania danych.
- Pliki konfiguracyjne Hadoop - miejsce podstawowe.XML, strona HDFS.XML, Mapred Site.witryna XML i przędzy.XML
8. Najpierw musimy zaktualizować Java_home I Hadoop ścieżka w Hadoop-env.cii plik jak pokazano.
# cd $ hadoop_prefix/etc/hadoop # vi hadoop-env.cii
Wprowadź następujący wiersz na początku pliku.
Eksport java_home =/usr/lib/jvm/java-1.8.0/jre eksport Hadoop_prefix =/root/hadoop-2.10.1
9. Następnie zmodyfikuj Site Core.XML plik.
# cd $ hadoop_prefix/etc/hadoop # vi Core-Site.XML
Wklej następujące pomiędzy tagi jak pokazano.
fs.Defaultfs HDFS: // LocalHost: 9000
10. Utwórz poniższe katalogi pod Tecmint Direktor Home User, który będzie używany Nn I Dn składowanie.
# mkdir -p/home/tecmint/hdata/ # mkdir -p/home/tecmint/hdata/data # mkdir -p/home/tecmint/hdata/nazwa
10. Następnie zmodyfikuj Site HDFS.XML plik.
# cd $ hadoop_prefix/etc/hadoop # vi HDFS-Site.XML
Wklej następujące pomiędzy tagi jak pokazano.
DFS.Replikacja 1 DFS.Namenode.nazwa.Dir/home/tecmint/hdata/nazwa dfs .DataNode.dane.DIR HOME/TECMINT/HDATA/DATA
11. Ponownie zmodyfikuj Mapred.XML plik.
# cd $ hadoop_prefix/etc/hadoop # cp Mapred-Site.XML.szablon Mapred-Site.XML # VI Mapred-Site.XML
Wklej następujące pomiędzy tagi jak pokazano.
MapReduce.struktura.Imię Parn
12. Wreszcie zmodyfikuj strona przędzy.XML plik.
# cd $ hadoop_prefix/etc/hadoop # vi Yarn-Site.XML
Wklej następujące pomiędzy tagi jak pokazano.
przędza.Nodemanager.Aux-Services MAPREDUCE_SHUFLE
Formatowanie systemu plików HDFS za pośrednictwem nazwy
13. Przed rozpoczęciem Grupa, Musimy sformatować Hadoop nn w naszym lokalnym systemie, w którym został zainstalowany. Zwykle będzie to zrobione w początkowym etapie przed rozpoczęciem klastra po raz pierwszy.
Formatowanie Nn spowoduje utratę danych w przerzutach NN, więc musimy być bardziej ostrożni, nie powinniśmy formatować Nn podczas gdy klaster działa, chyba że jest to wymagane celowo.
# cd $ hadoop_prefix # bin/hadoop namenode -Format
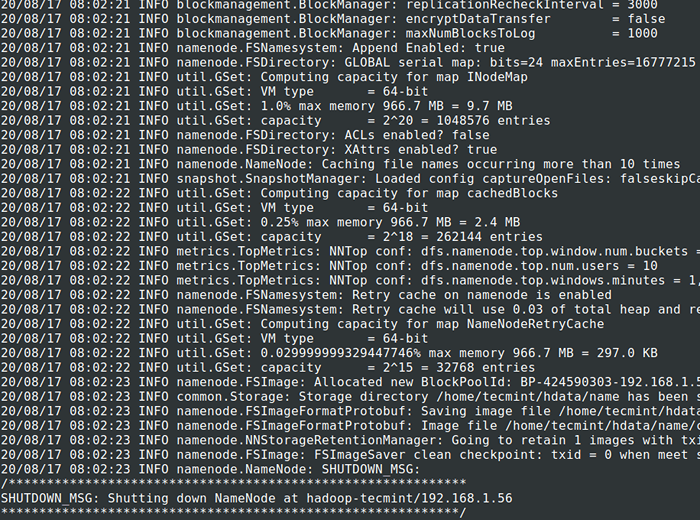 Sformatuj system plików HDFS
Sformatuj system plików HDFS 14. Początek Namenode Demon i DataNode Daemon: (port 50070).
# cd $ hadoop_prefix # sbin/start-dfs.cii
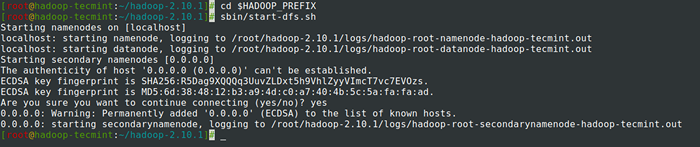 Rozpocznij demon Namenode i Datanode
Rozpocznij demon Namenode i Datanode 15. Początek ResourceManager Demon i Nodemanager Daemon: (port 8088).
# sbin/start-yarn.cii
 Rozpocznij DemongeManager i Nodemanager Demon
Rozpocznij DemongeManager i Nodemanager Demon 16. Aby zatrzymać wszystkie usługi.
# sbin/stop-dfs.sh # sbin/stop-dfs.cii
Streszczenie
Streszczenie
W tym artykule przeszliśmy proces krok po kroku, aby skonfigurować Hadoop pseudonode (Pojedynczy węzeł) Grupa. Jeśli masz podstawową wiedzę na temat Linuksa i wykonaj te kroki, klaster będzie za 40 minut.
Może to być bardzo przydatne dla początkujących, aby rozpocząć naukę i ćwiczenie Hadoop lub ta wersja waniliowa Hadoop może być używane do celów rozwojowych. Jeśli chcemy mieć klaster w czasie rzeczywistym, albo potrzebujemy co najmniej 3 fizycznych serwerów pod ręką, albo musimy zapewnić chmurę, aby mieć wiele serwerów.
- « Konfigurowanie warunków wstępnych Hadoop i utwardzania bezpieczeństwa - część 2
- Co to jest MongoDB? Jak działa MongoDB? »