

Jak wykonywać żądania HTTP z Python - Część 1 Standardowa biblioteka

- 4406
- 1087
- Ignacy Modzelewski
HTTP jest protokołem używanym przez World Wide Web, dlatego niezbędna jest interakcja z nią programowo: skrobanie strony internetowej, komunikowanie się z interfejsami API serwisowej, a nawet po prostu pobieranie pliku, to wszystkie zadania oparte na tej interakcji. Python sprawia, że takie operacje są bardzo łatwe: niektóre przydatne funkcje są już dostarczane w standardowej bibliotece, a w przypadku bardziej złożonych zadań jest możliwe (a nawet zalecane), aby używać zewnętrznego upraszanie moduł. W tym pierwszym artykule z serii skupimy się na wbudowanych modułach. Będziemy używać Python3 i głównie pracujemy w interaktywnej powładzie Python: potrzebne biblioteki zostaną zaimportowane tylko raz, aby uniknąć powtórzeń.
W tym samouczku nauczysz się:
- Jak wykonać żądania HTTP z Python3 i Urllib.Biblioteka żądań
- Jak pracować z odpowiedziami serwera
- Jak pobrać plik za pomocą funkcji URLOPEN lub URLRETRIVE
Żądanie HTTP z Python - PT. I: Standardowa biblioteka
Zastosowane wymagania i konwencje oprogramowania
| Kategoria | Wymagania, konwencje lub wersja oprogramowania |
|---|---|
| System | Niezależny od OS |
| Oprogramowanie | Python3 |
| Inny |
|
| Konwencje | # - Wymaga, aby podane polecenia Linux są wykonywane z uprawnieniami root bezpośrednio jako użytkownik root lub za pomocą sudo Komenda$ - Wymaga, aby podane polecenia Linux zostały wykonane jako zwykły użytkownik niepewny |
Wykonanie żądań ze standardową biblioteką
Zacznijmy od bardzo łatwego DOSTAWAĆ wniosek. Czasownik GET HTTP służy do pobierania danych z zasobu. Podczas wykonywania tego rodzaju żądań możliwe jest określanie niektórych parametrów w zmiennych formularzy: zmienne, wyrażone jako pary wartości kluczowej, formularz A String zapytania który jest „dołączony” do URL zasobu. Żądanie GET powinno zawsze być idempotent (Oznacza to, że wynik żądania powinien być niezależny od liczby jego wykonywania) i nigdy nie powinien być używany do zmiany stanu. Wykonanie żądań GET z Pythonem jest naprawdę łatwe. Ze względu na ten samouczek skorzystamy z otwartego wezwania NASA API, które pozwalają nam odzyskać tak zwane „Picture of the Day”:
>>> z urllib.Poproś o import URLOPEN >>> Z URLOPEN („https: // API.NASA.Gov/Planetary/Apod?api_key = demo_key ”) jako odpowiedź: ... response_content = odpowiedź.Czytać() Pierwszą rzeczą, którą zrobiliśmy, było import urlopen funkcja z urllib.wniosek Biblioteka: Ta funkcja zwraca http.klient.Httpresponse obiekt, który ma kilka bardzo przydatnych metod. Wykorzystaliśmy funkcję wewnątrz z stwierdzenie, ponieważ Httpresponse Obiekt obsługuje zarządzanie kontekstem Protokół: Zasoby są natychmiast zamykane po wykonaniu instrukcji „z”, nawet jeśli wyjątek jest podniesiony.
Czytać metoda, którą zastosowaliśmy w powyższym przykładzie, zwraca korpus obiektu odpowiedzi jako bajty i opcjonalnie przyjmuje argument reprezentujący ilość bajtów do odczytania (zobaczymy później, jak to jest ważne w niektórych przypadkach, szczególnie przy pobieraniu dużych plików). Jeśli ten argument zostanie pominięty, ciało odpowiedzi jest odczytywane w całości.
W tym momencie mamy ciało odpowiedzi jako obiekt bajtów, Odwołuje się do response_content zmienny. Możemy chcieć przekształcić to w coś innego. Aby zamienić go w ciąg, na przykład używamy rozszyfrować Metoda, podając typ kodowania jako argument, zazwyczaj:
>>> response_content.dekoduj („UTF-8”)
W powyższym przykładzie użyliśmy UTF-8 kodowanie. Wezwanie API, którego użyliśmy w przykładzie, zwraca jednak odpowiedź JSON Dlatego chcemy go przetworzyć z pomocą JSON moduł:
>>> Importuj Json Json_Response = JSON.obciążenia (response_content) JSON.masa Metoda deserializuje a strunowy, A bajty lub Bajt instancja zawierająca dokument JSON w obiekt Python. W tym przypadku wynikiem wywołania funkcji jest słownik:
>>> Od Pprint import pprint >>> pprint (json_response) „data”: „2019-04-14”, „Objaśnienie”: „Usiądź i obejrzyj scalanie dwóch czarnych dziur. Zainspirowany „Pierwsze bezpośrednie wykrywanie fal grawitacyjnych w 2015 r. Na kosmicznym etapie „„ Stage ”Czarne dziury są pozowane przed gwiazdami, gazem i„ „kurz. Ich ekstremalne grawitacje soczewki światło zza nich „do Einsteina dzwoni, gdy spiralnie bliżej i wreszcie łączą się” w jeden. Niewidoczne fale grawitacyjne „generowane jako masywne obiekty szybko łączą się, powodują, że„ widzialny obraz jest falujący i slajny zarówno wewnątrz, jak i na zewnątrz pierścienia Einstein nawet po połączeniu czarnych otworów. Nazwane „GW150914, fale grawitacyjne wykryte przez LIGO są„ zgodne z fuzją 36 i 31 słonecznych masy czarnych ”w odległości 1.3 miliardy lat świetlnych. Ostatnia „Pojedyncza czarna dziura ma 63 razy większą masę słońca, a pozostałe 3 masy słoneczne przekształcone w energię w„ falach grawitacyjnych. Od tego czasu obserwatoria fali grawitacyjnej LIGO i Virgo zgłosiły kilka innych „wykrywania scalania masywnych systemów, podczas gdy w zeszłym tygodniu teleskop„ wydarzenia horyzontu zgłosił pierwszy obraz w skali horyzontu ”czarnej dziury.„,„ Media_type ”:„ wideo ”,„ service_version ”:„ v1 ”,„ title ”:„ Symulacja: dwa czarne dziury scal ”,„ url ”: 'https: // wwww.youtube.com/embed/i_88s8dwbcu?rel = 0 ' Jako alternatywę moglibyśmy również użyć JSON_LOAD funkcja (zauważ brakujące „s”). Funkcja akceptuje podobne do pliku obiekt jako argument: oznacza to, że możemy używać go bezpośrednio na Httpresponse obiekt:
>>> z urlopen („https: // api.NASA.Gov/Planetary/Apod?api_key = demo_key ”) jako odpowiedź: ... Json_Response = JSON.Obciążenie (odpowiedź) Czytanie nagłówków odpowiedzi
Kolejna bardzo przydatna metoda użyteczna na Httpresponse Obiekt jest Getheaders. Ta metoda zwraca nagłówki odpowiedzi jako szeregu krotek. Każdy krotek zawiera parametr nagłówka i jego odpowiednią wartość:
>>> pprint (odpowiedź.getheaders ()) [(„serwer”, „OpenResty”), („data”, „Sun, 14 kwietnia 2019 10:08:48 gmt”), („content-type”, „application/json”), ( „Content-długości”, „1370”), („Connection”, „Close”), („varary”, „akceptowanie encoding”), („X-RateLimit-limit”, „40”), („x x -Ratelimit-Remining ', „37”), („via”, „1.1 Vegur, HTTP/1.1 API-UMBRELLA (APACHETRAFFICSERVER [CMSSF]) '), („Age”, „1”), („X-Cache”, „Miss”), („Access-Control-Allow-Origin”, „*”) , („Strict-Transport-Security”, „Max-Age = 31536000; wstępny ładunek”)]
Możesz zauważyć między innymi Typ zawartości parametr, który, jak powiedzieliśmy powyżej, jest Aplikacja/JSON. Jeśli chcemy odzyskać tylko określony parametr, możemy użyć Getheader Zamiast tego przekazywanie nazwy parametru jako argumentu:
>>> Odpowiedź.Getheader („Content-Type”) „Application/Json” Uzyskanie statusu odpowiedzi
Uzyskanie kodu stanu i Wyrażenie powodów zwrócone przez serwer po żądaniu HTTP jest również bardzo łatwe: wszystko, co musimy zrobić, to uzyskać dostęp do status I powód właściwości Httpresponse obiekt:
>>> Odpowiedź.Status 200 >>> Odpowiedź.Powód „OK” W tym zmienne w żądaniu GET
URL żądania, które przesłane powyżej zawierało tylko jedną zmienną: Klucz API, a jego wartość była „Demo_key”. Jeśli chcemy przekazać wiele zmiennych, zamiast ręcznie dołączać je do adresu URL, możemy dostarczyć je i ich powiązane wartości jako parami kluczowej wartości słownika Pythona (lub jako sekwencji krotek dwóch elementów); ten słownik zostanie przekazany do urllib.analizować.Urlencode metoda, która zbuduje i zwróci String zapytania. Wywołanie interfejsu API, którego użyliśmy powyżej, pozwól nam określić opcjonalną zmienną „datę”, aby pobrać obraz powiązany z określonym dniem. Oto jak możemy kontynuować:
>>> z urllib.Parse Import Urlencode >>> query_params = ...„API_KEY”: „DEMO_KEY”, ...„Data”: „2019-04-11” >>> query_string = urlencode (query_params) >>> query_string 'api_key = demo_key & data = 2019-04-11 ” Najpierw zdefiniowaliśmy każdą zmienną, a jej odpowiednia wartość jako pary wartości kluczowej słownika, niż zdaliśmy wspomniany słownik jako argument do Urlencode funkcja, która zwróciła sformatowany ciąg zapytania. Teraz, wysyłając żądanie, musimy tylko dołączyć ją do adresu URL:
>>> url = "?".dołącz (["https: // api.NASA.Gov/Planetary/apod ", Query_String])
Jeśli wyślemy żądanie za pomocą powyższego adresu URL, otrzymujemy inną odpowiedź i inny obraz:
„Data”: „2019-04-11”, „Objaśnienie”: „Jak wygląda czarna dziura? Aby dowiedzieć się, radiowe „teleskopy z całej Ziemi skoordynowały obserwacje„ Czarnych dziur z największymi znanymi horyzontami wydarzeń na „Sky. Sam, czarne dziury są po prostu czarne, ale te potwory „atraktory są otoczone świecącym gazem. „Pierwszy obraz został wydany wczoraj i rozwiązał obszar” wokół czarnej dziury w centrum Galaxy M87 na skali ”poniżej, który spodziewał się w horyzoncie zdarzeń. Na zdjęciu „Dark Central Region nie jest horyzontem zdarzeń, ale raczej„ Cień Czarnej Dziury - środkowy region emitującego gazu ”„ zaciemniony przez grawitację środkowej czarnej dziury. Rozmiar i „kształt cienia jest określany przez jasny gaz w pobliżu„ horyzontu zdarzenia, przez silne grawitacyjne ugięcia soczewki ”, a przez spin czarnej dziury. Rozwiązywając tę czarną dziurę „Shadow, teleskop horyzontu zdarzenia (EHT) wzmocnił dowody”, że grawitacja Einsteina działa nawet w ekstremalnych regionach, i „„ Dał wyraźne dowody, że M87 ma centralną wirującą czarną ”dziurę około 6 miliardów mas słonecznych. EHT nie jest gotowe -„Przyszłe obserwacje będą ukierunkowane na jeszcze wyższą” rozdzielczość, lepszą śledzenie zmienności i badanie „Bezpośrednie sąsiedztwo czarnej dziury na środku naszej„ Galaktyki Drogi Mlecznej Drogi.', „hdurl”:' https: // apod.NASA.Gov/apod/image/1904/m87BH_EHT_2629.jpg ', „media_type”: „image”, „service_version”: „v1”, „tytuł”: „Pierwszy obraz w skali horyzontu czarnej dziury”, „url”: „https: // apod.NASA.Gov/apod/image/1904/m87BH_EHT_960.jpg '
Na wypadek, gdybyś nie zauważył, zwrócony adres URL obrazu wskazuje niedawno zaprezentowane pierwsze zdjęcie czarnej dziury:
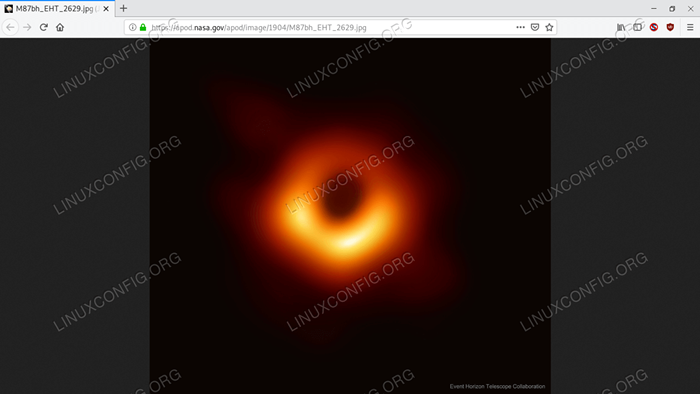
Zdjęcie zwrócone przez wywołanie API - pierwszy obraz czarnej dziury
Wysyłanie żądania pocztowego
Wysyłanie żądania pocztowego ze zmiennymi „zawartymi” wewnątrz ciała żądania, korzystając z standardowej biblioteki, wymaga dodatkowych kroków. Przede wszystkim, tak jak wcześniej, konstruujemy dane post w postaci słownika:
>>> dane = ... „zmienna1”: „wartość1”, ... „Zmienna2”: „wartość2” ... Po zbudowaniu naszego słownika chcemy użyć Urlencode funkcjonować tak jak wcześniej, a dodatkowo koduj wynikowy ciąg ASCII:
>>> post_data = urlencode (dane).Encode („ASCII”)
Wreszcie możemy wysłać nasze żądanie, przekazując dane jako drugi argument urlopen funkcjonować. W takim przypadku będziemy używać https: // httpbin.org/post jako URL docelowego (httpbin.Org to usługa żądania i odpowiedzi):
>>> z urlopen („https: // httpbin.org/post ", post_data) jako odpowiedź: ... Json_Response = JSON.ładuj (odpowiedź) >>> pprint (json_response) 'args': , 'data': ", 'pliki': , 'form': 'variale1': 'value1', 'varible2': ':': ':' value2 ', „nagłówki”: „Accept-Encoding”: „Identity”, „content-długość”: „33”, „content-typ”: „Application/x-Www-Form-Urlencoded”, „host” : „Httpbin.org ', „użytkownik-agent”: „Python-Urllib/3.7 „,„ JSON ”: Brak,„ Origin ”: 'xx.xx.xx.xx, xx.xx.xx.xx ', „url”:' https: // httpbin.org/post ' Żądanie zakończyło się powodzeniem, a serwer zwrócił odpowiedź JSON, która zawiera informacje o złożonym żądaniu. Jak widać zmienne, które przekazaliśmy w treści żądania, są zgłaszane jako wartość 'formularz' Klucz w ciele odpowiedzi. Czytanie wartości nagłówki klucz, możemy również zobaczyć, że typ zawartości żądania był Application/X-WWW-FORM-URLENCODED i agent użytkownika 'Python-Urllib/3.7 '.
Wysyłanie danych JSON na żądanie
Co jeśli chcemy wysłać reprezentację danych JSON z naszym żądaniem? Najpierw definiujemy strukturę danych, niż konwertujemy je na JSON:
>>> osoba = ... „FirstName”: „Luke”, ... „LastName”: „Skywalker”, ... „Tytuł”: „Jedi Knight” ... Chcemy również użyć słownika do zdefiniowania niestandardowych nagłówków. Na przykład w takim przypadku chcemy określić, że nasza zawartość żądania jest Aplikacja/JSON:
>>> custom_headers = ... „Content-typ”: „Application/Json” ... Wreszcie, zamiast wysyłać żądanie bezpośrednio, tworzymy Wniosek Object i przekazujemy, w kolejności: URL docelowego, dane żądania i nagłówki żądania jako argumenty jego konstruktora:
>>> z urllib.żądanie żądania importu >>> req = żądanie ( ... „https: // httpbin.org/post ", ... JSON.Zrzuty (osoba).Encode („ASCII”), ... Custom_headers ...) Jedną ważną rzeczą do zauważenia jest to, że użyliśmy JSON.depresja funkcja przekazująca słownik zawierający dane, które chcemy być uwzględnione w żądaniu jako jego argument: Ta funkcja jest używana serializuj obiekt w strumień sformatowany JSON, który zakodowaliśmy za pomocą kodować metoda.
W tym momencie możemy wysłać nasze Wniosek, przekazywanie go jako pierwszy argument urlopen funkcjonować:
>>> z URLOPEN (REQ) jako odpowiedź: ... Json_Response = JSON.Obciążenie (odpowiedź) Sprawdźmy zawartość odpowiedzi:
„args”: , „data”: '„FirstName”: „luke”, „lastName”: „Skywalker”, „title”: „jeedi” ”,„ pliki ”: ,' Forma ': ,' nagłówki ': ' Accept-Encoding ':' Identity ',' content-długości: '70', 'content-type': 'application/json', 'host': 'httpbin.org ', „użytkownik-agent”: „Python-Urllib/3.7 „,„ JSON ”: „ FirstName ”:„ Luke ”,„ LastName ”:„ Skywalker ”,„ Tytuł ”:„ Jedi Knight ”,„ Origin ”: 'xx.xx.xx.xx, xx.xx.xx.xx ', „url”:' https: // httpbin.org/post ' Tym razem widzimy, że słownik powiązany z kluczem „formularza” w ciele odpowiedzi jest pusty, a ten powiązany z kluczem „JSON” reprezentuje dane, które wysłaliśmy jako JSON. Jak można zauważyć, nawet wysyłany przez nas parametrem nagłówka niestandardowego został odebrany poprawnie.
Wysyłanie żądania z czasownikiem HTTP innym niż Get lub Post
Podczas interakcji z interfejsami API możemy potrzebować użyć Czasowniki HTTP Inne niż tylko dostać lub opublikować. Aby wykonać to zadanie, musimy użyć ostatniego parametru Wniosek Konstruktor klas i określ czasownik, którego chcemy użyć. Domyślny czasownik jest dostanie się, jeśli dane Parametr to Nic, W przeciwnym razie używany jest post. Załóżmy, że chcemy wysłać UMIEŚCIĆ wniosek:
>>> req = żądanie ( ... „https: // httpbin.org/put ", ... JSON.Zrzuty (osoba).Encode („ASCII”), ... Custom_headers, ... Method = „Put” ...) Pobieranie pliku
Kolejną bardzo powszechną operacją, którą możemy chcieć wykonać, jest pobranie pliku z Internetu. Korzystając ze standardowej biblioteki, istnieją na dwa sposoby: korzystanie z urlopen funkcja, odczyt odpowiedzi w fragmentach (zwłaszcza jeśli plik do pobrania jest duży) i zapisanie ich do pliku lokalnego „ręcznie” lub za pomocą URLRETRIVE Funkcja, która, jak stwierdzono w oficjalnej dokumentacji, jest uważana za część starego interfejsu i może zostać przestarzała w przyszłości. Zobaczmy przykład obu strategii.
Pobieranie pliku za pomocą urlopenu
Powiedzmy, że chcemy pobrać Tarball zawierającą najnowszą wersję kodu źródłowego jądra Linux. Korzystając z pierwszej metody wspomnianej powyżej, piszemy:
>>> najnowszy_kernel_tarball = "https: // cdn.jądro.org/pub/linux/jądro/v5.X/Linux-5.0.7.smoła.XZ ">>> Z Urlopen (najnowszy_kernel_tarball) jako odpowiedź: ... z Open („najnowszy kernel.smoła.xz ', „wb”) jako Tarball: ... Choć prawda: ... Chunk = odpowiedź.Przeczytaj (16384) ... Jeśli kawałek: ... Tarball.Napisz (kawałek) ... w przeciwnym razie: ... przerwa W powyższym przykładzie najpierw użyliśmy obu urlopen funkcja i otwarty Jeden w środku z instrukcjami, a zatem korzystanie z protokołu zarządzania kontekstem, aby upewnić się, że zasoby są oczyszczone natychmiast po wykonywaniu bloku kodu, w którym są używane. Wewnątrz a chwila pętla, przy każdej iteracji, kawałek Zmienne odniesienia do bajtów odczytanych z odpowiedzi (16384 w tym przypadku - 16 kibibytów). Jeśli kawałek nie jest pusta, piszemy treść do obiektu pliku („Tarball”); Jeśli jest pusty, oznacza to, że zużyliśmy całą zawartość ciała odpowiedzi, dlatego łamiemy pętlę.
Bardziej zwięzłe rozwiązanie obejmuje użycie Zaburzenie Biblioteka i copyfileobj Funkcja, która kopiuje dane z obiektu podobnego do pliku (w tym przypadku „odpowiedź”) na inny obiekt przypominający pliki (w tym przypadku „Tarball”). Rozmiar buforu można określić za pomocą trzeciego argumentu funkcji, który domyślnie jest ustawiony na 16384 bajtów):
>>> Importuj gniazdo ... z urlopen (najnowszy_kernel_tarball) jako odpowiedź: ... z Open („najnowszy kernel.smoła.xz ', „wb”) jako Tarball: ... Zaburzenie.copyfileobj (odpowiedź, tarbball) Pobieranie pliku za pomocą funkcji URLRETRIET
Alternatywną i jeszcze bardziej zwięzłą metodą pobierania pliku za pomocą standardowej biblioteki jest użycie urllib.wniosek.URLRETRIVE funkcjonować. Funkcja wymaga czterech argumentów, ale tylko dwa pierwsze interesują nas teraz: pierwsza jest obowiązkowa i jest adresem URL zasobów do pobrania; druga to nazwa używana do przechowywania zasobu lokalnego. Jeśli nie zostanie podane, zasób będzie przechowywany jako plik tymczasowy w /TMP. Kod staje się:
>>> z urllib.Poproś o import URLRETRIEVE >>> URLRETRIVE („https: // cdn.jądro.org/pub/linux/jądro/v5.X/Linux-5.0.7.smoła.xz ") („ najnowszy kernel.smoła.xz ', ) Bardzo proste, prawda?? Funkcja zwraca krotek, który zawiera nazwę używaną do przechowywania pliku (jest to przydatne, gdy zasób jest przechowywany jako plik tymczasowy, a nazwa jest losowo wygenerowana) i Httpmessage obiekt, który trzyma nagłówki odpowiedzi HTTP.
Wnioski
W pierwszej części serii artykułów poświęconych żądaniom Pythona i HTTP widzieliśmy, jak wysyłać różne rodzaje żądań za pomocą standardowych funkcji biblioteki i jak pracować z odpowiedziami. Jeśli masz wątpliwości lub chcesz szczegółowo zbadać, skonsultuj się z oficjalnym oficjalnym urllibem.Dokumentacja poproś. Kolejna część serii skupi się na bibliotece żądań Python HTTP.
Powiązane samouczki Linux:
- Wprowadzenie do automatyzacji, narzędzi i technik Linuksa
- Mastering Bash Script Loops
- Zagnieżdżone pętle w skryptach Bash
- Mint 20: Lepsze niż Ubuntu i Microsoft Windows?
- Rzeczy do zainstalowania na Ubuntu 20.04
- Jak pracować z WooCommerce Rest API z Pythonem
- Jak uruchomić procesy zewnętrzne z Pythonem i…
- Obsługa danych wejściowych użytkownika w skryptach Bash
- Jak ładować, rozładowywać i czarną listy moduły jądra Linux
- Hung Linux System? Jak uciec do wiersza poleceń i…
- « Wprowadzenie do bazy danych dołącza do Mariadb i MySQL
- Jak wykonać żądania HTTP z Python - Część 2 - Biblioteka żądań »