

Wstęp

- 2279
- 597
- Pan Jeremiasz Więcek
31 lipca 2009
Pierre Vignéras
Abstrakcyjny:
Jak zapewne wiesz, Linux obsługuje różne systemy plików, takie jak Ext2, Ext3, Ext4, XFS, Reiserfs, JFS. Niewielu użytkowników naprawdę rozważa tę część systemu, wybierając domyślne opcje instalatora ich dystrybucji. W tym artykule podam kilka powodów, aby lepiej rozważyć system plików i jego układ. Zasugeruję proces najwyższej jakości do zaprojektowania „inteligentnego” układu, który z czasem pozostaje tak stabilny, jak to możliwe dla danego zużycia komputera.Wstęp
Pierwsze pytanie, które możesz zadać, jest dlaczego tak wiele systemów plików i jakie są ich różnice, jeśli w ogóle? Po to, aby było to krótkie (szczegółowe informacje patrz Wikipedia):
- ext2: To znaczy Linux FS, który został specjalnie zaprojektowany dla Linuksa (pod wpływem Ext i Berkeley FFS). Pro: Fast; Minusy: nie dziennikarskie (długi FSCK).
- ext3: naturalne rozszerzenie ext2. Pro: Kompatybilny z ext2, dziennikarz; Minusy: wolniej niż ext2, jak wielu konkurentów, dziś przestarzały.
- ext4: Ostatnie rozszerzenie rodziny ext. Pro: kompatybilność rosnąca z ext3, duży rozmiar; Dobra wydajność odczytu; Minus: trochę za najnowsze, aby wiedzieć?
- JFS: IBM AIX FS przeniesiony do Linux. Pro: dojrzałe, szybkie, lekkie i niezawodne, duży rozmiar; Minus: Wciąż rozwinięty?
- XFS: SGI Irix FS przeniesiony do Linux. Pro: Bardzo dojrzałe i niezawodne, dobra średnia wydajność, duży rozmiar, wiele narzędzi (takich jak defragmenter); Minus: Brak, o ile wiem.
- Reiserfs: alternatywa dla systemu plików ext2/3 w systemie Linux. Pro: Szybka dla małych plików; Minus: Wciąż rozwinięty?
Istnieją inne systemy plików, w szczególności nowe, takie jak BTRFS, ZFS i NILFS2, które również mogą wydawać się bardzo interesująco. Zajmiemy się nimi później w tym artykule.
Więc teraz pytanie brzmi: który system plików jest najbardziej odpowiedni dla Twojej konkretnej sytuacji? Odpowiedź nie jest prosta. Ale jeśli tak naprawdę nie wiesz, jeśli masz jakieś wątpliwości, polecam XFS z różnych powodów:
- Ogólnie rzecz biorąc, działa bardzo dobrze, a zwłaszcza na współbieżnym odczycie/zapisie (patrz punkt odniesienia);
- Jest bardzo dojrzały i dlatego został szeroko przetestowany i dostrojony;
- Przede wszystkim ma świetne funkcje, takie jak XFS_FSR, łatwy w użyciu defragmenter (po prostu zrób LN -sf $ (który xfs_fsr) /etc /cron.Codziennie/defrag i zapomnij o tym).
Jedynym problemem, jaki widzę w XFS, jest to, że nie można zmniejszyć XFS FS. Możesz wyhodować partycję XFS, nawet po zamontowaniu i w aktywnym użyciu (gorąco), ale nie można zmniejszyć jego rozmiaru. Dlatego jeśli masz jakieś redukujące potrzeby systemu plików, wybierz inny system plików, taki jak ext2/3/4 lub reiserfs (o ile wiem, nie możesz i tak nie można zredukować ext3 ani reiserfs-systemy plików). Inną opcją jest utrzymanie XFS i zawsze zaczynanie od małego rozmiaru partycji (jak zawsze możesz później gorący czas).
Jeśli masz komputer o niskim profilu (lub serwer plików) i jeśli naprawdę potrzebujesz procesora na coś innego niż radzenie sobie z operacją wejściową/wyjściową, sugerowałbym JFS.
Jeśli masz wiele katalogów lub/i małych plików, Reiserfs może być opcją.
Jeśli potrzebujesz wydajności za wszelką cenę, sugeruję ext2.
Szczerze mówiąc, nie widzę żadnego powodu wyboru ext3/4 (wydajność? Naprawdę?).
To jest dla wyboru systemu plików. Ale drugim pytaniem jest, w jakim ukształtowaniu powinienem użyć? Dwie partycje? Trzy? Dedykowany /dom /? Tylko czytać /? Oddziel /TMP?
Oczywiście nie ma jednej odpowiedzi na to pytanie. Należy wziąć pod uwagę wiele czynników, aby dokonać dobrego wyboru. Najpierw zdefiniuję te czynniki:
- Złożoność: Jak złożony jest układ na całym świecie;
- Elastyczność: Jak łatwo jest zmienić układ;
- Wydajność: Jak szybko układ pozwala systemowi działać.
Znalezienie idealnego układu to kompromis między tymi czynnikami.
Domyślny układ
Często użytkownik końcowy z niewielką wiedzą na temat Linuxa podąża za domyślnymi ustawieniami swojej dystrybucji, w których (zwykle) tylko dwie lub trzy partycje są wykonane dla Linux, z głównym systemem plików ' /', /boot i zamiany. Zalety takiej konfiguracji to prostota. Głównym problemem jest to, że ten układ nie jest ani elastyczny, ani wykonujący.
Brak elastyczności
Brak elastyczności jest oczywisty z wielu powodów. Po pierwsze, jeśli użytkownik końcowy chce innego układu (na przykład chce zmienić rozmiar systemu plików root lub chce użyć osobnego systemu plików /tmp), będzie musiał ponownie uruchomić system i skorzystać z oprogramowania do partycjonowania (Na przykład z LiveCD). Będzie musiał zająć się swoimi danymi, ponieważ ponowne podział jest operacją o brutalnej sile, o której system operacyjny nie jest świadomy.
Ponadto, jeśli użytkownik końcowy chce dodać pamięć (na przykład nowy dysk twardy), ostatecznie zmodyfikuje układ systemu (/etc/fstab), a po pewnym czasie jego system będzie po prostu zależeć od leżącego u podstaw układu pamięci masowej (liczba i lokalizacja dysków twardych, partycji i tak dalej).
Nawiasem mówiąc, posiadanie osobnych partycji dla danych (/dom, ale także wszystkie audio, wideo, baza danych,…) znacznie ułatwia zmianę systemu (na przykład z jednego dystrybucji Linux na inny). Sprawia również, że udostępnianie danych między systemami operacyjnymi (BSD, OpenSolaris, Linux, a nawet Windows) łatwiej i bezpieczniejsze. Ale to kolejna historia.
Dobrą opcją jest użycie logicznego zarządzania woluminami (LVM). LVM rozwiązuje problem elastyczności w bardzo dobry sposób, jak zobaczymy. Dobra wiadomość jest taka, że większość nowoczesnych dystrybucji obsługuje LVM, a niektóre z nich używają domyślnie. LVM dodaje warstwę abstrakcyjną na sprzęcie, usuwając twarde zależności między systemem operacyjnym (/etc/fstab) a podstawowymi urządzeniami pamięci (/dev/hDA,/dev/sda i inne). Oznacza to, że możesz zmienić układ przechowywania - dodawanie i usuwanie dysków twardych - bez zakłócania systemu. O ile mi wiadomo, głównym problemem LVM jest to, że możesz przeczytać wolumin LVM z innych systemów operacyjnych.
Brak wydajności.
Niezależnie od systemu plików (ext2/3/4, XFS, Reiserfs, JFS), nie jest idealny do wszelkiego rodzaju danych i wzorców użytkowania (aka obciążenia). Na przykład wiadomo, że XFS jest dobry w obsłudze dużych plików, takich jak pliki wideo. Z drugiej strony, Reiserfs jest znany jako wydajny w obsłudze małych plików (takich jak pliki konfiguracyjne w katalogu domowym lub w /etc). Dlatego posiadanie jednego systemu plików dla wszelkiego rodzaju danych i użycia jest zdecydowanie nie optymalne. Jedyną dobrą kwestią w tym układzie jest to, że jądro nie musi obsługiwać wielu różnych systemów plików, dlatego zmniejsza ilość pamięci, której jądro używa do swojego minimum (jest to również prawdą w przypadku modułów). Ale jeśli nie skupimy się na systemach osadzonych, uważam ten argument za nieistotne z dzisiejszymi komputerami.
Wybór właściwej rzeczy: podejście najwyższej jakości
Często, gdy system jest zaprojektowany, zwykle odbywa się on w podejściu od góry do góry: sprzęt jest kupowany zgodnie z kryteriami, które nie są powiązane z ich użyciem. Następnie układ systemu plików jest zdefiniowany zgodnie z tym sprzętem: „Mam jeden dysk, mogę go podzielić w ten sposób, ta partycja pojawi się tam, druga tam i tak dalej”.
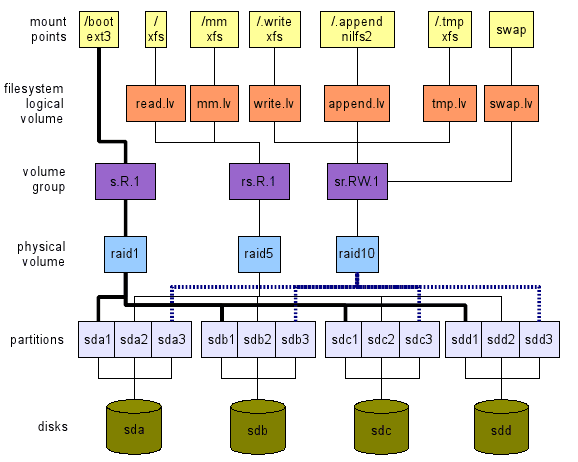
Proponuję odwrotne podejście. Definiujemy to, czego chcemy na wysokim poziomie. Następnie podróżujemy warstwami od góry do dołu, do prawdziwego sprzętu - urządzenia pamięci masowej w naszym przypadku - jak pokazano na rysunku 1. Ta ilustracja jest tylko przykładem tego, co można zrobić. Istnieje wiele opcji, jak zobaczymy. Następne sekcje wyjaśnią, w jaki sposób możemy dojść do takiego globalnego układu.
Rysunek 1: Przykład układu systemu plików. Zauważ, że dwie partycje pozostają bezpłatne (SDB3 i SDC3). Mogą być używane do /rozruchu, do wymiany lub obu. Nie „kopiuj/wklej” ten układ. Nie jest zoptymalizowany pod kątem obciążenia pracą. To tylko przykład.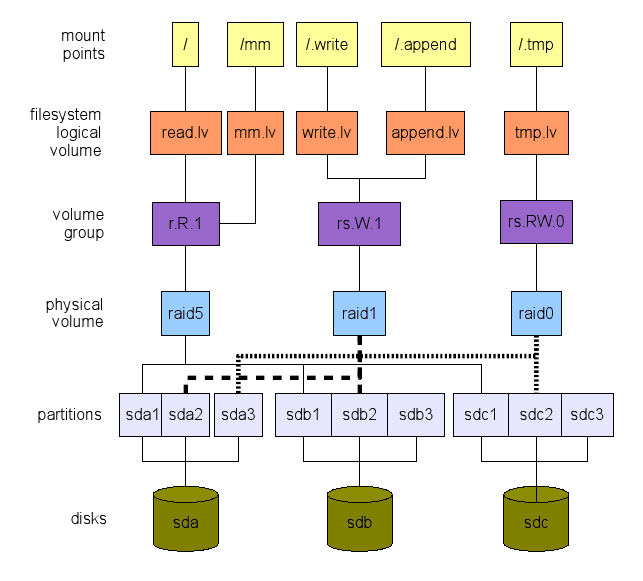
Kupowanie odpowiedniego sprzętu
Przed zainstalowaniem nowego systemu należy rozważyć użycie docelowe. Najpierw z punktu widzenia sprzętu. Czy jest to system osadzony, komputer stacjonarny, serwer, komputer wielozadaniowy (z telewizorem/audio/video/openOffice/Web/Chat/P2p,…)?
Jako przykład, zawsze polecam użytkowników końcowych z prostymi potrzebami komputerowymi (sieć, poczta, czat, kilka oglądania mediów), aby kupić tanie procesor (najtańszy), dużo pamięci RAM (maksimum) i co najmniej dwa dyski twarde.
W dzisiejszych czasach nawet najtańszy procesor jest wystarczający do surfowania w sieci i oglądaniu filmów. Dużo pamięci RAM zapewnia dobrą pamięć podręczną (Linux używa bezpłatnej pamięci do buforowania - zmniejszanie ilości kosztownego wejścia/wyjścia do urządzeń do przechowywania). Nawiasem mówiąc, zakup maksymalnej ilości pamięci RAM może wspierać płytę główną to inwestycja z dwóch powodów:
- Aplikacje wymagają coraz większej pamięci; Dlatego posiadanie maksymalnej ilości pamięci już uniemożliwia później dodawanie pamięci przez chwilę;
- Technologia zmienia się tak szybko, że system może nie obsługiwać pamięci dostępnej za 5 lat. W tym czasie zakup starej pamięci będzie prawdopodobnie dość drogi.
Posiadanie dwóch dysków twardych pozwala na użycie w lustrze. Dlatego jeśli ktoś zawiedzie, system będzie nadal działał normalnie i będziesz miał czas na uzyskanie nowego dysku twardego. W ten sposób twój system pozostanie dostępny, a dane, całkiem bezpieczne (to nie wystarczy, wykonuje kopię zapasową danych).
Definiowanie wzorca użytkowania
Wybierając sprzęt, a konkretnie układ systemu plików, należy rozważyć aplikacje, które z niego użyją. Różne aplikacje mają różne obciążenie wejściowe/wyjściowe. Rozważ następujące aplikacje: loggery (syslog), czytniki pocztowe (Thunderbird, Kmail), wyszukiwarka (beagle), baza danych (MySQL, PostgreSQL), P2P (emule, gnutela, vuze), powłoki (Bash)… /Wzory wyjściowe i o ile różnią się?
Dlatego definiuję następującą abstrakcyjną lokalizację pamięci znaną jako objętość logiczna - LV - w terminologii LVM:
- TMP.LV:
- W przypadku danych tymczasowych, takich jak te znalezione w/tmp,/var/tmp, a także w katalogu domowym każdego użytkownika $ home/tmp (pamiętaj, że katalogi śmieci, takie jak $ home/trash, $ home/.Śmieci mogą być również tutaj zmapowane. Implikacje można znaleźć w specyfikacji śmieci Freedesktop). Innym kandydatem jest /var /cache. Ideą tego logicznego woluminu jest to, że możemy go nadmiernie dostroić do wydajności i możemy zaakceptować nieco utraty danych, ponieważ dane te nie są niezbędne dla systemu (szczegółowe informacje na temat tych lokalizacji znajdują się w systemie (FHS) na temat tych lokalizacji).
- Czytać.LV:
- W przypadku danych, które są głównie odczytywane jak większość plików binarnych w /bin, /usr /bin, /lib, /usr /lib, pliki konfiguracyjne w /etc i większość plików konfiguracyjnych w każdym katalogu użytkownika $ home /.bashrc i tak dalej. To miejsce przechowywania można dostroić w celu odczytania. Możemy zaakceptować słabą wydajność pisania, ponieważ występują one rzadko (e.G: Podczas aktualizacji systemu). Utrata danych tutaj jest wyraźnie niedopuszczalna.
- pisać.LV:
- dla danych, które są w większości zapisane w losowo, takie jak dane zapisane przez aplikacje P2P lub bazy danych. Możemy dostroić go do wydajności zapisu. Zauważ, że wydajność odczytu nie może być zbyt niska: zarówno aplikacje P2P, jak i bazy danych odczytują losowo i dość często dane, które piszą. Możemy uznać tę lokalizację jako lokalizację „uniwersalną”: jeśli tak naprawdę nie znasz wzorca użytkowania danej aplikacji, skonfiguruj ją, aby używa tego logicznego woluminu. Utrata danych tutaj jest również niedopuszczalne.
- dodać.LV:
- dla danych, które są w większości napisane w sposób sekwencyjny, jak dla większości plików w/var/log, a także $ home/.Xsession-Errors między innymi. Możemy go dostroić do dostosowania wydajności, która może być zupełnie inna niż wydajność losowego zapisu. Tam wydajność odczytu zwykle nie jest tak ważna (chyba że masz oczywiście określone potrzeby). Utrata danych tutaj jest nie do przyjęcia do normalnych zastosowań (Log daje informacje o problemach. Jeśli stracisz dzienniki, skąd możesz wiedzieć, jaki był problem?).
- mm.LV:
- dla plików multimedialnych; Ich sprawa jest nieco wyjątkowa, ponieważ zwykle są duże (wideo) i czytane sekwencyjnie. Tuning dla sekwencyjnego odczytu można zrobić tutaj. Pliki multimedialne są zapisywane raz (na przykład z zapisu.LV, gdzie aplikacje P2P piszą do MM.LV) i czytaj wiele razy sekwencyjnie.
Możesz dodać/sugerować inne kategorie tutaj z różnymi wzorami, takimi jak sekwencyjna.Czytać.na przykład LV.
Definiowanie punktów montażowych
Załóżmy, że mamy już wszystkie te abstrakcyjne lokalizacje przechowywania w postaci/dev/tbd/lv gdzie:
- TBD to grupa woluminów, którą należy zdefiniować później (patrz 3.5);
- LV jest jednym z woluminów logicznych, które właśnie zdefiniowaliśmy w poprzedniej sekcji (czytaj.LV, TMP.LV,…).
Więc przypuszczamy, że mamy już/dev/tbd/tmp.lv,/dev/tbd/odczyt.lv,/dev/tbd/zapisz.lv i tak dalej.
Nawiasem mówiąc, uważamy, że każda grupa woluminów jest zoptymalizowana pod kątem wzorca użytkowania (znaleziono kompromis między wydajnością a elastycznością).
Dane tymczasowe: TMP.lv
Chcielibyśmy mieć/tmp,/var/tmp i dowolne $ home/tmp wszystkie zmapowane na/dev/tbd/tmp.lv.
To, co sugeruję, to następujące:
- Mount/dev/tbd/tmp.LV do A /.TMP ukryty katalog na poziomie głównym; W /etc /fstab, będziesz miał coś takiego (oczywiście, ponieważ grupa woluminów jest nieznana, to nie zadziała; chodzi o wyjaśnienie tego procesu tutaj.):
# Wymień auto przez prawdziwy system plików, jeśli chcesz # Wymień domyślne 0 2 na własne potrzeby (Man fstab)/dev/tbd/tmp.lv /.TMP Auto Domyślnie 0 2
- powiązać inne lokalizacje z katalogiem w /.TMP. Załóżmy na przykład, że nie obchodzi Cię osobne katalogi dla /tmp i /var /tmp (patrz FHS dla implikacji), możesz po prostu utworzyć katalog all_tmp wewnątrz /dev /tbd /tmp.LV i powiązaj go z /TMP i /var /tmp. W /etc /fstab, dodaj te linie:
/.tmp /all_tmp /tmp Brak Bind 0 0 /.tmp/all_tmp/var/tmp Brak powiązanie 0 0
Oczywiście, jeśli wolisz dostosować się do FHS, nie ma problemu. Utwórz dwa odrębne katalogi FHS_TMP i FHS_VAR_TMP w TMP.Objętość LV i dodaj te linie:
/.tmp /fhs_tmp /tmp Bone BRED 0 0 /.tmp/fhs_var_tmp/var/tmp Brak
- Zrób symLink dla katalogu TMP użytkownika do /tmp /użytkownika. Na przykład $ home/tmp to symboliczny link do/tmp/$ user_name/tmp (używam środowiska KDE, dlatego mój $ home/tmp jest symbolicznym linkiem do/tmp/kde-$ użytkownika, więc wszystkie aplikacje KDE Użyj tego samego LV). Możesz zautomatyzować ten proces za pomocą niektórych linii w swoim .bash_profile (lub nawet w/etc/skel/.bash_profile, aby każdy nowy użytkownik go miał). Na przykład:
Jeśli test ! -e $ home/tmp -a ! -e /tmp /kde-$ użytkownik; następnie mkdir /tmp /kde-$ użytkownik; ln -s/tmp/kde -$ użytkownik $ home/tmp; fi
(Ten skrypt jest raczej prosty i działa tylko w przypadku, gdy zarówno $ home/tmp i/tmp/kde-$ użytkownik. Możesz dostosować go do własnej potrzeby.)
Głównie odczytu dane: odczyt.lv
Ponieważ system plików root zawiera /etc, /bin, /usr /bin i tak dalej, są idealne do odczytania.lv. Dlatego w /etc /fstab umieściłbym następujące:
/dev/tbd/odczyt.LV / AUTO Wartość domyślna 0 1
W przypadku plików konfiguracyjnych w katalogach domowych użytkowników rzeczy nie są tak proste, jak można się domyślić. Można spróbować użyć zmiennej środowiska XDG_Config_Home (patrz Freedesktop)
Ale nie poleciłbym tego rozwiązania z dwóch powodów. Po pierwsze, niewiele aplikacji faktycznie jest do niego zgodnych (domyślna lokalizacja to $ home/.konfigurować, gdy nie ustawia się jawnie). Po drugie, jeśli ustawisz xdg_config_home na odczyt.Subrectory LV, użytkownicy końcowi będą mieli problem z znalezieniem plików konfiguracyjnych. Dlatego w tym przypadku nie mam żadnego dobrego rozwiązania i zrobię domowe katalogi i wszystkie pliki konfiguracyjne przechowywane do ogólnego zapisu.Lokalizacja LV.
Głównie pisemne dane: napisz.lv
W takim przypadku odtworzę jakiś sposób zastosowany do TMP.lv. Będę powiązać różne katalogi dla różnych aplikacji. Na przykład będę miał w FSTAB coś podobnego do tego:
/dev/tbd/zapisz.lv /.Napisz Auto Domyślnie 0 2 /.zapis /db /db Brak Bind 0 0 /.zapis /p2p /p2p Brak Bind 0 0 /.Write /Home /Home Brak Bind 0 0
Oczywiście to załóżmy, że katalogi DB i P2P zostały stworzone w Write.lv.
Zauważ, że być może będziesz musiał być świadomy dostępu do praw. Jedną z opcji jest zapewnienie tych samych praw niż dla /TMP, w których każdy może pisać /czytać własne dane. Osiąga to na przykład następujące polecenie Linux: CHMOD 1777 /P2P.
Głównie dołącz dane: dołącz.lv
Ten wolumin został dostrojony do aplikacji w stylu rejestratorów, takich jak Syslog (i jego warianty na przykład syslog_ng) i wszelkich innych rejestratorów (na przykład loggery Java). /Etc /fstab powinien być podobny do tego:
/dev/tbd/dodatek.lv /.dołącz Auto Domyślnie 0 2 /.append /syslog /var /log Bone Bind 0 0 /.append/Ulog/var/Ulog None Bind 0 0
Ponownie, Syslog i Ulog to katalogi wcześniej utworzone w załączniku.lv.
Dane multimedialne: MM.lv
W przypadku plików multimedialnych po prostu dodam następujący wiersz:
/dev/tbd/mm.LV /mm Auto domyślnie 0 2
Wewnątrz /mm tworzę zdjęcia, audios i filmy. Jako użytkownik komputerów stacjonarnych zwykle udostępniam swoje pliki multimedialne innym członkom rodziny. Dlatego prawa dostępu powinny być prawidłowo zaprojektowane.
Możesz preferować odrębne objętości plików zdjęć, audio i wideo. Zapraszam do odpowiednio tworzenia logicznych woluminów: Zdjęcia.LV, audios.LV i filmy.lv.
Inni
Możesz dodać własne logiczne tomy zgodnie z potrzebami. Logiczne tomy są całkiem bezpłatne. Nie dodają dużych kosztów ogólnych i zapewniają dużą elastyczność, pomagając wyjąć najwięcej systemu, szczególnie przy wyborze odpowiedniego systemu plików do obciążenia pracą.
Definiowanie systemów plików dla woluminów logicznych
Teraz, gdy nasze punkty Mount i nasze logiczne tomy zostały zdefiniowane zgodnie z naszymi wzorcami użytkowania aplikacji, możemy wybrać system plików dla każdego logicznego tomu. I tutaj mamy wiele możliwości, jak już widzieliśmy. Przede wszystkim masz sam system plików (e.G: ext2, ext3, ext4, reiserfs, xfs, jfs i tak dalej). Dla każdego z nich masz również ich parametry strojenia (takie jak strojenie rozmiar bloku, liczba inod, opcje dziennika (XFS) i tak dalej). Wreszcie, podczas montażu możesz również określić różne opcje zgodnie z pewnym wzorem użytkowania (Noatime, Data = Writeback (ext3), bariera (xfs) i tak dalej). Dokumentacja systemu plików powinna być odczytana i zrozumiana, aby można było mapować opcje do prawidłowego wzoru użytkowania. Jeśli nie masz pojęcia, które FS użyć w jakim celu, oto moje sugestie:
- TMP.LV:
- Ten tom będzie zawierać wiele danych, pisanych/odczytanych przez aplikacje i użytkowników, małe i duże. Bez żadnego zdefiniowanego wzorca użytkowania (głównie odczytu, głównie zapisu), użyłbym ogólnego systemu plików, takiego jak XFS lub ext4.
- Czytać.LV:
- Ten tom zawiera system plików głównych z wieloma binarami (/bin,/usr/bin), biblioteki (/lib,/usr/lib), wiele plików konfiguracji (/etc)… ponieważ większość jego danych jest odczytywana, plik plik -System może być tym z najlepszą wydajnością odczytu, nawet jeśli jego wydajność jest słaba. XFS lub ext4 to opcje tutaj.
- pisać.LV:
- Jest to raczej trudne, ponieważ ta lokalizacja jest ”dopasuj wszystkie”Lokalizacja powinna obsługiwać zarówno odczyt i pisać poprawnie. Ponownie XFS lub ext4 to także opcje.
- dodać.LV:
- Tam możemy wybrać system plików czystego dziennika, takiego jak nowy NILFS2 obsługiwany przez Linux.6.30, które powinny zapewnić bardzo dobrą wydajność zapisu (ale uważaj na jego ograniczenia (zwłaszcza bez wsparcia dla Atime, rozszerzonych atrybutów i ACL).
- mm.LV:
- zawiera pliki audio/wideo, które mogą być dość duże. To idealny wybór dla XFS. Zauważ, że w IRIX XFS obsługuje sekcję w czasie rzeczywistym dla aplikacji multimedialnych. To nie jest obsługiwane (jeszcze?) O ile mi wiadomo.
- Możesz grać za pomocą parametrów strojenia XFS (patrz Man XFS), ale wymaga dobrej wiedzy na temat twojego wzorca użytkowania i wewnętrznych XFS.
Na tym wysokim poziomie możesz również zdecydować, czy potrzebujesz wsparcia szyfrowania lub kompresji. Może to pomóc w wybraniu systemu plików. Na przykład dla MM.LV, kompresja jest bezużyteczna (ponieważ dane multimedialne są już skompresowane), podczas gdy może wydawać się przydatne dla /dom. Zastanów się również, jeśli potrzebujesz szyfrowania.
Na tym kroku wybraliśmy systemy plików dla wszystkich naszych logicznych woluminów. Czas ma teraz zejść do następnej warstwy i zdefiniować nasze grupy głośności.
Definiowanie grupy objętościowej (VG)
Następnym krokiem jest zdefiniowanie grup wolumenu. Na tym poziomie zdefiniujemy nasze potrzeby pod względem strojenia wydajności i tolerancji błędów. Proponuję zdefiniowanie VG zgodnie z następującym schematem: [R | S].[R | W].[n] gdzie:
- 'R' - oznacza losowe;
- 'S' - oznacza sekwencję;
- 'R' - oznacza odczyt;
- „W” - oznacza pismo;
- 'N' - jest pozytywną liczbą całkowitą, zerową.
Litery określają rodzaj optymalizacji, dla którego nazywane tom został dostrojony. Liczba daje abstrakcyjną reprezentację poziomu tolerancji usterki. Na przykład:
- R.R.0 oznacza zoptymalizowane pod kątem losowego odczytu z poziomem tolerancji usterki 0: Utrata danych zachodzi, gdy tylko jedno urządzenie pamięci pamięci (powiedział inaczej, system jest tolerancyjny dla 0 awarii urządzenia pamięci).
- S.W.2 oznacza zoptymalizowane pod kątem sekwencyjnego zapisu z poziomem tolerancji usterki 2: Utrata danych zachodzi, gdy tylko trzy urządzenia pamięci (powiedział inaczej, system jest tolerancyjny dla 2 awarii urządzeń pamięci).
Następnie musimy zmapować każdy wolumin logiczny do danej grupy woluminów. Sugeruję następujące czynności:
- TMP.LV:
- można zmapować na RS.RW.0 Grupa woluminów lub RS.RW.1 w zależności od twoich wymagań dotyczących tolerancji na usterki. Oczywiście, jeśli chcesz, aby Twój system pozostaje on on-line na zasadzie 24/24 godziny, 365 dni/rok, drugą opcję zdecydowanie należy wziąć pod uwagę. Niestety, tolerancja błędów ma koszt zarówno pod względem przestrzeni do przechowywania, jak i wydajności. Dlatego nie należy oczekiwać tego samego poziomu wydajności z RS.RW.0 VG i RS.RW.1 VG z tą samą liczbą urządzeń pamięci masowej. Ale jeśli możesz sobie pozwolić na ceny, istnieją rozwiązania dla dość wydajnych RS.RW.1, a nawet Rs.RW.2, 3 i więcej! Więcej o tym na następnym poziomie.
- Czytać.LV:
- może być zmapowane na r.R.1 VG (zwiększ liczbę tolerancyjną usterki, jeśli potrzebujesz);
- pisać.LV:
- może być zmapowane na r.W.1 VG (to samo);
- dodać.LV:
- może być zmapowane na s.W.1 VG;
- mm.LV:
- może być zmapowane na s.R.1 VG.
Oczywiście mamy oświadczenie „May”, a nie „konieczne”, ponieważ zależy to od liczby urządzeń pamięci, które można włożyć w równanie. Definiowanie VG jest w rzeczywistości dość trudne, ponieważ nie zawsze możesz całkowicie wyodrębnić podstawowy sprzęt. Ale uważam, że najpierw zdefiniowanie twoich wymagań może pomóc w zdefiniowaniu układu systemu pamięci masowej na całym świecie.
Zobaczymy na następnym poziomie, jak wdrożyć te grupy woluminów.
Definiowanie objętości fizycznych (PV)
Ten poziom to miejsce, w którym faktycznie wdraża dane wymagania grupy woluminów (zdefiniowane przy użyciu notacji RS.RW.n opisane powyżej). Mamy nadzieję, że nie ma - o ile mi wiadomo - wiele sposobów wdrażania wymagań VG. Możesz użyć niektórych funkcji LVM (lustrzanie, usuwanie), RAID Software (z Linux MD) lub RAID sprzętowy. Wybór zależy od twoich potrzeb i sprzętu. Nie polecam jednak nalotu sprzętowego (obecnie) dla komputera stacjonarnego lub nawet małego serwera plików, z dwóch powodów:
- Dość często (właściwie przez większość czasu), tak się nazywa sprzętowy RAID, to w rzeczywistości RAID Software: masz chipset na płycie głównej, który przedstawia tanie kontroler RAID, który wymaga pewnego oprogramowania (sterowników) do wykonania faktycznej pracy. Zdecydowanie Linux Raid (MD) jest znacznie lepszy zarówno pod względem wydajności (jak sądzę), jak i pod względem elastyczności (na pewno).
- O ile nie masz bardzo starego procesora (klasa Pentium II), Soft Raid nie jest tak kosztowny (właściwie nie jest to tak prawdziwe w przypadku RAID5, ale w przypadku RAID0, RAID1 i RAID10, to prawda)).
Więc jeśli nie masz pojęcia, jak wdrożyć daną specyfikację za pomocą RAID, zobacz dokumentację RAID.
Jednak kilka wskazówek:
- cokolwiek z .0 można zmapować na RAID0, która jest najbardziej wykonującą kombinacją RAID (ale jeśli jedno urządzenie pamięci, stracisz wszystko).
- S.R.1, r.R.1 i sr.R.1 można zmapować w kolejności preferencji na RAID10 (wymagane minimum 4 urządzeń pamięci (SD)), RAID5 (wymagane 3 SD), RAID1 (2 SD).
- S.W.1, można zmapować w kolejności preferencji do RAID10, RAID1 i RAID5.
- R.W.1, można zmapować w kolejności preferencji RAID10 i RAID1 (RAID5 ma bardzo słabą wydajność w losowym zapisie).
- sr.R.2 można zmapować na RAID10 (niektóre sposoby) i RAID6.
Kiedy mapujesz przestrzeń pamięci do danego objętości fizycznego, nie dołącz dwóch przestrzeni pamięci z tego samego urządzenia pamięci (i.mi. partycje). Stracisz zarówno zalety wydajności, jak i tolerancję na usterki! Na przykład Making /Dev /SDA1 i /Dev /SDA2 część tego samego objętości fizycznej RAID1 jest dość bezużyteczna.
Wreszcie, jeśli nie jesteś pewien, co wybrać między LVM i MDADM, sugerowałbym, że MDADM ma to nieco bardziej elastyczne (obsługuje RAID0, 1, 5 i 10, podczas gdy LVM obsługuje tylko paski (podobne do RAID0) i lustrzanie lustrzane (Podobnie jak RAID1)).
Nawet jeśli nie jest to wymagane, jeśli używasz MDADM, prawdopodobnie skończysz z mapowaniem jeden do jednego między VG i PVS. Powiedział inaczej, możesz mapować wiele PVS na jeden VG. Ale moim skromnym zdaniem jest to trochę bezużyteczne. MDADM zapewnia całą elastyczność wymaganą w mapowaniu partycji/urządzeń pamięci masowej na implementacje VG.
Definiowanie partycji
Wreszcie, możesz zrobić niektóre partycje z różnych urządzeń pamięci masowej w celu spełnienia wymagań PV (na przykład RAID5 wymaga co najmniej 3 różnych przestrzeni pamięci). Zauważ, że w zdecydowanej większości przypadków twoje partycje będą musiały być tego samego rozmiaru.
Jeśli możesz, proponuję użyć bezpośrednich urządzeń do przechowywania (lub wykonania tylko jednej partycji z dysku). Ale może być trudne, jeśli masz krótkie w urządzeniach pamięci masowej. Ponadto, jeśli masz urządzenia do przechowywania różnej wielkości, będziesz musiał przynajmniej podzielić jeden z nich.
Może być konieczne znalezienie kompromisu między wymaganiami PV a dostępnymi urządzeniami do przechowywania. Na przykład, jeśli masz tylko dwa dyski twarde, zdecydowanie nie możesz wdrożyć PV RAID5. Będziesz musiał polegać tylko na implementacji RAID1.
Pamiętaj, że jeśli naprawdę postępujesz zgodnie z procesem najwyższego poziomu opisanego w tym dokumencie (i jeśli możesz sobie pozwolić na cenę swoich wymagań), nie ma prawdziwego kompromisu, z którym można się z tym poradzić! 😉
/uruchomić
W naszym badaniu nie wspomnieliśmy o systemie plików /rozruchu, w którym przechowywana jest Loader. Niektórzy woleliby mieć tylko jeden pojedynczy / gdzie / rozruch to tylko sub-drektory. Inne wolą oddzielić / i / rozruch. W naszym przypadku, gdzie używamy LVM i MDADM, sugerowałbym następujący pomysł:
- /BOOT jest osobnym systemem plików, ponieważ niektóre ładowarki rozruchowe mogą mieć problemy z objętościami LVM;
- /boot jest systemem plików ext2 lub ext3, ponieważ format ten jest dobrze obsługiwany przez dowolny ładunek rozruchowy;
- /rozmiar rozruchu byłby rozmiar 100 MB, ponieważ initramfs może być dość ciężki i możesz mieć kilka jądra z własnymi initramfs;
- /Boot nie jest objętością LVM;
- /Boot to wolumin RAID1 (utworzony za pomocą MDADM). Zapewnia to, że co najmniej dwa urządzenia pamięci mają dokładnie tę samą zawartość złożoną z jądra, initramfs, systemu.mapa i inne rzeczy wymagane do uruchamiania;
- Tom /boot RAID1 jest wykonany z dwóch głównych partycji, które są pierwszą partycją na ich odpowiednich dyskach. Zapobiega to niektórym starym BIOS nie znajdującym obciążenia rozruchowego z powodu starych ograniczeń 1 GB.
- Ładowarka rozruchowa została zainstalowana na obu partycjach (dyskach), aby system mógł uruchomić się z obu dysków.
- BIOS został poprawnie skonfigurowany do uruchamiania z dowolnego dysku.
Zamieniać
Wymiana to także rzeczy, które do tej pory nie rozmawialiśmy. Masz tutaj wiele opcji:
- wydajność:
- Jeśli potrzebujesz wydajności za wszelką cenę, zdecydowanie utwórz jedną partycję na każdym urządzeniu pamięci i użyj go jako partycji swap. Jądro zrównoważy dane wejściowe/wyjściowe do każdej partycji zgodnie z własnymi potrzebami, co prowadzi do najlepszej wydajności. Zauważ, że możesz grać z priorytetem, aby podać pewne preferencje danym dyskom twardych (na przykład szybki dysk można uzyskać wyższy priorytet).
- Tolerancja błędów:
- Jeśli potrzebujesz tolerancji na usterki, zdecydowanie rozważ tworzenie objętości zamiany LVM z R.RW.1 grupa woluminów (na przykład zaimplementowana przez PV RAID1 lub RAID10.
- elastyczność:
- Jeśli chcesz zmienić zmianę wymiany z niektórych powodów, proponuję użyć jednego lub wielu objętości zamiany LVM.
Przyszłe i/lub egzotyczne systemy plików
Korzystanie z LVM jest dość łatwe do skonfigurowania nowego logicznego woluminu utworzonego z pewnej grupy woluminów (w zależności od tego, co chcesz przetestować i sprzęt) i sformatować go do niektórych systemów plików. LVM jest pod tym względem bardzo elastyczny. Zapraszam do tworzenia i usuwania systemów plików na woli.
Ale pod pewnymi względami przyszłe systemy plików, takie jak ZFS, BTRFS i NILFS2, nie będą idealnie pasować do LVM. Powodem jest to, że LVM prowadzi do wyraźnego oddzielenia potrzeb aplikacji/użytkowników i implementacji tych potrzeb, jak widzieliśmy. Z drugiej strony ZFS i BTRFS integrują zarówno potrzeby, jak i implementację z jednym rzeczami. Na przykład zarówno ZFS, jak i BTRFS obsługują poziom RAID bezpośrednio. Dobrą rzeczą jest to, że ułatwia tworzenie układu systemu plików. Złe jest to, że narusza pewne sposoby strategii rozdzielenia troski.
Dlatego możesz skończyć zarówno z XFS/lv/vg/md1/sd a, b 1 i btrfs/sd a, b 2 w tym samym systemie. Nie polecam takiego układu i sugeruję użycie ZFS lub BTRF do wszystkiego lub wcale.
Kolejnym systemem plików, który może być interesujący, jest NILFS2. To strukturę plik strukturalnych z logarytmicznie będą miały bardzo dobrą wydajność zapisu (ale może słabą wydajność odczytu). Dlatego taki system plików może być bardzo dobrym kandydatem do objętości logicznej dodatkowej lub na dowolnym woluminie logicznym utworzonym z RS.W.N grupa woluminów.
Dyski USB
Jeśli chcesz użyć jednego lub kilku dysków USB w układzie, rozważ następujące czynności:
- Przepustowość autobusu USB V2 wynosi 480 mbits/s (60 mbytes/s), co wystarczy dla zdecydowanej większości aplikacji komputerowych (z wyjątkiem może wideo HD);
- O ile wiem, nie znajdziesz żadnego urządzenia USB, które może wypełnić przepustowość USB V2.
Dlatego może być interesujące użycie kilku dysków USB (a nawet kija), aby uczynić je częścią systemu RAID, zwłaszcza systemu RAID1. Z takim układem możesz wyciągnąć jeden napęd USB z tablicy RAID1 i użyć go (w trybie tylko do odczytu) gdzie indziej. Następnie wciągasz go ponownie w oryginalnej tablicy RAID1 i z magicznym poleceniem MDADM, takim jak:
MDADM /dev /md0 -Add /dev /sda1
Tablica odbuduje automgicznie i wróci do swojego pierwotnego stanu. Nie polecam jednak wykonania żadnej innej tablicy RAID z dysku USB. W przypadku RAID0 jest oczywiste: jeśli usuniesz jeden dysk USB, tracisz wszystkie swoje dane! W przypadku RAID5, posiadanie dysku USB, a tym samym możliwość hot-wPlug nie oferuje żadnej przewagi: dysk USB, który wyciągnąłeś, jest bezużyteczny w trybie RAID5! (Ta sama uwaga dla RAID10).
Dyski SSD
Wreszcie, można wziąć pod uwagę nowe dyski SSD, definiując objętości fizyczne. Ich nieruchomości należy wziąć pod uwagę:
- Mają bardzo niskie opóźnienie (zarówno odczytane, jak i zapisz);
- Mają bardzo dobrą losową wydajność, a fragmentacja nie ma wpływu na ich wydajność (deterministyczna wydajność);
- Liczba zapisów jest ograniczona.
Dlatego dyski SSD są odpowiednie do wdrażania grup objętościowych RSR#n. Jako przykład MM.LV i czytaj.Objętości LV można przechowywać na SSDS, ponieważ dane są zwykle zapisywane raz i odczytywane wiele razy. Ten wzór użytkowania jest idealny dla SSD.
Wniosek
W trakcie projektowania układu systemu plików podejście do najwyższego poziomu rozpoczyna się od potrzeb wysokiego poziomu. Ta metoda ma tę zaletę, że możesz polegać na wcześniej wprowadzonych wymaganiach dotyczących podobnych systemów. Tylko wdrożenie się zmieni. Na przykład, jeśli zaprojektujesz system komputerów stacjonarnych: możesz skończyć z danym układem (na przykład na rysunku 1). Jeśli zainstalujesz kolejny system komputerowy z różnymi urządzeniami pamięci, możesz polegać na swoich pierwszych wymaganiach. Musisz tylko dostosować dolne warstwy: PV i partycje. Dlatego duża praca, wzór użytkowania lub obciążenie pracą, analiza może być oczywiście wykonana tylko raz na system.
W następnej i ostatniej sekcji podam kilka przykładów układu, z grubsza dostrojone do znanych zastosowań komputerowych.
Przykłady układu
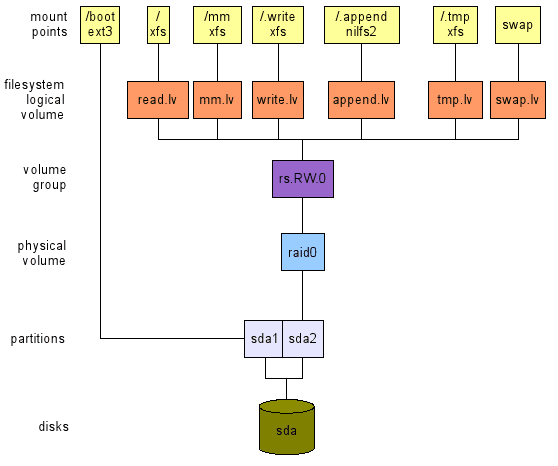
Wszelkie użycie, 1 dysk.
To (patrz górny układ Rysunek 2) Moim zdaniem jest dość dziwną sytuację. Jak już powiedziano, uważam, że każdy komputer powinien być rozmiarowy zgodnie z pewnym wzorem użytkowania. A posiadanie tylko jednego dysku do twojego systemu oznacza, że w jakiś sposób akceptujesz pełną awarię. Ale wiem, że zdecydowana większość komputerów - szczególnie laptopów i netbooków - jest sprzedawana (i zaprojektowana) z tylko jednym dysku. Dlatego proponuję następujący układ, który koncentruje się na elastyczności i wydajności (w jak największym stopniu):
- elastyczność:
- ponieważ układ pozwala zmienić rozmiar woluminów do woli;
- wydajność:
- Jak możesz wybrać system plików (ext2/3, xfs i tak dalej) zgodnie z wzorcami dostępu do danych.
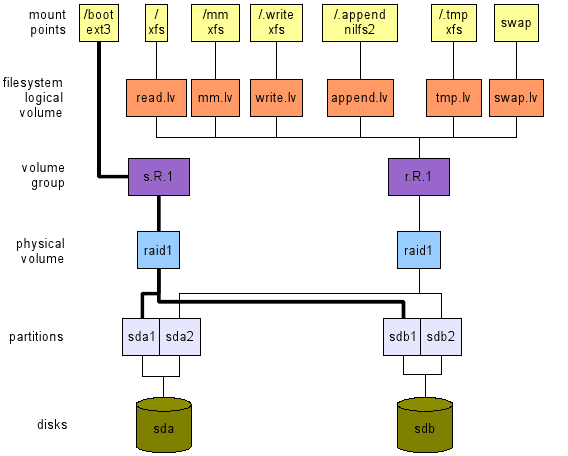
- Rysunek 2: Układ z jednym dyskiem (górny) i jeden do użycia komputerów stacjonarnych z dwoma dyskami (dołu).
-
-
- elastyczność:
- ponieważ układ pozwala zmienić rozmiar woluminów do woli;
- wydajność:
- Jak możesz wybrać system plików (ext2/3, xfs i tak dalej) zgodnie z wzorcami dostępu do danych i od r, ponieważ r.R.1 VG może być dostarczone przez PV RAID1 dla dobrej wydajności losowej odczytu (średnio). Zauważ jednak, że oba s.R.N i Rs.W.n nie może być dostarczone tylko 2 dyski dla jakiejkolwiek wartości n.
- Duża dostępność:
- Jeśli jeden dysk się nie powiedzie, system będzie kontynuowany w trybie zdegradowanym.
- elastyczność:
- ponieważ układ pozwala zmienić rozmiar woluminów do woli;
- wydajność:
- Jak możesz wybrać system plików (ext2/3, xfs i tak dalej) zgodnie z wzorcami dostępu do danych, a ponieważ oba r.R.1 i Rs.Rw.0 może być wyposażone w 2 dyski dzięki RAID1 i RAID0.
- Średnia dostępność:
- Jeśli jeden dysk się nie powiedzie, ważne dane pozostaną dostępne, ale system nie będzie w stanie poprawnie działać, chyba że niektóre działania zostaną podjęte w celu mapowania /.TMP i zamień na inne LV zmapowane na bezpieczny VG.
Zastosowanie komputerów stacjonarnych, wysoka dostępność, 2 dyski.
Tutaj (patrz dolny układ na ryc. 2), naszą troską jest wysoka dostępność. Ponieważ mamy tylko dwa dyski, można użyć tylko RAID1. Ta konfiguracja zapewnia:
Notatka: Region zamiany powinien znajdować się na PV RAID1, aby zapewnić wysoką dostępność.
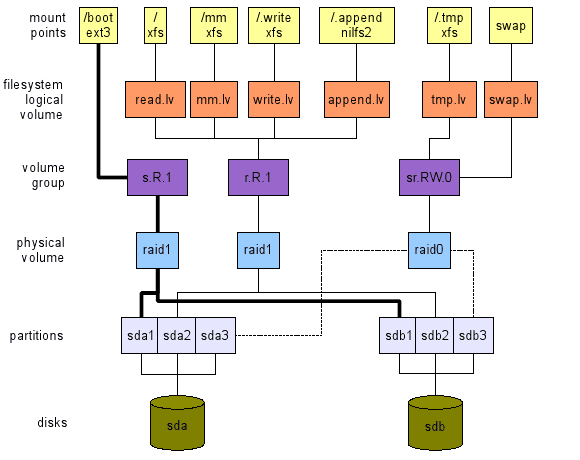
Zastosowanie komputerów stacjonarnych, wysoka wydajność, 2 dyski
Tutaj (patrz górny układ na ryc. 3), naszą troską jest wysoka wydajność. Zwróć jednak uwagę, że nadal uważam za niedopuszczalne, aby stracić niektóre dane. Ten układ zawiera następujące:
- Notatka: Region zamiany jest wykonany z RS.Rw.0 VG zaimplementowane przez RAID0 PV w celu zapewnienia elastyczności (rozmiar regionów zamiany jest bezbolesny). Inną opcją jest bezpośrednio użycie czwartej partycji z obu dysków.
Rysunek 3: TOP: Układ dla wysokiej wydajności użytkowania komputerów stacjonarnych z dwoma dyskami. Umoc: układ dla serwera plików z czterema dyskami.
- elastyczność:
- ponieważ układ pozwala zmienić rozmiar woluminów do woli;
- wydajność:
- Jak możesz wybrać system plików (ext2/3, xfs i tak dalej) zgodnie z wzorcami dostępu do danych, a ponieważ oba RS.R.1 i Rs.RW.1 może być wyposażony w 4 dyski dzięki RAID5 i RAID10.
- Duża dostępność:
- Jeśli jeden dysk się nie powiedzie, wszelkie dane pozostaną dostępne, a system będzie mógł poprawnie pracować.
- Albo masz wystarczającą pamięć lub/i użytkownicy mają wysokie zapotrzebowanie na dostęp do losowego/sekwencyjnego zapisu, RAID10 PV jest dobrą opcją;
- Lub, nie masz wystarczającej ilości pamięci ani//a użytkownicy nie mają wysokich potrzeb losowych/sekwencyjnych, RAID5 PV jest dobrą opcją.
Serwer plików, 4 dyski.
Tutaj (patrz dolny układ Ryc. 3), naszą troską jest zarówno wysoka wydajność, jak i wysoka dostępność. Ten układ zawiera następujące:
Notatka 1:
Mogliśmy użyć RAID10 dla całego systemu, ponieważ zapewnia on bardzo dobrą implementację RS.Rw.1 VG (a w jakiś sposób także Rs.Rw.2). Niestety ma to koszt: wymagane są 4 urządzenia pamięci (tutaj partycje), każda z tych samych pojemności (powiedzmy s = 500 gigabajtów). Ale objętość fizyczna RAID10 nie zapewnia pojemności 4*s (2 terabajty), jak można się spodziewać. Zapewnia tylko połowę, 2*s (1 terabajty). Pozostałe 2*s (1 terabajty) są używane do wysokiej dostępności (lustro). Szczegółowe informacje można znaleźć w dokumentacji RAID. Dlatego decyduję się na użycie RAID5 do wdrażania RS.R.1. RAID5 zapewni pojemność 3*S (1.5 gigabajtów), pozostałe S (500 gigabajtów) jest używane do wysokiej dostępności. MM.LV zwykle wymaga dużej ilości miejsca do przechowywania, ponieważ zawiera pliki multimedialne.
Uwaga 2:
Jeśli eksportujesz przez NFS lub SMB „Home” katalogi, możesz uważnie rozważyć ich lokalizację. Jeśli użytkownicy potrzebują dużo miejsca, tworzenie domów na zapisie.LV (lokalizacja „Fit-All”) może być wysłuchana, ponieważ jest wspierana przez RAID10 PV, w którym połowa miejsca do przechowywania jest używana do lustrzania (i wydajności). Masz tutaj dwie opcje:
Pytania, komentarze i sugestie
Jeśli masz jakieś pytanie, komentarz i/lub sugestie dotyczące tego dokumentu, skontaktuj się ze mną pod następującym adresem: [email protected].
Prawa autorskie
Ten dokument jest licencjonowany w ramach Creative Commons Ushares Share 2.0 Licencja Francji.
Zastrzeżenie
Informacje zawarte w tym dokumencie służą wyłącznie do celów informacyjnych ogólnych. Informacje są dostarczane przez Pierre Vignéras i chociaż staram się, aby informacje były aktualizowane i poprawne, nie składam żadnych oświadczeń ani gwarancji żadnych, wyraźnych lub dorozumianych, na temat kompletności, dokładności, niezawodności, przydatności lub dostępności w odniesieniu do dokument lub informacje, produkty, usługi lub powiązana grafika zawarta w dokumencie w dowolnym celu.
Wszelkie poleganie na takich informacjach jest zatem ściśle na własne ryzyko. W żadnym wypadku nie ponosimy odpowiedzialności za jakiekolwiek straty lub szkody, w tym bez ograniczeń, utrata lub uszkodzenia konsekwentne, ani jakiejkolwiek straty lub szkód wynikających z utraty danych lub zysków wynikających z tego użycia lub w związku z tym za korzystanie z tego dokument.
Za pośrednictwem tego dokumentu możesz połączyć się z innymi dokumentami, które nie są pod kontrolą Pierre Vignéras. Nie mam kontroli nad naturą, treścią i dostępnością tych stron. Włączenie wszelkich linków niekoniecznie oznacza zalecenie lub popiera w nich wyrażone poglądy.
Powiązane samouczki Linux:
- Rzeczy do zainstalowania na Ubuntu 20.04
- Rzeczy do zrobienia po zainstalowaniu Ubuntu 20.04 Focal Fossa Linux
- Linux Pliki konfiguracyjne: Top 30 Najważniejsze
- Rzeczy do zrobienia po zainstalowaniu Ubuntu 22.04 JAMMY Jellyfish…
- Jak sprawdzić zdrowie dysku twardego z wiersza poleceń…
- Mint 20: Lepsze niż Ubuntu i Microsoft Windows?
- Pobierz Linux
- Ubuntu 20.04 Przewodnik
- Manjaro Linux Windows 10 Dual Boot
- Wprowadzenie do automatyzacji, narzędzi i technik Linuksa
- « 101 Howto zacząć od openCV i wizji komputerowej na Ubuntu Linux
- Problem z klawiszem strzałek VMware na Ubuntu »