

Jak zainstalować Kafkę na RHEL 8
- 4898
- 496
- Juliusz Sienkiewicz
Apache Kafka to rozproszona platforma strumieniowa. Dzięki jego bogatemu zestawowi interfejsu API (interfejs programowania aplikacji) możemy podłączyć głównie wszystko z Kafką jako źródłem danych, a z drugiej strony możemy skonfigurować dużą liczbę konsumentów, którzy otrzymają parę rekordów do przetwarzania. Kafka jest wysoce skalowalna i przechowuje strumienie danych w niezawodny i odporny na usterki sposób. Z perspektywy łączności Kafka może służyć jako pomost między wieloma heterogenicznymi systemami, które z kolei mogą polegać na możliwościach przesyłania i utrzymywania dostarczonych danych.
W tym samouczku zainstalujemy Apache Kafka na Red Hat Enterprise Linux 8, utworzył Systemd Pliki jednostkowe w celu ułatwienia zarządzania i przetestuj funkcjonalność za pomocą wysłanych narzędzi wiersza poleceń.
W tym samouczku nauczysz się:
- Jak zainstalować Apache Kafka
- Jak tworzyć usługi systemowe dla Kafki i Zookeeper
- Jak przetestować Kafkę z klientami wiersza poleceń
Konsumowanie wiadomości na temat Kafka z wiersza poleceń. Zastosowane wymagania i konwencje oprogramowania
| Kategoria | Wymagania, konwencje lub wersja oprogramowania |
|---|---|
| System | Red Hat Enterprise Linux 8 |
| Oprogramowanie | Apache Kafka 2.11 |
| Inny | Uprzywilejowany dostęp do systemu Linux jako root lub za pośrednictwem sudo Komenda. |
| Konwencje | # - Wymaga, aby podane polecenia Linux są wykonywane z uprawnieniami root bezpośrednio jako użytkownik root lub za pomocą sudo Komenda$ - Wymaga, aby podane polecenia Linux zostały wykonane jako zwykły użytkownik niepewny |
Jak zainstalować Kafkę na Instrukcjach Redhat 8 krok po kroku
Apache Kafka jest napisany w Javie, więc potrzebujemy tylko OpenJDK 8 zainstalowanego, aby kontynuować instalację. Kafka polega na Apache Zookeeper, rozproszonej usłudze koordynacji, która jest również napisana w Javie i jest dostarczana z pakietem, który pobramy. Podczas instalowania usług HA (wysoka dostępność) do jednego węzła zabija ich cel, zainstalujemy i uruchomimy Zookeeper na miłość boską.
- Aby pobrać Kafkę z najbliższego lustra, musimy zapoznać się z oficjalną witryną pobierania. Możemy skopiować adres URL
.smoła.GZplik stamtąd. Użyjemywget, i adres URL wklejony, aby pobrać pakiet na komputer docelowy:# wget https: // www-eu.Apache.org/dist/kafka/2.1.0/kafka_2.11-2.1.0.TGZ -O /Opt /Kafka_2.11-2.1.0.TGZ
- Wchodzimy do
/optowaćkatalog i wyodrębnij archiwum:# cd /opt # tar -xvf kafka_2.11-2.1.0.TGZ
I stwórz symbolizję o nazwie
/opt/kafkaTo wskazuje na teraz utworzone/opt/kafka_2_11-2.1.0katalog, aby ułatwić nasze życie.ln -s /opt /kafka_2.11-2.1.0 /opt /kafka
- Tworzymy niepewnego użytkownika, który uruchomi oba
ZookeeperIKafkapraca.# UserAdd Kafka
- I ustaw nowy użytkownik jako właściciela całego katalogu, który wyodrębniliśmy, rekurencyjnie:
# chown -r kafka: kafka /opt /kafka*
- Tworzymy plik jednostki
/etc/systemd/system/zookeeper.pracaZ następującą zawartością:
Kopiuj[Jednostka] Opis = Zookeeper po = syslog.Sieć docelowa.Target [Service] Type = Prosty User = Kafka Group = kafka execstart =/opt/kafka/bin/zookeeper-server-start.sh/opt/kafka/config/zookeeper.Właściwości execstop =/opt/kafka/bin/zookeeper-server-stop.sh [instalacja] WantedBy = Multi-użytkownik.celZauważ, że nie musimy pisać wersji numer trzykrotnie ze względu na utworzony symbol. To samo dotyczy następnego pliku jednostki dla Kafka,
/etc/systemd/system/kafka.praca, To zawiera następujące wiersze konfiguracji:
Kopiuj[Jednostka] Opis = Apache Kafka wymaga = Zookeeper.Service After = Zookeeper.Service [Service] Type = Prosty User = Kafka Group = Kafka ExecStart =/opt/kafka/bin/kafka-server-start.sh/opt/kafka/config/serwer.Właściwości execstop =/opt/kafka/bin/kafka-server-stop.sh [instalacja] WantedBy = Multi-użytkownik.cel - Musimy ponownie załadować
SystemdAby to uzyskać, przeczytaj nowe pliki jednostkowe:
# SystemCtl Demon-Reload
- Teraz możemy rozpocząć nasze nowe usługi (w tej kolejności):
# SystemCtl Start Zookeeper # Systemctl Start Kafka
Jeśli wszystko pójdzie dobrze,
Systemdpowinien zgłosić stan uruchamiania o statusie obu usług, podobnie jak wyniki poniżej:# SystemCtl Status Zookeeper.Service Zookeeper.Service - Zookeeper Załadowany: Załadowany (/etc/systemd/System/Zookeeper.praca; wyłączony; PREDET PREDOR: Wyłączony) Active: Active (Uruchamianie) od czwarto 2019-01-10 20:44:37 CET; 6s temu główny PID: 11628 (Java) Zadania: 23 (limit: 12544) Pamięć: 57.0m cgroup: /system.Slice/Zookeeper.Service 11628 Java -xMX512M -xMS512M -Server […] # Systemctl Status Kafka.Service Kafka.Service - Apache Kafka załadowana: załadowana (/etc/systemd/system/kafka.praca; wyłączony; PREDERTOR PREDET: Wyłączony) Aktywne: Aktywne (uruchamianie) od czwek od 2019-01-10 20:45:11 CET; 11s temu główny PID: 11949 (Java) Zadania: 64 (limit: 12544) Pamięć: 322.2M CGroup: /System.Slice/Kafka.Service 11949 java -xmx1g -xms1g -server […]
- Opcjonalnie możemy włączyć automatyczny start na obu usługach:
# SystemCtl Włącz Zookeeper.Service # Systemctl Włącz Kafkę.praca
- Aby przetestować funkcjonalność, połączymy się z Kafką z jednym producentem i jednym klientem konsumenckim. Wiadomości dostarczone przez producenta powinny pojawić się na konsoli konsumenta. Ale wcześniej potrzebujemy medium, które te dwie wiadomości wymiany na. Tworzymy nowy kanał danych o nazwie
tematw kategoriach Kafki, gdzie dostawca będzie publikować i gdzie konsument subskrybuje. Nazwiemy tematFirstkafkatopic. UżyjemyKafkaUżytkownik do utworzenia tematu:$/opt/kafka/bin/kafka-topics.SH-Create --zookeeper LocalHost: 2181-Odreplikacja Factor 1-Partions 1-Topic Firstkafkatopic
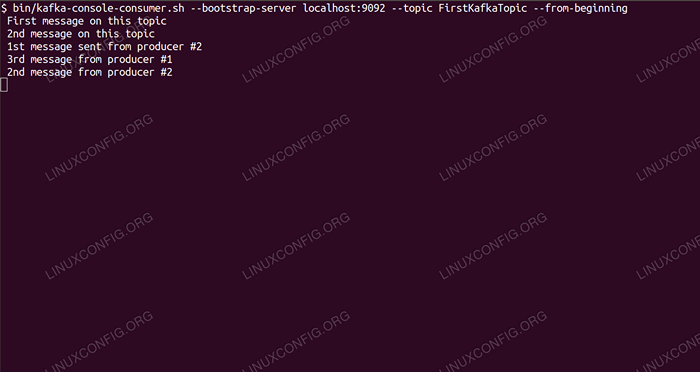
- Uruchamiamy klienta konsumenckiego z wiersza poleceń, który zapiszymy (w tym punkcie pustym) temat utworzony w poprzednim kroku:
$/opt/kafka/bin/kafka-console-konsole.sh-bootstrap-server localhost: 9092 --Temat Firstkafkatopic --od początku
Zostawiamy konsolę, a klient uruchomiony w niej otwarty. Ta konsola jest miejscem, w którym otrzymamy wiadomość, którą publikujemy z klientem producenta.
- Na innym terminalu zakładamy klienta producenta i publikujemy niektóre wiadomości do stworzonego przez nas tematu. Możemy zapytać Kafkę w celu uzyskania dostępnych tematów:
$/opt/kafka/bin/kafka-topics.sh - -list --zookeeper LocalHost: 2181 Firstkafkatopic
I połącz się z tym, który konsument jest subskrybowany, a następnie wyślij wiadomość:
$/opt/kafka/bin/kafka-console-producer.SH-Broker-List LocalHost: 9092-Topic Firstkafkatopic> Nowa wiadomość opublikowana przez producenta z konsoli nr 2
Na terminalu konsumenckim wiadomość powinna pojawić się wkrótce:
$/opt/kafka/bin/kafka-console-konsole.sh-bootstrap-server localhost: 9092-Topic Firstkafkatopic--od-beginning Nowa wiadomość opublikowana przez producenta z konsoli nr 2
Jeśli pojawi się wiadomość, nasz test się powiódł, a nasza instalacja Kafka działa zgodnie z przeznaczeniem. Wielu klientów może dostarczyć i konsumować jeden lub więcej rekordów tematów w ten sam sposób, nawet przy jednym konfiguracji węzła, który stworzyliśmy w tym samouczku.
Powiązane samouczki Linux:
- Jak korzystać z połączonej sieci z Libvirt i KVM
- Rzeczy do zainstalowania na Ubuntu 20.04
- Jak zapobiegać sprawdzaniu łączności NetworkManager
- Jak zainstalować parę na Ubuntu 22.04 JAMMY Jellyfish Linux
- Wprowadzenie do automatyzacji, narzędzi i technik Linuksa
- Jak korzystać z ADB Android Debug Bridge do zarządzania Androidem…
- Mastering Bash Script Loops
- Zagnieżdżone pętle w skryptach Bash
- Ubuntu 20.04 WordPress z instalacją Apache
- Jak pracować z WooCommerce Rest API z Pythonem