

Jak odzyskać dane i odbudować nieudane oprogramowanie RAID - Część 8

- 923
- 80
- Roland Sokół
W poprzednich artykułach z tej serii RAID przeszedłeś od zera do RAID HERO. Przejrzeliśmy kilka konfiguracji RAID oprogramowania i wyjaśniliśmy niezbędne elementy każdego z nich, wraz z powodami, dla których skłaniałbyś się w kierunku jednego lub drugiego w zależności od konkretnego scenariusza.
 Odzyskaj przebudowę nieudanych oprogramowania - część 8
Odzyskaj przebudowę nieudanych oprogramowania - część 8 W tym przewodniku omówimy, jak odbudować tablicę RAID oprogramowania bez utraty danych, gdy w przypadku awarii dysku. Dla zwięzłości rozważymy tylko RAID 1 konfiguracja - ale koncepcje i polecenia dotyczą wszystkich przypadków.
Scenariusz testowania rajdów
Przed kontynuowaniem upewnij się, że skonfigurowałeś RAID 1 tablica zgodnie z instrukcjami podanymi w części 3 tej serii: Jak skonfigurować RAID 1 (Mirror) w Linux.
Jedynymi wariantami w naszym obecnym przypadku będą:
1) inna wersja Centos (v7) niż ta używana w tym artykule (v6.5) i
2) różne rozmiary dysków dla /dev/sdb I /dev/sdc (8 GB każdy).
Ponadto, jeśli Selinux jest włączony w trybie egzekwowania, musisz dodać odpowiednie etykiety do katalogu, w którym zamontujesz urządzenie RAID. W przeciwnym razie wpadniesz na tę wiadomość ostrzegawczą, próbując ją zamontować:
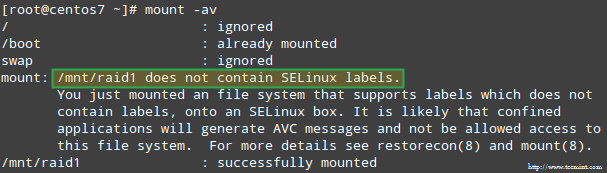 Błąd montażu RAID Selinux
Błąd montażu RAID Selinux Możesz to naprawić, biegając:
# Restorecon -r /mnt /RAID1
Konfigurowanie monitorowania RAID
Istnieje wiele powodów, dla których urządzenie pamięci mogą zawieść (SSD znacznie zmniejszyły szanse na to, ale niezależnie od przyczyny możesz mieć pewność, że problemy mogą wystąpić w dowolnym momencie i musisz być przygotowany na wymianę nieudanych część i zapewnić dostępność i integralność danych.
Najpierw słowo rady. Nawet jeśli możesz sprawdzić /proc/mdstat Aby sprawdzić status nalotów, istnieje lepsza i oszczędzająca czas metoda, która polega na uruchomieniu Mdadm W trybie Monitor + Scan, który wyśle powiadomienia za pośrednictwem poczty elektronicznej do predefiniowanego odbiorcy.
Aby to skonfigurować, dodaj następujący wiersz /etc/mdadm.conf:
Mailaddr [e -mail chroniony]
W moim przypadku:
Mailaddr [e -mail chroniony]
 RAID MONITOROWANIE POWOSTAJE E -mailowe
RAID MONITOROWANIE POWOSTAJE E -mailowe Biegać Mdadm W trybie Monitor + Scan dodaj następujący wpis crontab jako root:
@reboot /sbin /mdadm - -monitor - -scan --oneshot
Domyślnie, Mdadm sprawdzi tablice RAID co 60 sekund i wyślę ostrzeżenie, jeśli znajdzie problem. Możesz zmodyfikować to zachowanie, dodając --opóźnienie Opcja do wpisu crontab powyżej wraz z ilością sekund (na przykład, --opóźnienie 1800 oznacza 30 minut).
Na koniec upewnij się, że masz Agent użytkownika poczty (MUA) zainstalowane, takie jak Mutt lub Mailx. W przeciwnym razie nie otrzymasz żadnych powiadomień.
Za chwilę zobaczymy, co przesłał ostrzeżenie Mdadm wygląda jak.
Symulacja i wymiana nieudanego urządzenia do przechowywania RAID
Aby zasymulować problem z jednym z urządzeń pamięci w tablicy RAID, użyjemy --zarządzać I --set-faultty Opcje w następujący sposób:
# mdadm-Managage--Set-Faulty /dev /md0 /dev /sdc1
To spowoduje /dev/sdc1 oznaczone jako wadliwe, jak widzimy w /proc/mdstat:
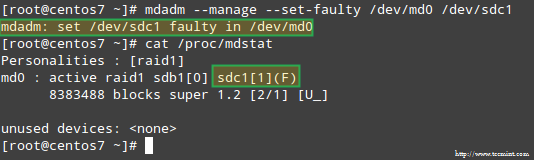 Stymulować problem za pomocą przechowywania RAID
Stymulować problem za pomocą przechowywania RAID Co ważniejsze, zobaczmy, czy otrzymaliśmy alert e -mail z tym samym ostrzeżeniem:
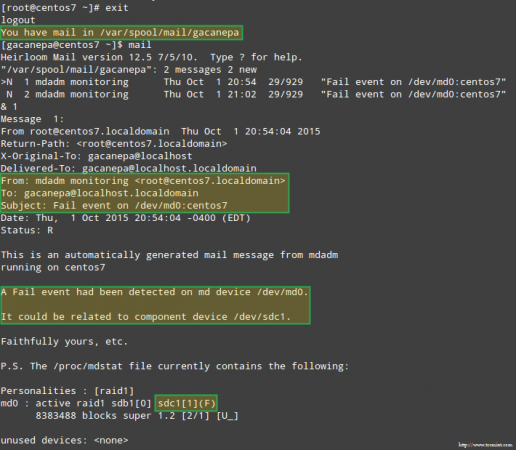 Alert e -mail na nieudanym urządzeniu RAID
Alert e -mail na nieudanym urządzeniu RAID W takim przypadku musisz usunąć urządzenie z oprogramowania RAID Array:
# mdadm /dev /md0 - -Remove /dev /sdc1
Następnie możesz fizycznie usunąć go z maszyny i wymienić część zamienną (/dev/sdd, gdzie partycja typu FD został wcześniej utworzony):
# mdadm -Manage /dev /md0 --add /dev /sdd1
Na szczęście dla nas system automatycznie zacznie odbudowywać tablicę z częścią, którą właśnie dodaliśmy. Możemy to przetestować, oznaczając /dev/sdb1 jako wadliwe, usuwanie go z tablicy i upewnienie się, że plik Tecmint.tekst jest nadal dostępny w /MNT/RAID1:
# mdadm - -detail /dev /md0 # Mount | GREP RAID1 # LS -L /MNT /RAID1 | Grep Tecminint # cat/mnt/Raid1/Tecmint.tekst
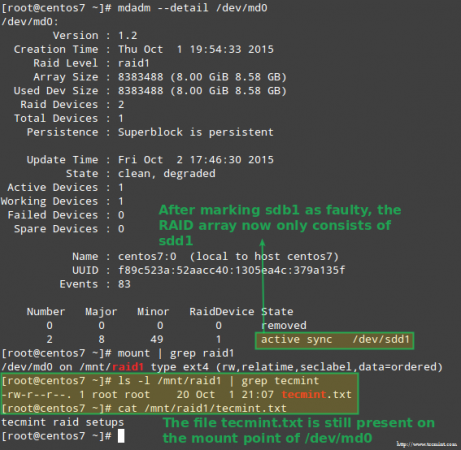 Potwierdź przebudowę tablicy RAID
Potwierdź przebudowę tablicy RAID Powyższy obraz wyraźnie pokazuje, że po dodaniu /dev/sdd1 do tablicy jako zamiennik /dev/sdc1, odbudowa danych została automatycznie wykonana przez system bez interwencji.
Choć nie jest to wyłącznie wymagane, świetny pomysł jest przydatne zapasowe urządzenie, aby proces zastąpienia wadliwego urządzenia dobrym dążeniem można było wykonać. Aby to zrobić, ponownie dodajmy /dev/sdb1 I /dev/sdc1:
# mdadm -Manage /dev /md0 --add /dev /sdb1 # mdadm -Manage /dev /md0 --add /dev /sdc1
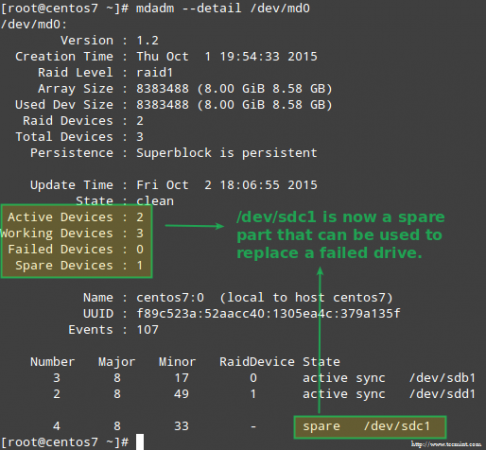 Wymień nieudane urządzenie RAID
Wymień nieudane urządzenie RAID Wraca do zdrowia po utraty redundancji
Jak wyjaśniono wcześniej, Mdadm automatycznie odbuduje dane, gdy jeden dysk się nie powiedzie. Ale co się stanie, jeśli 2 dyski w tablicy zawiodą? Symulujmy taki scenariusz, oznaczając /dev/sdb1 I /dev/sdd1 jako wadliwe:
# Umount /Mnt /Raid1 # mdadm-Managage--set-faulty /dev /md0 /dev /sdb1 # mdadm --stop /dev /md0 # mdadm-Managage--set-faulty /dev /md0 /dev /md0 /dev /md0 /dev /md0 /dev /md0 /dev /md0 /dev /md0 /dev /md0 /dev /md0 /dev /md0 /dev /md0 /dev / SDD1
Próby ponownego utworzenia tablicy w taki sam sposób, jak w tym czasie (lub za pomocą --Załóżmy clean opcja) może spowodować utratę danych, więc powinno być pozostawione w ostateczności.
Spróbujmy odzyskać dane /dev/sdb1, na przykład w podobnej partycji dysku (/dev/sde1 - Zauważ, że wymaga to utworzenia partycji typu FD W /dev/sde Przed kontynuowaniem) używając ddrescue:
# ddrescue -r 2 /dev /sdb1 /dev /sde1
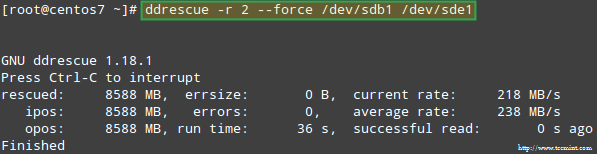 Odzyskiwanie tablicy rajdów
Odzyskiwanie tablicy rajdów Pamiętaj, że do tego momentu nie dotknęliśmy /dev/sdb Lub /dev/sdd, partycje, które były częścią tablicy RAID.
Teraz odbudujmy tablicę za pomocą /dev/sde1 I /dev/sdf1:
# mdadm-Create /dev /md0-Level = Mirror--Raid-devices = 2 /dev /sd [e-f] 1 1
Należy pamiętać, że w prawdziwej sytuacji zwykle używasz tych samych nazw urządzeń, jak w oryginalnej tablicy, to znaczy, /dev/sdb1 I /dev/sdc1 Po nieudanych dyskach zastąpionych nowymi.
W tym artykule postanowiłem użyć dodatkowych urządzeń do odtworzenia tablicy z nowymi dyskami i uniknięciem zamieszania z oryginalnymi nieudanymi dyskami.
Zapytany, czy kontynuować pisanie tablicy, wpisz Y i naciśnij Wchodzić. Tablica powinna zostać uruchomiona i powinieneś być w stanie obserwować jej postęp z:
# Watch -n 1 cat /proc /mdstat
Po zakończeniu procesu powinieneś mieć dostęp do treści RAID:
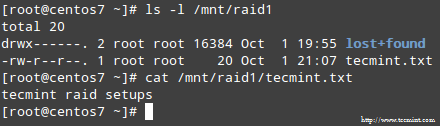 Potwierdź treść nalotów
Potwierdź treść nalotów Streszczenie
W tym artykule sprawdziliśmy, jak się wyzdrowieć NALOT awarie i straty z nadmiarowością. Musisz jednak pamiętać, że ta technologia jest rozwiązaniem do przechowywania i NIE Wymień kopie zapasowe.
Zasady wyjaśnione w tym przewodniku dotyczą wszystkich konfiguracji RAID, a także koncepcji, które omówimy w następnym i ostatecznym przewodniku tej serii (zarządzanie RAID).
Jeśli masz jakieś pytania dotyczące tego artykułu, upuszcz nam notatkę za pomocą poniższego formularza komentarza. Oczekujemy na kontakt zwrotny!
- « Jak uzyskać informacje sprzętowe za pomocą polecenia DMIDECode w Linux
- Powerline - Dodaje potężne linie statusu i podpowiedzi do VIM Editor i Bash Terminal »