

Zainstaluj klaster wieloosobowy Hadoop za pomocą CDH4 w RHEL/CENTOS 6.5

- 2930
- 11
- Seweryn Augustyniak
Hadoop to ramy programowania open source opracowane przez Apache w celu przetwarzania dużych zbiorów danych. To używa HDFS (Hadoop rozproszony system plików) Aby przechowywać dane we wszystkich danych w klastrze w sposób dystrybucyjny i modelu MapReduce w celu przetworzenia danych.
 Zainstaluj klaster wieloosobowy Hadoop
Zainstaluj klaster wieloosobowy Hadoop Namenode (Nn) to główny demon, który kontroluje HDFS I Jobtracker (Jt) jest głównym demem dla silnika MapReduce.
Wymagania
W tym samouczku używam dwóch Centos 6.3 VMS 'gospodarz' I 'węzełMimo to. (Master and Node to moje nazwy hostów). IP „Master” to 172.21.17.175 A węzeł IP to '172.21.17.188'. Działa również następujące instrukcje Rhel/Centos 6.X Wersje.
Na mistrzu
[[e -mail chroniony] ~]# nazwa hosta gospodarz
[[e -mail chroniony] ~]# ifconfig | grep 'inet addr' | head -1 inet addr:172.21.17.175 Bcast: 172.21.19.255 Maska: 255.255.252.0
Na węźle
[[e -mail chroniony] ~]# nazwa hosta węzeł
[[e -mail chroniony] ~]# ifconfig | grep 'inet addr' | head -1 inet addr:172.21.17.188 Bcast: 172.21.19.255 Maska: 255.255.252.0
Najpierw upewnij się, że wszystkie hosty klastrów są tam '/etc/hosts„Plik (w każdym węźle), jeśli nie masz konfiguracji DNS.
Na mistrzu
[[e -mail chroniony] ~]# cat /etc /hosts 172.21.17.175 Master 172.21.17.188 węzeł
Na węźle
[[e -mail chroniony] ~]# cat /etc /hosts 172.21.17.197 Qabox 172.21.17.176 Ansible-Ground
Instalowanie klastra wieloosobowego Hadoop w Centos
Używamy oficjalnych CDH repozytorium do instalacji CDH4 na wszystkich hostach (Master and Node) w klastrze.
Krok 1: Pobierz instaluj repozytorium CDH
Przejdź do oficjalnej strony pobierania CDH i chwyć CDH4 (i.mi. 4.6) wersja lub możesz użyć następujących wget polecenie do pobrania repozytorium i zainstalowania.
Na 32-bit RHEL/CENTOS
# wget http: // archiwum.Cloudera.COM/CDH4/One Click-Install/Redhat/6/i386/Cloudera-CDH-4-0.i386.RPM # Yum-NogpgCheck LocalInstall Cloudera-CDH-4-0.i386.RPM
Na 64-bit RHEL/Centos
# wget http: // archiwum.Cloudera.COM/CDH4/One Click-install/Redhat/6/x86_64/Cloudera-CDH-4-0.x86_64.RPM # Yum-NogpgCheck LocalInstall Cloudera-CDH-4-0.x86_64.RPM
Przed zainstalowaniem klastra MultIode Hadoop dodaj klawisz Cloudera Public GPG do swojego repozytorium, uruchamiając jedno z następujących polecenia zgodnie z architekturą systemu.
## w systemie 32-bitowym ## # rpm -Import http: // archiwum.Cloudera.COM/CDH4/REDHAT/6/i386/CDH/RPM-GPG-KLEY-CLUDERA
## w systemie 64-bitowym ## # rpm -Import http: // archiwum.Cloudera.COM/CDH4/REDHAT/6/x86_64/CDH/RPM-GPG-KLEY-CLOUDERA
Krok 2: konfiguracja JobTracker i Namenode
Następnie uruchom następujące polecenie, aby zainstalować i skonfiguruj JobTracker i Namenode na serwerze głównym.
[[e-mail chroniony] ~]# Yum Clean All [[[e-mail chroniony] ~]# Yum Instal instaluj hadoop-0.20-MAPREDUCE-JOBTRACKER
[[e-mail chroniony] ~]# Yum Clean All [[[chroniony e-mail] ~]# Yum instaluj hadoop-hdfs-namenode
Krok 3: Węzeł Nazwa drugorzędnego ustawienia
Ponownie uruchom następujące polecenia na serwerze głównym, aby skonfigurować dodatkowy węzeł nazwy.
[[e-mail chroniony] ~]# Yum Clean All [[[e-mail chroniony] ~]# Yum Instal instaluj hadoop-hdfs-secondarynam
Krok 4: konfiguruj TaskTracker i DataNode
Następnie skonfiguruj TaskTracker i DataNode na wszystkich hostach klastrów (węzeł), z wyjątkiem hostów Namenode i Secondary (lub Standby) Namenode (w tym przypadku).
[[e-mail chroniony] ~]# Yum Clean All [[[e-mail chroniony] ~]# Yum Instal instaluj hadoop-0.20-MAPREDUCE-TAKTRACKER HADOOP-HDFS-DATANODE
Krok 5: Ustawienie klienta Hadoop
Możesz zainstalować klienta Hadoop na osobnym komputerze (w tym przypadku zainstalowałem go w DataNode, możesz go zainstalować na dowolnym komputerze).
[[e-mail chroniony] ~]# mniam instalacja hadoop-client
Krok 6: Wdrażaj HDFS na węzłach
Teraz, jeśli skończymy z powyższymi krokami, przejdźmy naprzód, aby wdrożyć HDF (do zrobienia na wszystkich węzłach).
Skopiuj domyślną konfigurację do /etc/hadoop katalog (na każdym węźle w klastrze).
[[e -mail chroniony] ~]# cp -r/etc/hadoop/conf.dist/etc/hadoop/conf.my_cluster
[[e -mail chroniony] ~]# cp -r/etc/hadoop/conf.dist/etc/hadoop/conf.my_cluster
Używać alternatywy polecenie, aby ustawić niestandardowy katalog, w następujący sposób (w każdym węźle w klastrze).
[[e-mail chroniony] ~]# alternatywy --verbose--install/etc/hadoop/conf hadoop-conf/etc/hadoop/conf.my_cluster 50 Reading/var/lib/alternatives/hadoop-conf [[e-mail chroniony] ~]# alternatywy-Set Hadoop-conf/etc/hadoop/conf.my_cluster
[[e-mail chroniony] ~]# alternatywy --verbose--install/etc/hadoop/conf hadoop-conf/etc/hadoop/conf.my_cluster 50 Reading/var/lib/alternatives/hadoop-conf [[e-mail chroniony] ~]# alternatywy-Set Hadoop-conf/etc/hadoop/conf.my_cluster
Krok 7: Dostosowywanie plików konfiguracyjnych
Teraz otwarte 'Site Core.XML„Plik i aktualizacja”fs.defaultfs”Na każdym węźle w klastrze.
[[chroniony e-mail] conf]# cat/etc/hadoop/conf/rdzeń.XML
fs.defaultfs hdfs: // master/
[[chroniony e-mail] conf]# cat/etc/hadoop/conf/rdzeń.XML
fs.defaultfs hdfs: // master/
Następna aktualizacja „DFS.uprawnienia.Superusergroup" W Site HDFS.XML na każdym węźle w klastrze.
[[[chroniony e-mail] conf]# cat/etc/hadoop/conf/hdfs-site.XML
DFS.nazwa.reż /var/lib/hadoop-hdfs/cache/hdfs/dfs/nazwa DFS.uprawnienia.Superusergroup Hadoop
[[[chroniony e-mail] conf]# cat/etc/hadoop/conf/hdfs-site.XML
DFS.nazwa.reż /var/lib/hadoop-hdfs/cache/hdfs/dfs/nazwa DFS.uprawnienia.Superusergroup Hadoop
Notatka: Upewnij się, że powyższa konfiguracja jest obecna we wszystkich węzłach (zrób w jednym węźle i uruchom SCP skopiować resztę węzłów).
Krok 8: Konfigurowanie lokalnych katalogów pamięci
Aktualizacja „DFS.nazwa.Dir lub DFS.Namenode.nazwa.Dir ”w„ HDFS Site.xml 'na nazwie (na mistrzu i węźle). Zmień wartość zgodnie z wyróżnieniem.
[[[chroniony e-mail] conf]# cat/etc/hadoop/conf/hdfs-site.XML
DFS.Namenode.nazwa.reż Plik: /// data/1/dfs/nn,/nfsmount/dfs/nn
[[[chroniony e-mail] conf]# cat/etc/hadoop/conf/hdfs-site.XML
DFS.DataNode.dane.reż Plik: /// data/1/dfs/dn,/data/2/dfs/dn,/data/3/dfs/dn
Krok 9: Utwórz katalogi i zarządzaj uprawnieniami
Wykonaj poniższe polecenia, aby utworzyć strukturę katalogu i zarządzać uprawnieniami użytkownika na komputerze Namenode (Master) i DataNode (Node).
[[chroniony e -mail]]# mkdir -p/data/1/dfs/nn/nfsmount/dfs/nn [[chroniony e -mail]]# chmod 700/data/1/dfs/nn/nfsmount/dfs/nn
[[chroniony e -mail]]# mkdir -p/data/1/dfs/dn/data/2/dfs/dn/data/3/dfs/dn/data/4/dfs/dn [[chroniony e -mail]]# chown -R HDFS: HDFS/Data/1/dfs/nn/nfsmount/dfs/nn/data/1/dfs/dn/data/2/dfs/dn/data/3/dfs/dn/dane/4/dfs/4/dfs/4/dfs/4/dfs/4/dfs/4/dfs/4/dfs/4/dfs/4/dfs/4/dfs/ Dn
Sformatuj nazewnik (na mistrzu), wydając następujące polecenie.
[[e -mail chroniony] conf]# sudo -u hdfs hdfs namenode -Format
Krok 10: Konfigurowanie wtórnego nazwy nazewniczej
Dodaj następującą właściwość do Site HDFS.XML plik i wymień wartość, jak pokazano na Master.
DFS.Namenode.HTTP-Address 172.21.17.175: 50070 Adres i port, na którym będzie słuchać interfejsu użytkownika nazwy.
Notatka: W naszym przypadku wartość powinna być adresem IP Master VM.
Teraz wdrożymy MRV1 (wersja Map-Reduce 1). Otwarty 'Mapred.XML„Plik następujący wartości, jak pokazano.
[[e-mail chroniony] conf]# CP HDFS SITE.XML Mapred Site.XML [[[e-mail chroniony] conf]# vi Mapred-Site.XML [[[e-mail chroniony] conf]# Cat Mapred-Site.XML
Mapred.stanowisko.Tracker Master: 8021
Następnie skopiuj 'Mapred.XML„Plik do maszyny do węzła za pomocą następujące polecenie SCP.
[[chroniony e-mail] conf]# scp/etc/hadoop/conf/mapred-site.węzeł xml:/etc/hadoop/conf/mapred-wiór.XML 100% 200 0.2KB/s 00:00
Teraz skonfiguruj lokalne katalogi pamięci do użycia przez Demony MRV1. Ponownie otwórz 'Mapred.XML„Złóż i wprowadzaj zmiany, jak pokazano poniżej dla każdego zadań.
 Mapred.lokalny.Dir â/Data/1/Mapred/Local,/Data/2/Mapred/Local,/Data/3/Mapred/Local
Po określaniu tych katalogów w 'Mapred.XML„Plik, musisz utworzyć katalogi i przypisać im prawidłowe uprawnienia pliku w każdym węźle w klastrze.
mkdir -p/data/1/mapred/local/data/2/mapred/local/data/3/mapred/local/data/4/mapred/local chown -r MapreD: Hadoop/data/1/mapred/local/local/ Data/2/Mapred/Local/Data/3/Mapred/Local/Data/4/Mapred/Local
Krok 10: Rozpocznij HDFS
Teraz uruchom następujące polecenie, aby uruchomić HDFS w każdym węźle w klastrze.
[[e -mail chroniony] conf]# dla x in 'cd /etc /init.D ; ls hadoop-hdfs-*'; Do Sudo Service $ x start; zrobione
[[e -mail chroniony] conf]# dla x in 'cd /etc /init.D ; ls hadoop-hdfs-*'; Do Sudo Service $ x start; zrobione
Krok 11: Utwórz katalogi HDF /TMP i MapReduce /Var
Jest wymagane do stworzenia /TMP z odpowiednimi uprawnieniami dokładnie jak wspomniano poniżej.
[[[e -mail chroniony] conf]# sudo -u hdfs hadoop fs -mkdir /tmp [[e -mail chroniony] conf]# sudo -u hdfs hadoop fs -Chmod -r 1777 /tmp
[[[e -mail chroniony] conf]# sudo -u hdfs hadoop fs -mkdir -p/var/lib/hadoop -hdfs/cache/mapred/mapre/inscenizacja [[chroniona e -mail] conf]# sudo -u hdfs hadf fs -chmod 1777/var/lib/hadoop -hdfs/cache/mapred/mapred/standing [[e -mail chroniony] conf]# sudo -u hdfs hadfs fs -Chown -r MapreD/var/lib/hadoop -hdfs/cache/mapred
Teraz sprawdź strukturę pliku HDFS.
[[chroniony e-mail] ODE CONF]# sudo -u hdfs hadoop fs -ls -r / drwxrwxrwt-HDFS Hadoop 0 2014-05-29 09:58 / tmp Drwxr-xr-x-HDFS Hadoop 0 2014-05-29 09 09 : 59 /var Drwxr-xr-x-HDFS Hadoop 0 2014-05-29 09:59 /var /lib Drwxr-xr-x-HDFS Hadoop 0 2014-05-29 09:59 /var /lib /hadoop-hdfs DRWXR-XR-X-HDFS Hadoop 0 2014-05-29 09:59/var/lib/hadoop-hdfs/cache drwxr-xr-x-Mapred Hadoop 0 2014-05-29 09:59/var/lib/hadoop/hadoop/hadoop -HDFS/Cache/MapRed DRWXR-XR-X-MAPRED HADOOP 0 2014-05-29 09:59/var/lib/hadoop-hdfs/cache/mapred/mapred drwxrwxrwt-Mapred Hadoop 0 2014-05-29 09:59 /var/lib/hadoop-hdfs/cache/mapred/mapred/standing
Po uruchomieniu HDFS i utworzeniu '/TMP', ale przed uruchomieniem JobTracker Utwórz katalog HDFS określony przez „Mapred.system.Dir 'Parametr (domyślnie $ hadoop.TMP.Dir/Mapred/System i zmień właściciela na Mapred.
[[[chroniony e -mail] conf]# sudo -u hdfs hadoop fs -mkdir/tmp/mapred/system [[chroniony e -mail] conf]# sudo -u hdfs hdfs fs -Chown Mapred: hadoop/tmp/mapreD/System
Krok 12: Rozpocznij MapReduce
Aby uruchomić MapReduce: Uruchom usługi TT i JT.
W każdym systemie zadań
[[[chroniony e-mail] conf]# Service Hadoop-0.20-MapReduce-TaskTracker Rozpocznij rozpoczęcie zadań: [OK] Uruchamianie TaskTracker, logowanie do/var/log/hadoop-0.20-mapeduce/hadoop-hadoop-tasktracker-node.na zewnątrz
W systemie JobTracker
[[[chroniony e-mail] conf]# Service Hadoop-0.20-MAPREDUCE-JOBTRACKER Rozpocznij JobTracker: [OK] Rozpoczęcie pracy, logowanie do/var/log/hadoop-0.20-MAPREDUCE/HADOOP-HADOOP-JOBTRACKER-MASTER.na zewnątrz
Następnie utwórz katalog domowy dla każdego użytkownika Hadoop. Zaleca się, abyś to zrobił w Namenode; Na przykład.
[[[chroniony e -mail] conf]# sudo -u hdfs hadoop fs -mkdirâ /user /[[chroniony e -mail] conf]# sudo -u hdfs hadoop fs -Chown /User / /
Notatka: Gdzie to nazwa użytkownika Linux każdego użytkownika.
Alternatywnie, możesz w następujący sposób katalog domowy.
[[[chroniony e -mail] conf]# sudo -u hdfs hadoop fs -mkdir /użytkownik /$ użytkownik [[chroniony e -mail] conf]# sudo -u hdfs hadoop fs -Chown $ użytkownik /użytkownik /$ użytkownik
Krok 13: Otwórz JT, NN UI z przeglądarki
Otwórz przeglądarkę i wpisz adres URL http: // ip_address_of_namenode: 50070 Aby uzyskać dostęp do Namenode.
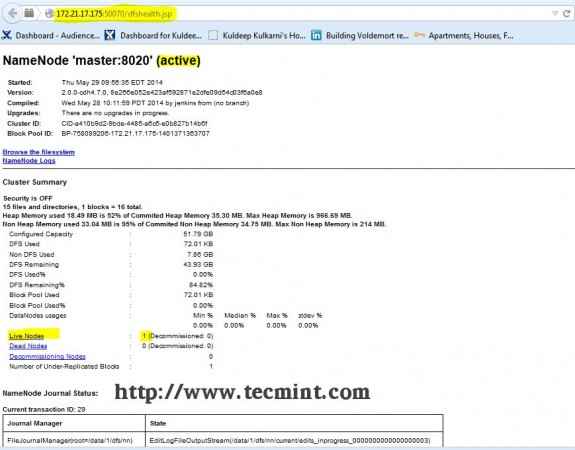 Interfejs Hadoop Namenode
Interfejs Hadoop Namenode Otwórz kolejną zakładkę w przeglądarce i wpisz adres URL jako http: // ip_address_of_jobtracker: 50030 Aby uzyskać dostęp do Jobtrackera.
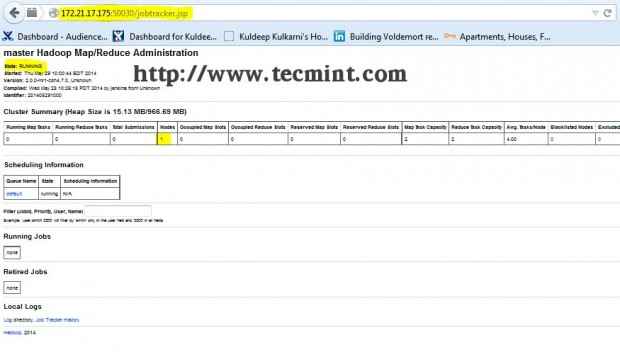 Hadoop Map/Redact Administration
Hadoop Map/Redact Administration Ta procedura została pomyślnie przetestowana RHEL/CENTOS 5.X/6.X. Proszę o komentarz poniżej, jeśli napotkasz jakiekolwiek problemy z instalacją, pomogę Ci z rozwiązaniami.
- « Utwórz własną stronę udostępniania wideo za pomocą „Cumulusclips Script” w Linux
- Tworzenie wirtualnych hostów, generuj certyfikaty i klucze SSL i włącz bramę CGI w Gentoo Linux »