

WPROWADZENIE DO PYTHON WEWET SKRAPING I Piękna Biblioteka Zupów
- 2918
- 899
- Juliusz Janicki
Cel
Nauka wyodrębnienia informacji ze strony HTML za pomocą Pythona i pięknej biblioteki zup.
Wymagania
- Zrozumienie podstaw programowania Pythona i obiektowego
Konwencje
- # - Wymaga podanego polecenia Linuxa, które można było wykonać z uprawnieniami root
bezpośrednio jako użytkownik root lub za pomocąsudoKomenda - $ - Biorąc pod uwagę polecenie Linux, które ma być wykonane jako zwykły użytkownik niepewny
Wstęp
Scrapowanie internetowe to technika, która polegała na ekstrakcji danych ze strony internetowej za pomocą dedykowanego oprogramowania. W tym samouczku zobaczymy, jak wykonać podstawowe skrobanie internetowe za pomocą Pythona i pięknej biblioteki zupy. Użyjemy Python3 Kierowanie na stronę główną Rotten Tomatoes, słynny agregator recenzji i wiadomości do filmów i programów telewizyjnych, jako źródło informacji do naszego ćwiczenia.
Instalacja pięknej biblioteki zup
Aby wykonać nasze skrobanie. Biblioteka jest dostępna w repozytoriach wszystkich głównych dystrybucji GNU \ Linux, dlatego możemy ją zainstalować za pomocą naszego ulubionego menedżera pakietów lub za pomocą za pomocą pypeć, Python Native Way do instalowania pakietów.
Jeśli preferowane jest użycie menedżera pakietów dystrybucyjnych, a my używamy Fedory:
$ sudo dnf instaluj Python3-beautifulSoup4
W Debian i jego pochodnych pakiet nazywa się BeautifulSoup4:
$ sudo apt-get instal instaluj pięknie
Na archilinux możemy go zainstalować za pośrednictwem Pacman:
$ sudo pacman -Python -beatufilusoup4
Jeśli chcemy użyć pypeć, Zamiast tego możemy po prostu uruchomić:
$ PIP3 instalacja -użytkownik BeautifulSoup4
Uruchamiając polecenie powyżej z --użytkownik flaga, zainstalujemy najnowszą wersję pięknej biblioteki zup. Oczywiście możesz zdecydować o użyciu PIP do instalacji pakietu na całym świecie, ale osobiście wolę instalacje dla użytkownika, gdy nie korzystam z menedżera pakietu dystrybucji.
Piękny obiekt
Zacznijmy: Pierwszą rzeczą, którą chcemy zrobić, jest stworzenie obiektu pięknego. Constructor Beautifulsoup akceptuje albo strunowy lub uchwyt pliku jako pierwszy argument. To ostatnie nas interesuje: mamy adres URL strony, którą chcemy zeskrobać, dlatego użyjemy urlopen Metoda urllib.wniosek Biblioteka (domyślnie zainstalowana): Ta metoda zwraca obiekt podobny do pliku:
z BS4 importują piękną grupę z urllib.Poproś o import urlopen z urlopen ('http: // www.zgniłe pomidory.com ') jako strona główna: zupa = piękna (strona główna) W tym momencie nasza zupa jest gotowa: zupa Obiekt reprezentuje dokument w całości. Możemy rozpocząć nawigację i wyodrębnienie danych, które chcemy za pomocą wbudowanych metod i właściwości. Na przykład, powiedzmy, że chcemy wyodrębnić wszystkie linki zawarte na stronie: Wiemy, że linki są reprezentowane przez A znacznik w HTML, a rzeczywisty link jest zawarty w Href atrybut tagu, abyśmy mogli użyć Znajdź wszystko Metoda obiektu, który właśnie zbudowaliśmy, aby wykonać nasze zadanie:
do linku w zupie.Find_All („a”): drukuj (link.Get („href”)) Za pomocą Znajdź wszystko metoda i określenie A Jako pierwszy argument, który jest nazwą tagu, szukaliśmy wszystkich linków na stronie. Dla każdego linku następnie pobraliśmy i wydrukowaliśmy wartość Href atrybut. W pięknej grupie atrybuty elementu są przechowywane w słowniku, dlatego ich odzyskanie jest bardzo łatwe. W tym przypadku użyliśmy Dostawać Metoda, ale moglibyśmy uzyskać dostęp do wartości atrybutu HREF, nawet przy następującej składni: link [„href”]. Sam pełny słownik atrybutów jest zawarty w attrs właściwość elementu. Powyższy kod przyniesie następujący wynik:
[…] Https: // redakcja.zgniłe pomidory.com/https: // redakcja.zgniłe pomidory.com/24-frame/https: // redakcja.zgniłe pomidory.com/binge-guide/https: // redakcja.zgniłe pomidory.com/pudełko-guru/https: // redakcja.zgniłe pomidory.COM/Critics-Consensus/https: // redakcja.zgniłe pomidory.com/Five Favorite-Films/https: // redakcja.zgniłe pomidory.com/teraz streaming/https: // redakcja.zgniłe pomidory.COM/PARETENT-GUIDANCE/HTTPS: // Editorial.zgniłe pomidory.COM/RED-CARPET-ROODUP/HTTPS: // Editorial.zgniłe pomidory.com/rt-on-dvd/https: // redakcja.zgniłe pomidory.com/the-simpsons-dekade/https: // redakcja.zgniłe pomidory.com/sub-cult/https: // redakcja.zgniłe pomidory.com/tech-talk/https: // redakcja.zgniłe pomidory.com/ total-recall/ […]
Lista jest znacznie dłuższa: powyższe jest tylko ekstrakt wyjścia, ale daje pomysł. Znajdź wszystko Metoda zwraca wszystko Etykietka obiekty, które pasują do określonego filtra. W naszym przypadku właśnie określiliśmy nazwę znacznika, który powinien być dopasowany, i żadnych innych kryteriów, więc wszystkie linki zostaną zwrócone: za chwilę zobaczymy, jak jeszcze bardziej ograniczyć nasze wyszukiwanie.
Przypadek testowy: pobieranie wszystkich tytułów „najlepszych kas”
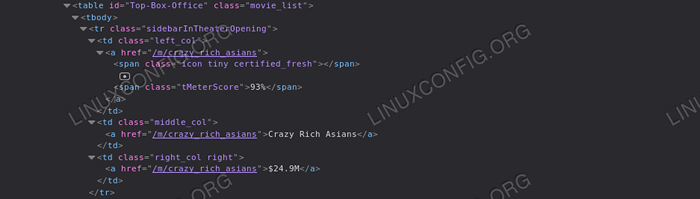
Wykonajmy bardziej ograniczone skrobanie. Powiedzmy, że chcemy odzyskać wszystkie tytuły filmów, które pojawiają się w sekcji „Top Box Office” strony głównej strony Rotten Tomatoes. Pierwszą rzeczą, którą chcemy zrobić, jest przeanalizowanie strony HTML dla tej sekcji: W ten sposób możemy zauważyć, że potrzebny element jest zawarty w środku tabela element z „najlepszym biurem” ID:
Najlepsza kasa Możemy również zauważyć, że każdy wiersz tabeli zawiera informacje o filmie: Wyniki tytułu są zawarte jako tekst wewnątrz Zakres element z klasą „tmeterscore” wewnątrz pierwszej komórki wiersza, podczas gdy ciąg reprezentujący tytuł filmu jest zawarty w drugiej komórce, jako tekst A etykietka. Wreszcie, ostatnia komórka zawiera związek z tekstem reprezentującym wyniki kasy filmu. Dzięki tym odniesieniu możemy łatwo odzyskać wszystkie żądane dane:
z BS4 importują piękną grupę z urllib.Poproś o import urlopen z urlopen ('https: // www.zgniłe pomidory.com ') jako strona główna: zupa = piękna (strona główna.czytaj (), „html.Parser ') # Najpierw używamy metody Znajdź do pobrania tabeli za pomocą „Top-box-Office” ID top_box_office_table = zupa.Znajdź („Tabela”, 'ID': 'top-box-Office') # niż iteracja każdego wiersza i wyodrębniamy informacje o filmach w wierszu w top_box_office_table.Find_All („tr”): komórki = wiersz.Find_All ('td') title = komórki [1].Znajdź').get_text () pieniądze = komórki [2].Znajdź').get_text () score = wiersz.znaleźć („span”, 'class': 'tmeterscore').get_text () print ('0 - 1 (tomatometr: 2)'.Format (tytuł, pieniądze, wynik)) Powyższy kod przyniesie następujący wynik:
Szaleni Rich Azjaci - 24 USD.9m (pomidometr: 93%) Meg - 12 USD.9m (Tomatometr: 46%) Morderstwa Happytime - \ 9 USD.6M (Tomatometr: 22%) Misja: Impossible - Fallout - 8 USD.2M (Tomatometr: 97%) Mile 22 - 6 USD.5M (Tomatometr: 20%) Christopher Robin - 6 USD.4M (Tomatometr: 70%) Alpha - 6 USD.1M (Tomatometr: 83%) Blackkklansman - 5 USD.2M (Tomatometr: 95%) Smukły człowiek - 2 USD.9m (pomidometr: 7%) a.X.L. -- 2 USD.8m (Tomatometr: 29%)
Wprowadziliśmy kilka nowych elementów, zobaczmy je. Pierwszą rzeczą, którą zrobiliśmy, jest odzyskanie tabela z identyfikatorem „Top-Box-Office”, używając znajdować metoda. Ta metoda działa podobnie Znajdź wszystko, ale chociaż ten ostatni zwraca listę, która zawiera znalezione dopasowania lub jest pusta, jeśli nie ma korespondencji, ten pierwszy zwraca zawsze pierwszy wynik lub Nic Jeśli nie znaleziono elementu o określonych kryteriach.
Pierwszy element dostarczony do znajdować Metoda to nazwa znacznika, który należy wziąć pod uwagę w wyszukiwaniu, w tym przypadku tabela. Jako drugi argument przekazaliśmy słownik, w którym każdy klucz reprezentuje atrybut znacznika o odpowiedniej wartości. Pary wartości kluczowej podane w słowniku reprezentują kryteria, które muszą być spełnione dla naszych poszukiwań w celu uzyskania dopasowania. W tym przypadku szukaliśmy ID atrybut z wartością „Top-box-Office”. Zauważ, że od każdego ID Musi być unikalna na stronie HTML, moglibyśmy po prostu pominąć nazwę znacznika i użyć tej alternatywnej składni:
top_box_office_table = zupa.Znajdź (id = 'top-box-Office') Po odzyskaniu naszego stołu Etykietka obiekt, użyliśmy Znajdź wszystko metoda znalezienia wszystkich wierszy i itera. Aby odzyskać pozostałe elementy, zastosowaliśmy te same zasady. Zastosowaliśmy również nową metodę, get_text: Zwraca tylko część tekstową zawartą w znaczniku lub jeśli nie zostanie określona, na całej stronie. Na przykład wiedząc, że procent wyników filmowych jest reprezentowany przez tekst zawarty w Zakres element z tmeterscore klasa, użyliśmy get_text Metoda na elemencie, aby go odzyskać.
W tym przykładzie właśnie wyświetliśmy odzyskane dane z bardzo prostym formatowaniem, ale w scenariuszu w świecie rzeczywistym mogliśmy chcieć wykonać dalsze manipulacje lub przechowywać je w bazie danych.
Wnioski
W tym samouczku właśnie porysowaliśmy powierzchnię tego, co możemy zrobić za pomocą Python i pięknej biblioteki zupy, aby wykonać skrobanie internetowe. Biblioteka zawiera wiele metod, których możesz użyć do bardziej wyrafinowanego wyszukiwania lub do lepszego poruszania się po stronie: W tym celu zdecydowanie zalecam skonsultować się z bardzo dobrze napisanymi oficjalnymi dokumentami.
Powiązane samouczki Linux:
- Rzeczy do zainstalowania na Ubuntu 20.04
- Wprowadzenie do automatyzacji, narzędzi i technik Linuksa
- Rzeczy do zrobienia po zainstalowaniu Ubuntu 20.04 Focal Fossa Linux
- Mastering Bash Script Loops
- Mint 20: Lepsze niż Ubuntu i Microsoft Windows?
- Polecenia Linux: Top 20 najważniejsze polecenia, które musisz…
- Podstawowe polecenia Linux
- Jak zbudować aplikację Tkinter za pomocą obiektu zorientowanego na…
- Ubuntu 20.04 WordPress z instalacją Apache
- Jak montować obraz ISO na Linux