

Jak przetrwać dane do PostgreSQL w Javie
- 3159
- 879
- Laura Zygmunt
Java jest prawdopodobnie najczęściej używanym językiem programowania. To niezależność i niezależna od platformy natura umożliwia aplikacjom opartym na Javie działanie głównie na wszystkim. Podobnie jak w przypadku dowolnej aplikacji, musimy przechowywać nasze dane w jakiś niezawodny sposób - ta potrzeba nazywanych bazami danych do życia.
W JAVA Połączenia bazy danych są zaimplementowane przez JDBC (API łączności bazy danych Java), które pozwól, że programista obsługuje różne rodzaje baz danych w prawie w ten sam sposób, co znacznie ułatwia naszą życie, gdy musimy zapisać lub odczytać dane z bazy danych.
W tym samouczku utworzymy przykładową aplikację Java, która będzie mogła połączyć się z instancją bazy danych PostgreSQL i zapisywać dane do niej. Aby sprawdzić, czy nasze wprowadzenie danych zakończy się powodzeniem, zaimplementujemy również odczyt i wydrukować tabelę, do której wstawiliśmy dane.
W tym samouczku nauczysz się:
- Jak skonfigurować bazę danych dla aplikacji
- Jak zaimportować sterownik JDBC PostgreSQL do swojego projektu
- Jak wstawić dane do bazy danych
- Jak uruchomić proste zapytanie do odczytania treści tabeli bazy danych
- Jak wydrukować pobierane dane
Wyniki uruchamiania aplikacji. Zastosowane wymagania i konwencje oprogramowania
| Kategoria | Wymagania, konwencje lub wersja oprogramowania |
|---|---|
| System | Ubuntu 20.04 |
| Oprogramowanie | NetBeans IDE 8.2, PostgreSQL 10.12, jdk 1.8 |
| Inny | Uprzywilejowany dostęp do systemu Linux jako root lub za pośrednictwem sudo Komenda. |
| Konwencje | # - Wymaga, aby podane polecenia Linux są wykonywane z uprawnieniami root bezpośrednio jako użytkownik root lub za pomocą sudo Komenda$ - Wymaga, aby podane polecenia Linux zostały wykonane jako zwykły użytkownik niepewny |
Ustawić
Do celów tego samouczka potrzebujemy tylko jednej stacji roboczej (pulpit lub laptopa), aby zainstalować wszystkie potrzebne komponenty. Nie obejmiemy instalacji JDK, NetBeans IDE ani instalacji bazy danych PostgreSQL na komputerze laboratoryjnym. Zakładamy, że nazywana baza danych Exampledb jest uruchomiony, a my możemy łączyć, czytać i pisać za pomocą uwierzytelniania hasła, z następującymi poświadczeniami:
| Nazwa użytkownika: | przykładuser |
| Hasło: | Przykład |
To przykładowa konfiguracja, używaj silnych haseł w scenariuszu prawdziwego świata! Baza danych jest ustawiona do słuchania na LocalHost, co będzie potrzebne po skonstruowaniu JDBC URL połączenia.
Głównym celem naszej aplikacji jest pokazanie, jak pisać i czytać z bazy danych, więc w przypadku cennych informacji jesteśmy tak chętni do utrzymania, po prostu wybierzemy liczbę losową od 1 do 1000 i przechowujemy te informacje z unikalnymi ID obliczeń i dokładny czas rejestrowania danych w bazie danych.
Identyfikator i czas nagrywania będą dostarczane przez bazę danych, która pozwala naszemu aplikacji pracować wyłącznie w prawdziwym wydaniu (w tym przypadku pod warunkiem losowego numeru). Jest to celowe i omówimy możliwości tej architektury na końcu tego samouczka.
Konfigurowanie bazy danych aplikacji
Mamy uruchomioną usługę bazy danych i bazę danych o nazwie Exampledb Mamy prawa do pracy z wyżej wymienionymi poświadczeniami. Aby mieć miejsce, w którym możemy przechowywać nasze cenne (losowe) dane, musimy utworzyć tabelę, a także sekwencję, która zapewni unikalne identyfikatory w wygodny sposób. Rozważ następujący skrypt SQL:
Utwórz sekwencję ResultId_seq Start z 0 przyrostem przez 1 Brak MAXValue MinValue 0 Cache 1; Zmień sekwencję ResultId_Seq właściciel do ExampleSer; Utwórz tabelę calc_Results (resztka Numerowa kluczowa kluczowa wartość NextVal ('resetId_seq' :: RegClass), wynik_of_calculation Numeric, a nie null, rejestr_date timestamp default teraz ()); Zmień właściciel Calc_Results do ExampleSer; Te instrukcje powinny mówić za siebie. Tworzymy sekwencję, ustawiamy właściciela przykładuser, Utwórz tabelę o nazwie calc_results (Stojąc do „wyników obliczeń”), ustaw resztka do automatycznego wypełnienia kolejną wartością naszej sekwencji na każdej wkładce i zdefiniuj wynik_of_calculation I record_date kolumny, które będą przechowywać nasze dane. Wreszcie, właściciel stołu jest również ustawiony przykładuser.
Aby utworzyć te obiekty bazy danych, przełączamy się na Postgres użytkownik:
$ sudo su - postgres
I uruchom skrypt (przechowywany w pliku tekstowym o nazwie TABLE_FOR_JAVA.SQL) niezgodne z Exampledb Baza danych:
$ psql -d exampledb < table_for_java.sql CREATE SEQUENCE ALTER SEQUENCE CREATE TABLE ALTER TABLE
Dzięki temu nasza baza danych jest gotowa.
Importowanie sterownika JDBC PostgreSQL do projektu
Aby zbudować aplikację, użyjemy NetBeans IDE 8.2. Pierwsze kilka kroków to praca ręczna. Wybieramy menu plików, tworz nowy projekt. Zostawimy wartości domyślne na następnej stronie czarodzieja, z kategorią „Java” i projektem „aplikacji Java”. Naciśniemy następne. Podajemy aplikacji nazwę (i opcjonalnie definiujemy lokalizację bez default). W naszym przypadku zostanie to wezwane trwaletopostgres. To sprawi, że IDE utworzy dla nas podstawowy projekt Java.
W panelu projektów klikamy prawym przyciskiem myszy „Biblioteki” i wybieramy „Dodaj bibliotekę…”. Pojawi się nowe okno, w którym wyszukiwamy i wybieramy sterownik PostgreSQL JDBC i dodaje go jako bibliotekę.
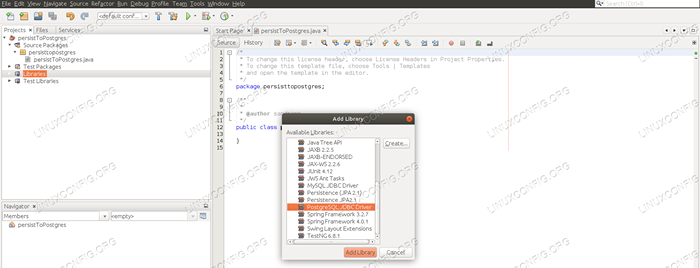 Dodanie sterownika JDBC PostgreSQL do projektu.
Dodanie sterownika JDBC PostgreSQL do projektu. Zrozumienie kodu źródłowego
Teraz dodajemy następujący kod źródłowy do głównej klasy naszej aplikacji, Trwaletopostgres:
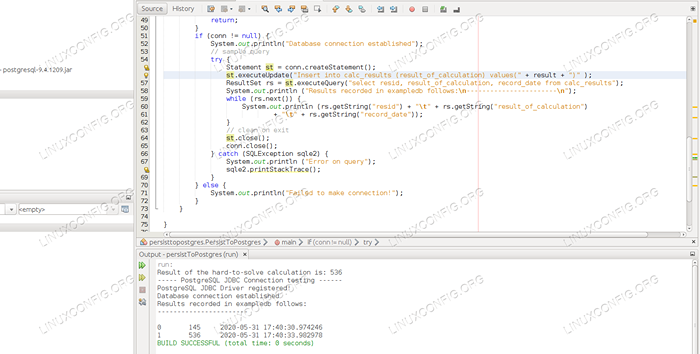
Pakiet trwaletopostgres; Importuj Java.SQL.Połączenie; Importuj Java.SQL.DriverManager; Importuj Java.SQL.Wyniki; Importuj Java.SQL.Sqlexception; Importuj Java.SQL.Oświadczenie; Importuj Java.Util.równoległy.ThreadLocalrandom; klasa publiczna trwajtopostgres public static void main (string [] args) int result = ThreadLocalrandom.aktualny().NextInt (1, 1000 + 1); System.na zewnątrz.println („Wynik trudno rozwiązywania obliczeń to:” + wynik); System.na zewnątrz.println ("----- Postgresql JDBC Testowanie połączenia ------"); spróbuj klasa.Forname ("org.PostgreSQL.Driver "); catch (classNotFoundException cnfe) System.na zewnątrz.println („Brak sterownika JDBC Postgresql w ścieżce biblioteki!"); cnfe.printStackTrace (); powrót; System.na zewnątrz.println („Zarejestrowany sterownik PostgreSQL JDBC!"); Connection conn = null; try conn = driverManager.getConnection („jdbc: postgresql: // localhost: 5432/exampledB”, „exampleSer”, „examplePass”); catch (sqlexception sqle) System.na zewnątrz.println („Połączenie nie powiodło się! Sprawdź konsolę wyjściową "); sqle.printStackTrace (); powrót; if (conn != null) system.na zewnątrz.println („Ustanowione połączenie bazy danych”); // Zapytanie o budowę próbuj instrukcja st = conn conn.createStatement (); St.ExecuteUpdate („Wstaw do calc_results (wynik_of_calculation) wartości („ + wynik + ”)”); Wynik RS = ST.ExecuteQuery („Wybierz resztę, wynik_of_calculation, Record_Date z calc_results”); System.na zewnątrz.println („Wyniki zarejestrowane w ExampleDB następuje: \ n ----------------------- \ n”); While (Rs.następny ()) System.na zewnątrz.println (Rs.getString („reszta”) + „\ t” + rs.getString („result_of_calculation”) + „\ t” + rs.getString („record_date”)); // Oczyść na Exit St.zamknąć(); Conn.zamknąć(); catch (sqlexception sqle2) System.na zewnątrz.println („błąd na zapytaniu”); sqle2.printStackTrace (); else System.na zewnątrz.println („Nie udało się nawiązać połączenia!"); - W wierszu 12 obliczamy liczbę losową i przechowujemy ją w
wynikzmienny. Liczba ta reprezentuje wynik ciężkich obliczeń
Musimy przechowywać w bazie danych. - W wierszu 15 staramy się zarejestrować sterownik PostgreSQL JDBC. Spowoduje to błąd, jeśli aplikacja nie znajdzie sterownika w czasie wykonywania.
- W wierszu 26 budujemy ciąg połączenia JDBC za pomocą nazwy hosta, na którym działa baza danych (LocalHost), port, który baza danych słuchała (5432, domyślny port PostgreSQL), nazwę bazy danych (ExcledB) oraz poświadczenia wymienione w początek.
- W wierszu 37 wykonujemy
włóż wInstrukcja SQL, która wstawia wartośćwynikzmienna dowynik_of_calculationKolumnacalc_resultstabela. Określamy tylko wartość tych pojedynczych kolumn, więc mają zastosowanie domyślne:resztkajest pobierany z sekwencji
zestaw irecord_datedomyślnie doTeraz(), który jest czasem bazy danych w momencie transakcji. - W wierszu 38 konstruujemy zapytanie, które zwróci wszystkie dane zawarte w tabeli, w tym naszą wkładkę w poprzednim kroku.
- Z linii 39 prezentujemy dane pobrane, drukując je w sposób podobny do tabeli, zwolnić zasoby i wyjść.
Uruchamianie aplikacji
Możemy teraz wyczyścić, budować i uruchomić trwaletopostgres aplikacja, z samego IDE lub z wiersza poleceń. Aby uruchomić z IDE, możemy użyć przycisku „Uruchom projekt” na górze. Aby uruchomić go z wiersza poleceń, musimy przejść do dist katalog projektu i wywołać JVM z SŁOIK pakiet jako argument:
$ java -jar trwaltopostgres.Wynik jar trudno rozwiązywania obliczeń to: 173 ----- PostgreSQL JDBC Testowanie połączenia ------ Połączenie bazy danych Ustalone wyniki zarejestrowane w ExcpledB następuje: ------------- ---------- 0 145 2020-05-31 17:40:30.974246
Wiersze polecenia zapewnią to samo wyjście co konsola IDE, ale ważniejsze jest tutaj to, że każdy uruchomienie (czy to z IDE, czy z wiersza poleceń) wstawię kolejny wiersz do naszej tabeli bazy danych z podaną liczbą losową obliczoną na każdym uruchomić.
Właśnie dlatego zobaczymy również rosnącą liczbę rekordów na wyjściu aplikacji: każdy bieg rośnie tabelę jednym wierszem. Po kilku przejazdach zobaczymy długą listę wierszy wyników w tabeli.
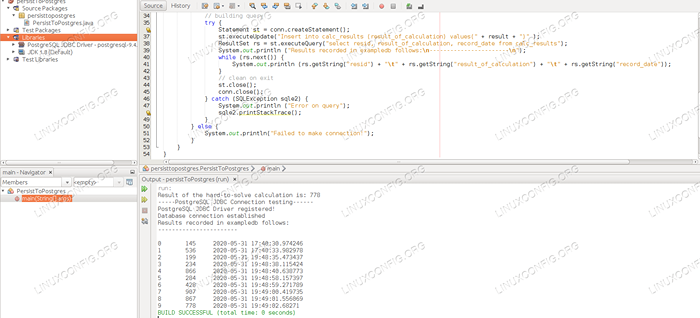 Wyjście bazy danych pokazuje wyniki każdego wykonywania aplikacji.
Wyjście bazy danych pokazuje wyniki każdego wykonywania aplikacji. Wniosek
Chociaż ta prosta aplikacja nie ma żadnego użycia w świecie rzeczywistym, idealnie jest wykazać się naprawdę ważnymi aspektami. W tym samouczku powiedzieliśmy, że dokonujemy ważnych obliczeń z aplikacją i za każdym razem wkładaliśmy liczbę losową, ponieważ celem tego samouczka jest pokazanie, jak przetrwać dane. Ten cel, który ukończyliśmy: z każdym uruchomieniem aplikacja kończy się i wyniki obliczeń wewnętrznych zostaną utracone, ale baza danych zachowuje dane.
Wykonaliśmy aplikację z jednej stacji roboczej, ale jeśli naprawdę będziemy musieli rozwiązać skomplikowane obliczenia, musielibyśmy tylko zmienić adres URL podłączania bazy danych, aby wskazać zdalne urządzenie z bazą danych, i moglibyśmy rozpocząć obliczenia na wielu komputerach Jednocześnie tworząc setki lub tysiące przypadków tej aplikacji, być może rozwiązywanie małych elementów większej łamigłówki i przechowuj wyniki w trwałym sposobie, umożliwiając skalowanie naszej mocy obliczeniowej za pomocą kilku wierszy kodu i trochę planowanie.
Dlaczego planowanie jest potrzebne? Aby pozostać w tym przykładzie: jeśli nie zostawimy przypisywania identyfikatorów wierszy lub znacznika czasu do bazy danych, nasza aplikacja byłaby znacznie większa, znacznie wolniejsza i znacznie bardziej pełna błędów - niektóre z nich pojawiają się tylko wtedy aplikacja w tym samym momencie.
Powiązane samouczki Linux:
- Ubuntu 20.04 Instalacja PostgreSQL
- Ubuntu 22.04 Instalacja PostgreSQL
- Jak zapobiegać sprawdzaniu łączności NetworkManager
- Rzeczy do zainstalowania na Ubuntu 20.04
- Jak pracować z WooCommerce Rest API z Pythonem
- Jak sprawdzić żywotność baterii na Ubuntu
- EEPROM CH341A Programator - Odczyt i zapisz dane do układu na…
- Rzeczy do zainstalowania na Ubuntu 22.04
- Instalacja Oracle Java na Ubuntu 20.04 Focal Fossa Linux
- Jak zainstalować Java na Manjaro Linux