

Jak monitorować użycie systemu, awarie i rozwiązywanie problemów z serwerami Linux - Część 9

- 1718
- 417
- Pan Jeremiasz Więcek
Chociaż Linux jest bardzo niezawodny, administratorzy systemów powinni znaleźć sposób na obserwowanie zachowania i wykorzystania systemu przez cały czas. Zapewnienie czasu pracy tak blisko 100% Jak to możliwe, a dostępność zasobów są potrzebami krytycznymi w wielu środowiskach. Badanie przeszłości i aktualnego statusu systemu pozwoli nam przewidzieć i najprawdopodobniej zapobiec możliwym problemom.
 Certyfikowany inżynier Linux Foundation - Część 9
Certyfikowany inżynier Linux Foundation - Część 9 Wprowadzenie programu certyfikacji Fundacji Linux
W tym artykule przedstawimy listę kilku narzędzi dostępnych w większości dystrybucji upstream w celu sprawdzenia statusu systemu, analizy awarii i rozwiązywania problemów z bieżącymi problemami. W szczególności, z niezliczonych dostępnych danych, skupimy.
Wykorzystanie przestrzeni do przechowywania
Istnieją 2 dobrze znane polecenia w Linux, które służą do kontroli wykorzystania miejsca do przechowywania: df I du.
Pierwszy, df (który oznacza dysk wolny od dysku), jest zwykle używany do zgłaszania ogólnego wykorzystania miejsca na dysku według systemu plików.
Przykład 1: Zastosowanie przestrzeni dysku w bajtach i formacie odczytującego człowieka
Bez opcji, df Zgłasza wykorzystanie miejsca na dysku w bajtach. Z -H flaga wyświetli te same informacje za pomocą MB lub GB. Należy zauważyć, że ten raport zawiera również całkowity rozmiar każdego systemu plików (w blokach 1-K), bezpłatne i dostępne przestrzenie oraz punkt montażowy każdego urządzenia pamięci masowej.
# df # df -h
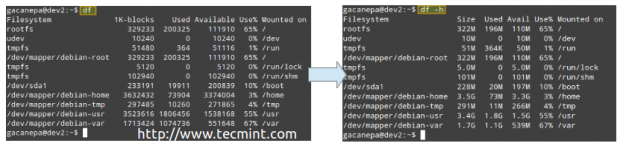 Wykorzystanie miejsca na dysku
Wykorzystanie miejsca na dysku To z pewnością miłe - ale istnieje jeszcze jedno ograniczenie, które może uczynić system plików bezużytecznych, a zabrakło im INODES. Wszystkie pliki w systemie plików są odwzorowane na inode zawierające jego metadane.
Przykład 2: Sprawdzanie użycia iNODE według systemu plików w formacie czytelnym człowieka
# df -hti
Możesz zobaczyć ilość użytych i dostępnych INODS:
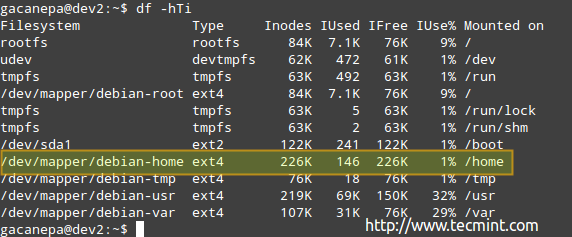 Używanie dysku iNode
Używanie dysku iNode Zgodnie z powyższym obrazem są 146 używane INODES (1%) In /Home, co oznacza, że nadal możesz tworzyć pliki 226k w tym systemie plików.
Przykład 3: Znalezienie i / lub usuwanie pustych plików i katalogów
Zauważ, że możesz zabraknąć miejsca do przechowywania na długo przed brakiem INODES i odwrotnie. Z tego powodu musisz monitorować nie tylko wykorzystanie przestrzeni pamięci, ale także liczbę inod używanych przez system plików.
Użyj następujących poleceń, aby znaleźć puste pliki lub katalogi (które zajmują 0b), które używają INODES bez powodu:
# Znajdź /home -type f -EMPY # Znajdź /home -Type d -EMPY
Możesz także dodać -usuwać Flag na końcu każdego polecenia, jeśli chcesz również usunąć te puste pliki i katalogi:
# Znajdź /home -Type f -EMPY - -delete # Znajdź /home -type f -EMPY
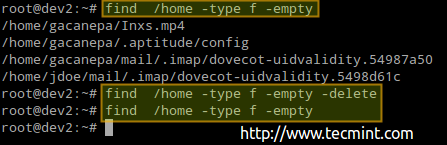 Znajdź i usuń puste pliki w Linux
Znajdź i usuń puste pliki w Linux Poprzednia procedura usunęła 4 pliki. Sprawdźmy ponownie liczbę używanych / dostępnych węzłów ponownie w / HOME:
# df -hti | Grep dom
 Sprawdź użycie INODE Linux
Sprawdź użycie INODE Linux Jak widać, są 142 używane teraz INODES (4 mniej niż wcześniej).
Przykład 4: Badanie użycia dysku według katalogu
Jeśli użycie określonego systemu plików jest powyżej predefiniowanego procentu, możesz użyć du (skrót od użycia dysku), aby dowiedzieć się, jakie są pliki, które zajmują najwięcej przestrzeni.
Przykład jest podany /var, które, jak widać na pierwszym obrazku powyżej, jest używany na 67%.
# du -sch /var /*
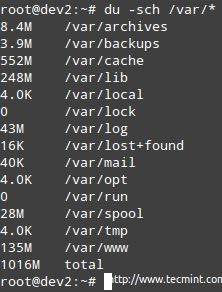 Sprawdź wykorzystanie miejsca na dysku według katalogu
Sprawdź wykorzystanie miejsca na dysku według katalogu Notatka: Że możesz przejść na dowolną z powyższych podkatalogów, aby dowiedzieć. Następnie możesz użyć tych informacji, aby usunąć niektóre pliki, jeśli nie są potrzebne lub rozszerzyć rozmiar woluminu logicznego, jeśli to konieczne.
Przeczytaj także
- 12 Przydatne polecenia „DF” do sprawdzenia miejsca na dysku
- 10 Przydatne polecenia „DU” do znalezienia użycia dysku i katalogów dysku i katalogów
Wykorzystanie pamięci i procesora
Klasyczne narzędzie w systemie Linux, które służy do wykonywania ogólnej kontroli wykorzystania procesora / pamięci i zarządzania procesami, jest TOP Command. Ponadto Top wyświetla widok w czasie rzeczywistym działającego systemu. Istnieją inne narzędzia, które mogą być używane w tym samym celu, takie jak HTOP, ale zdecydowałem się na górę, ponieważ są one instalowane poza pudełkiem w dowolnym dystrybucji Linux.
Przykład 5: Wyświetlanie statusu na żywo systemu z u góry
Aby uruchomić górę, po prostu wpisz następujące polecenie w wierszu poleceń i naciśnij Enter.
# szczyt
Zbadajmy typowe najwyższe wyjście:
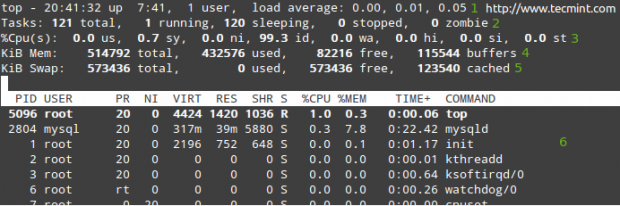 Wymień wszystkie uruchomione procesy w Linux
Wymień wszystkie uruchomione procesy w Linux W rzędach od 1 do 5 wyświetlane są następujące informacje:
1. Obecny czas (20:41:32) i czas pracy (7 godzin i 41 minut). Tylko jeden użytkownik jest zalogowany do systemu, a średnia obciążenia odpowiednio w ostatnich 1, 5 i 15 minutach. 0.00, 0.01 i 0.05 Wskaż, że w tych przedziałach czasowych system był bezczynny przez 0% czasu (0.00: Żadne procesy nie czekały na procesor), następnie został przeciążony o 1% (0.01: średnio 0.01 Procesy czekały na procesor) i 5% (0.05). Jeśli mniej niż 0 i mniejsza liczba (0.65, na przykład), system był bezczynny przez 35% w ciągu ostatnich 1, 5 lub 15 minut, w zależności od 0.Pojawia się 65.
2. Obecnie działa 121 procesów (możesz zobaczyć pełną listę w 6). Tylko 1 z nich działa (w tym przypadku na górze, jak widać w kolumnie %procesora), a pozostałe 120 czekają w tle, ale „śpi” i pozostanie w tym stanie, dopóki ich nie zadzwonimy. Jak? Możesz to zweryfikować, otwierając monit MySQL i wykonać kilka zapytań. Zauważysz, jak zwiększa liczbę procesów uruchamiania.
Alternatywnie możesz otworzyć przeglądarkę internetową i przejść do dowolnej strony obsługiwanej przez Apache, a otrzymasz ten sam wynik. Oczywiście przykłady te zakładają, że obie usługi są instalowane na twoim serwerze.
3. US (czas uruchamiania procesów użytkownika z niezmodyfikowanym priorytetem), SY (czas uruchamiający procesy jądra), NI (czas uruchamiania procesów użytkownika o zmodyfikowanym priorytecie), WA (czas oczekiwania na zakończenie we/wy), HI (czas spędzony na serwisowaniu sprzętu), SI (czas spędzony na serwisowaniu oprogramowania), ST (czas skradziony z obecnej maszyny wirtualnej przez hiperwizor - tylko w wirtualizowanych środowiskach).
4. Używanie pamięci fizycznej.
5. Zamknij użycie przestrzeni.
Przykład 6: Sprawdzanie użycia pamięci fizycznej
Aby sprawdzić pamięć pamięci RAM i użycie zamiany, możesz również użyć bezpłatny Komenda.
# bezpłatny
 Sprawdź użycie pamięci Linux
Sprawdź użycie pamięci Linux Oczywiście możesz również użyć -M (MB) lub -G (GB) Przełącza się na wyświetlanie tych samych informacji w formie czytelnej człowieka:
# darmowe -m
 Wyświetl użycie pamięci Linux
Wyświetl użycie pamięci Linux Tak czy inaczej, musisz być świadomy faktu, że jądro zastrzega jak najwięcej pamięci i udostępnia go do procesów, gdy o to poprosą. Szczególnie „„ „„-/+ bufory/pamięć podręczna”Wiersz pokazuje rzeczywiste wartości po uwzględnieniu tej pamięci podręcznej we/wy.
Innymi słowy, ilość pamięci używanej przez procesy i kwota dostępna dla innych procesów (w tym przypadku, 232 MB używane i 270 MB Dostępne odpowiednio). Gdy procesy potrzebują tej pamięci, jądro automatycznie zmniejszy rozmiar pamięci podręcznej we/wy.
Przeczytaj także: 10 Przydatne polecenie „darmowe” do sprawdzenia użycia pamięci Linux
Przyglądanie się procesom
W danym momencie w naszym systemie Linux istnieje wiele procesów. Istnieją dwa narzędzia, których użyjemy do uważnego monitorowania procesów: Ps I pstree.
Przykład 7: Wyświetlanie całej listy procesów w systemie z PS (pełny format standardowy)
Używając -mi I -F Opcje połączone w jedną (-ef) Możesz wymienić wszystkie procesy, które obecnie działają w twoim systemie. Możesz przewrócić to wyjście do innych narzędzi, takich jak Grep (Jak wyjaśniono w części 1 serii LFCS), aby zawęzić wyjście do pożądanego procesu (ES):
# ps -ef | Grep -i Squid | grep -v grep
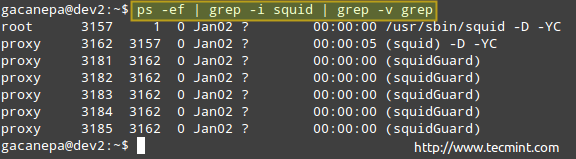 Procesy monitorowania w Linux
Procesy monitorowania w Linux Powyższa lista procesów pokazuje następujące informacje:
Właściciel procesu, PID, rodzicielski PID (proces nadrzędny), wykorzystanie procesora, czas po uruchomieniu polecenia, tty ( ? Wskazuje, że jest to demon), skumulowany czas procesora i polecenie powiązane z procesem.
Przykład 8: Dostosowywanie i sortowanie wyjścia PS
Być może jednak nie potrzebujesz wszystkich tych informacji i chciałbyś pokazać właściciela procesu, polecenie, które go rozpoczęło, jego PID i PPID oraz odsetek pamięci, której obecnie używa - w tej kolejności, i sortować według Używanie pamięci w kolejności malejącej (pamiętaj, że PS domyślnie jest sortowane przez PID).
# Ps -eo Użytkownik, Comm, PID, PPID,%MEM - -SORT -%MEM
Gdzie znak minus przed %MEM wskazuje sortowanie w kolejności malejącej.
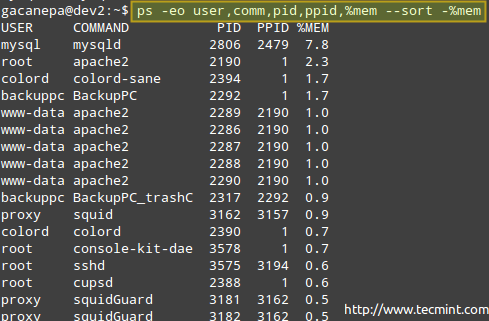 Monitoruj użycie pamięci Process Process
Monitoruj użycie pamięci Process Process Jeśli z jakiegoś powodu proces zacznie przyjmować zbyt wiele zasobów systemowych i prawdopodobnie zagrozi ogólnej funkcjonalności systemu, będziesz chciał zatrzymać lub zatrzymać jego wykonanie, przekazując jeden z poniższych sygnałów za pomocą programu zabijania. Inne powody, dla których rozważysz to, to wtedy, gdy rozpocząłeś proces na pierwszym planie, ale chcesz go zatrzymać i wznowić w tle.
| Nazwa sygnału | Numer sygnału | Opis |
| Sigterm | 15 | Zabij proces z wdziękiem. |
| Sigint | 2 | To jest sygnał, który jest wysyłany po naciśnięciu Ctrl + C. Ma na celu przerwanie procesu, ale proces może go zignorować. |
| Sigkill | 9 | Ten sygnał również przerywa proces, ale robi to bezwarunkowo (używaj z ostrożnością!) Ponieważ proces nie może go zignorować. |
| Wzdychanie | 1 | Sygnały ten skrót od „Hang Up” instruuje demony, aby przeczytać swój plik konfiguracyjny bez faktycznego zatrzymywania procesu. |
| Sigtstp | 20 | Zatrzymaj wykonanie i poczekaj gotowe do kontynuowania. Jest to sygnał, który jest wysyłany, gdy wpisujemy kombinację klucza Ctrl + Z. |
| Sigstop | 19 | Proces jest zatrzymany i nie zwraca większej uwagi cykli procesora, dopóki nie zostanie ponownie uruchomiony. |
| Sigcont | 18 | Ten sygnał mówi procesowi wznowienia wykonania po otrzymaniu SIGTSTP lub SIGSTOP. Jest to sygnał wysyłany przez powłokę, gdy używamy poleceń FG lub BG. |
Przykład 9: Zatrzymanie wykonywania procesu uruchomionego i wznowienie go w tle
Gdy normalne wykonywanie określonego procesu sugeruje, że nie zostanie wysyłane wyjście na ekran podczas jego uruchomienia, możesz albo uruchomić go w tle (dołączanie ampersand na końcu polecenia).
Nazwa procesu &
Lub,
Gdy zacznie działać na pierwszym planie, zatrzymaj go i wyślij na tle
Ctrl + z
# Zabij -18 pid
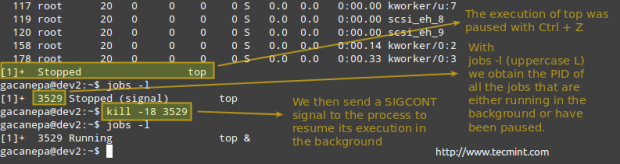 Zabij proces w Linux
Zabij proces w Linux Przykład 10: Zabijanie przez siłę proces „Gone Wild”
Należy pamiętać, że każda dystrybucja zapewnia narzędzia do zdzięcznego zatrzymywania / uruchamiania / ponownego uruchomienia / ponownego załadowania wspólnych usług, takich jak praca w systemach opartych na SYSV lub Systemctl w systemach opartych na systemie.
Jeśli proces nie reaguje na te narzędzia, możesz go zabić siłą, wysyłając mu sygnał sigkilla.
# ps -ef | Grep Apache # Kill -9 3821
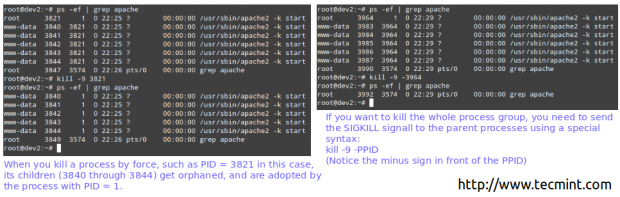 Socly Zabij proces Linuksa
Socly Zabij proces Linuksa Więc… co się stało / dzieje się?
Gdy w systemie nastąpiła jakaś awaria (czy to przerwa w zasilanie, awaria sprzętowa, planowana lub nieplanowana przerwa procesu, czy w ogóle jakąkolwiek nieprawidłowość), logów /var/log są Twoimi najlepszymi przyjaciółmi, aby ustalić, co się stało lub co może powodować problemy, z którymi się borykają.
# cd /var /log
 Zobacz dzienniki Linux
Zobacz dzienniki Linux Niektóre elementy w /var/log to zwykłe pliki tekstowe, inne są katalogami, a jeszcze inne są kompresowane pliki obracanych (historycznych) dzienników. Będziesz chciał sprawdzić je z błędem słowa w ich imieniu, ale sprawdzenie reszty może również się przydać.
Przykład 11: Badanie dzienników pod kątem błędów w procesach
Wyobraź sobie ten scenariusz. Twoi klienci LAN nie są w stanie wydrukować na drukarkach sieciowych. Pierwszym krokiem do rozwiązywania problemów z tą sytuacją jest /var/log/kubki katalog i zobacz, co tam jest.
Możesz użyć ogon polecenie wyświetlania ostatnich 10 wierszy pliku ERROR_LOG lub ogon -f error_log Widok dziennika w czasie rzeczywistym.
# cd/var/log/filiżanki # ls # ogon Error_log
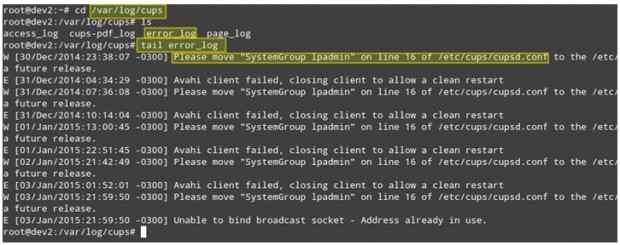 Monitoruj pliki dziennika w czasie rzeczywistym
Monitoruj pliki dziennika w czasie rzeczywistym Powyższy zrzut ekranu zawiera pomocne informacje, aby zrozumieć, co może być spowodowane Twoim problemem. Zauważ, że wykonanie kroków lub poprawienie nieprawidłowego działania procesu nadal może nie rozwiązać ogólnego problemu, ale jeśli zostaniesz używany od samego początku, aby sprawdzić dzienniki za każdym razem, gdy pojawia się problem (czy to lokalna, czy sieć) ty Zdecydowanie będzie na dobrej drodze.
Przykład 12: Badanie dzienników dla awarii sprzętu
Chociaż awarie sprzętowe mogą być trudne do rozwiązywania problemów, należy sprawdzić Dmesg oraz dzienniki komunikatów i GREP dla powiązanych słów z domniemaną wadliwą częścią sprzętową.
Poniższy obraz jest pobierany z /var/log/wiadomości Po poszukiwaniu błędu słowa za pomocą następującego polecenia:
# Less/var/log/wiadomości | Błąd grep -i
Widzimy, że mamy problem z dwoma urządzeniami do przechowywania: /dev/sdb I /dev/sdc, co z kolei powoduje problem z tablicą RAID.
 Rozwiązywanie problemów z Linux
Rozwiązywanie problemów z Linux Wniosek
W tym artykule zbadaliśmy niektóre narzędzia, które mogą pomóc ci zawsze być świadomym ogólnego statusu systemu. Ponadto musisz upewnić się, że system operacyjny i zainstalowane pakiety są aktualizowane do ich najnowszych stabilnych wersji. I nigdy nie zapomnij sprawdzić dzienników! Następnie skierujesz się we właściwym kierunku, aby znaleźć ostateczne rozwiązanie wszelkich problemów.
Zostaw swoje komentarze, sugestie lub pytania - jeśli masz dowolne - używając poniższego formularza.
Zostań inżynierem certyfikowanym Linux- « Jak skonfigurować repozytorium sieciowe do instalacji lub aktualizacji pakietów - Część 11
- Jak skonfigurować zaporę iptables, aby umożliwić zdalny dostęp do usług w Linux - część 8 »