

Jak skonfigurować Hadoop 2.6.5 (klaster pojedynczych węzłów) na Ubuntu, Centos i Fedora

- 1993
- 549
- Maria Piwowarczyk
Apache Hadoop 2.6.5 zauważalne ulepszenia w stosunku do poprzednich stabilnych 2.X.Y Wydania. Ta wersja ma wiele ulepszeń HDF i MapReduce. Ten przewodnik pomoże Ci zainstalować Hadoop 2.6 na Centos/RHEL 7/6/5, Ubuntu i inny system operacyjny oparty na debian. Ten artykuł nie zawiera ogólnej konfiguracji konfiguracji Hadoop, mamy tylko podstawową konfigurację wymaganą do rozpoczęcia pracy z Hadoop.
Krok 1: Instalowanie Java
Java jest głównym wymogiem konfigurowania Hadoop w dowolnym systemie, więc upewnij się, że Java zainstalowana w systemie za pomocą następującego polecenia.
# Java -version Java wersja „1.8.0_101 "Java (TM) SE Środowisko środowiskowe (kompilacja 1.8.0_131-B11) Java Hotspot (TM) 64-bitowy serwer VM (kompilacja 25.131-B11, tryb mieszany)
Jeśli nie masz zainstalowanej Java w swoim systemie, użyj jednego z następujących linków, aby go najpierw zainstalować.
Zainstaluj Java 8 na Centos/RHEL 7/6/5
Zainstaluj Java 8 na Ubuntu
Krok 2: Tworzenie użytkownika Hadoop
Zalecamy utworzenie normalnego (ani root) konta dla Hadoop działającej. Utwórz konto systemowe za pomocą następującego polecenia.
# Adduser Hadoop # Passwd Hadoop
Po utworzeniu konta wymagał również skonfigurowania SSH opartych na kluczu na własne konto. Aby to zrobić, użyj wykonania następujących poleceń.
# su -hadoop $ ssh -keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/autoryzowane_keys $ chmod 0600 ~/.ssh/autoryzowane_keys
Sprawdźmy logowanie oparte na kluczu. Poniższe polecenie nie powinno prosić o hasło, ale po raz pierwszy wyświetli monit o dodanie RSA do listy znanych hostów.
$ ssh localhost $ exit
Krok 3. Pobieranie Hadoop 2.6.5
Teraz pobierz Hadoop 2.6.0 Plik archiwum źródłowego za pomocą poniższego polecenia. Możesz także wybrać alternatywne lustro pobierania w celu zwiększenia prędkości pobierania.
$ cd ~ $ wget http: // www-eu.Apache.org/dist/hadoop/common/hadoop-2.6.5/Hadoop-2.6.5.smoła.GZ $ TAR XZF HADOOP-2.6.5.smoła.GZ $ MV HADOOP-2.6.5 Hadoop
Krok 4. Skonfiguruj tryb pseudo-dystrybucji Hadoop
4.1. Konfiguruj zmienne środowiskowe Hadoop
Najpierw musimy ustawić zastosowania zmiennych środowiskowych przez Hadoop. Edytować ~/.Bashrc Plik i dołącz następujące wartości na końcu pliku.
Eksport hadoop_home =/home/hadoop/hadoop eksport hadoop_install = $ hadoop_home eksport hadoop_mapred_home = $ hadoop_home eksport hadoop_common_home = $ hadoop_home eksport hadoop_hdfs_home = $ hadoop_home export yarn_home Hadoop_home/sbin: $ hadoop_home/bin
Teraz zastosuj zmiany w bieżącym środowisku działającym
$ źródło ~/.Bashrc
Teraz edytuj $ Hadoop_home/etc/hadoop/hadoop-env.cii plik i zestaw Java_home Zmienna środowiskowa. Zmień ścieżkę Java zgodnie z instalacją w systemie.
Eksport java_home =/opt/jdk1.8.0_131/
4.2. Edytuj pliki konfiguracyjne
Hadoop ma wiele plików konfiguracyjnych, które muszą skonfigurować zgodnie z wymaganiami, aby skonfigurować infrastrukturę Hadoop. Zacznijmy od konfiguracji z konfiguracją klastra klastra pojedynczego węzła Basic Hadoop. Najpierw przejdź do poniżej lokalizacji
$ cd $ hadoop_home/etc/hadoop
Edytuj stronę Core.XML
fs.domyślny.Nazwa HDFS: // LocalHost: 9000
Edytuj stronę HDFS.XML
DFS.Replikacja 1 DFS.nazwa.Dir Plik: /// home/hadoop/hadoopdata/hdfs/namenode dfs.dane.Plik dir: /// home/hadoop/hadoopdata/hdfs/dataanode
Edytuj stronę Mapred.XML
MapReduce.struktura.Imię Parn
Edytuj stronę przędzy.XML
przędza.Nodemanager.Aux-Services MAPREDUCE_SHUFLE
4.3. Formatuj nazewniowy
Teraz sformatuj nazwy za pomocą następującego polecenia, upewnij się, że katalog pamięci jest
$ hdfs namenode -Format
Przykładowy wyjście:
15/02/04 09:58:43 Info Namenode.Namenode: startup_msg: /*********************************************** *************** Startup_msg: Uruchamianie Namenode startup_msg: host = svr1.tecadmin.Net/192.168.1.133 startup_msg: args = [-format] startup_msg: wersja = 2.6.5… 15/02/04 09:58:57 Info Wspólne.Pamięć: katalog pamięci/home/hadoop/hadoopdata/hdfs/namenode został pomyślnie sformatowany. 15/02/04 09:58:57 Info Namenode.Nnstorageretention Manager: Zachowaj 1 obrazy z txid> = 0 15/02/04 09:58:57 Info Util.EXITUTIL: Wyjście ze statusem 0 15/02/04 09:58:57 Info Namenode.Namenode: supdown_msg: /*********************************************** ***************.tecadmin.Net/192.168.1.133 *************************************************** ***********/
Krok 5. Rozpocznij klaster Hadoop
Teraz zacznij swój klaster Hadoop przy użyciu skryptów dostarczanych przez Hadoop. Po prostu przejdź do katalogu Hadoop Sbin i wykonaj skrypty jeden po drugim.
$ cd $ hadoop_home/sbin/
Teraz biegnij start-DFS.cii scenariusz.
$ start-dfs.cii
Przykładowy wyjście:
15/02/04 10:00:34 ostrzegaj.NativeCodeloader: Nie można załadować natywnej biblioteki-hadoopu dla platformy… Korzystanie z klas Buildin-Java, w stosownych przypadkach, uruchamianie nazwy na [localhost] LocalHost: Uruchamianie nazwy, logowanie do/home/hadoop/hadoop/logs/hadoop-hadoop-namenode-svr1.tecadmin.internet.Out LocalHost: Uruchamianie danych, logowanie do/home/hadoop/hadoop/logs/hadoop-hadoop-datanode-svr1.tecadmin.internet.Uruchamianie wtórnych mianod [0.0.0.0] Autentyczność hosta '0.0.0.0 (0.0.0.0) „Nie można ustalić. Kluczowy odcisk palca RSA to 3C: C4: F6: F1: 72: D9: 84: F9: 71: 73: 4a: 0d: 55: 2c: F9: 43. Czy na pewno chcesz kontynuować łączenie (tak/nie)? Tak 0.0.0.0: Ostrzeżenie: stale dodane „0.0.0.0 '(RSA) do listy znanych gospodarzy. 0.0.0.0: Uruchamianie SecondaryNamenode, logowanie do/home/hadoop/hadoop/logs/hadoop-hadoop-secondarynode-svr1.tecadmin.internet.Out 15/02/04 10:01:15 Ostrzegaj UTIL.NativeCodeloader: Nie można załadować natywnej biblioteki hadoop
Teraz biegnij Start-Yarn.cii scenariusz.
$ start-yarn.cii
Przykładowy wyjście:
Rozpoczęcie Demony Piekłe Początkowe ResourceManager, Logowanie do/Home/Hadoop/Hadoop/Logs/Yarn-Hadoop-ResourceManager-SVR1.tecadmin.internet.Out LocalHost: Rozpoczęcie NodeManagera, logowanie do/home/hadoop/hadoop/logs/przędza-hadoop-nodemanager-svr1.tecadmin.internet.na zewnątrz
Krok 6. Uzyskaj dostęp do usług Hadoop w przeglądarce
Hadoop Namenode rozpoczął się w porcie 50070 domyślnie. Uzyskaj dostęp do serwera na porcie 50070 w ulubionej przeglądarce internetowej.
http: // svr1.tecadmin.netto: 50070/
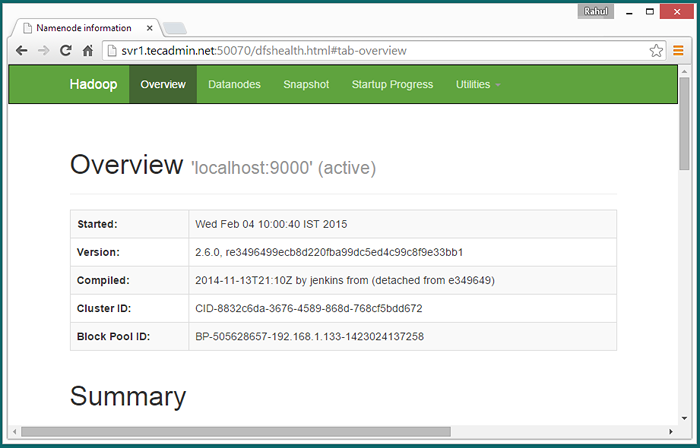
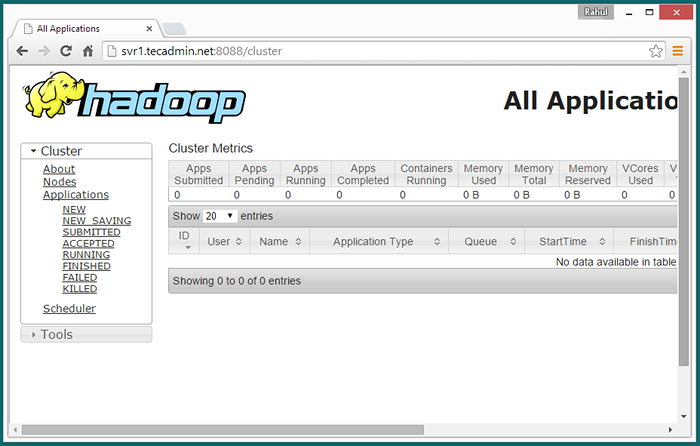
Teraz uzyskaj dostęp do portu 8088 do uzyskania informacji o klastrze i wszystkich aplikacjach
http: // svr1.tecadmin.netto: 8088/
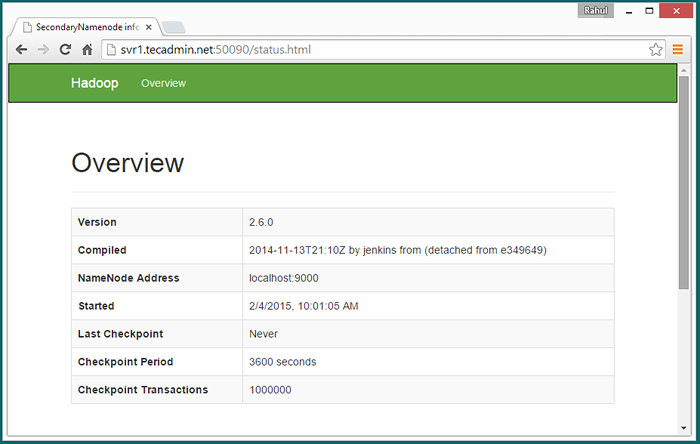
Dostęp do portu 50090 w celu uzyskania szczegółowych informacji na temat wtórnego nazwy nazewniczej.
http: // svr1.tecadmin.Netto: 50090/
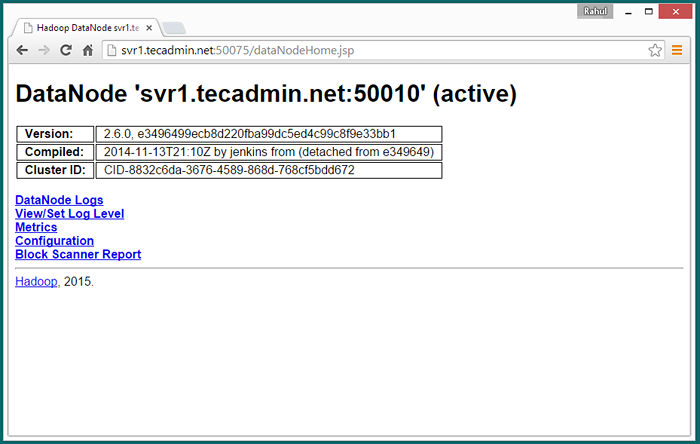
Dostęp do portu 50075, aby uzyskać szczegółowe informacje na temat datanode
http: // svr1.tecadmin.Netto: 50075/
Krok 7. Test konfiguracji pojedynczego węzła Hadoop
7.1 - Spraw, aby katalogi HDFS wymagane za pomocą następujących poleceń.
$ bin/hdfs dfs -mkdir/użytkownik $ bin/hdfs dfs -mkdir/użytkownik/hadoop
7.2 - Teraz skopiuj wszystkie pliki z lokalnego systemu plików/var/log/httpd do hadoop rozproszonego systemu plików za pomocą poniższego polecenia
$ bin/hdfs dfs -put/var/log/httpd logs
7.3 - Teraz przeglądaj system plików rozproszony Hadoop, otwierając poniżej URL w przeglądarce.
http: // svr1.tecadmin.Netto: 50070/Explorer.html#/user/hadoop/logs
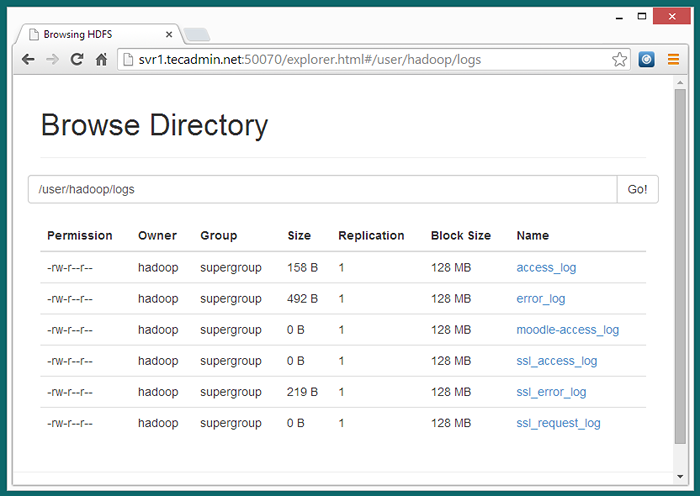
7.4 - Teraz kopiuj katalog dzienników dla Hadoop rozproszony system plików do lokalnego systemu plików.
$ bin/hdfs dfs -Get logs/tmp/logs $ ls -l/tmp/logs/
Możesz także sprawdzić ten samouczek, aby uruchomić WordCount MapReduce EDMAT ZADANIA za pomocą wiersza poleceń.