

Ubuntu 20.04 Hadoop

- 3464
- 1017
- Seweryn Augustyniak
Apache Hadoop składa się z wielu pakietów oprogramowania typu open source, które współpracują z rozproszonym przechowywaniem i rozproszonym przetwarzaniem dużych zbiorów danych. Hadoop mają cztery główne elementy:
- Hadoop Common - różne biblioteki oprogramowania, od których zależy od uruchomienia
- Hadoop rozproszony system plików (HDFS) - System plików, który umożliwia wydajną dystrybucję i przechowywanie dużych zbiorów danych w klastrze komputerów
- Hadoop MapReduce - używane do przetwarzania danych
- Hadoop Yarn - API, który zarządza alokacją zasobów obliczeniowych dla całego klastra
W tym samouczku omówimy kroki, aby zainstalować Hadoop w wersji 3 na Ubuntu 20.04. Będzie to obejmować instalację HDFS (Namenode i DataNode), Yarn i MapReduce na klastrze jednego węzła skonfigurowanego w trybie Pseudo rozproszonym, który jest rozproszoną symulacją na jednym komputerze. Każdy komponent Hadoop (HDFS, Yarn, MapReduce) będzie działał w naszym węźle jako osobny proces Java.
W tym samouczku nauczysz się:
- Jak dodać użytkowników do środowiska Hadoop
- Jak zainstalować Warunek Java
- Jak skonfigurować SSH bez hasła
- Jak zainstalować Hadoop i skonfigurować niezbędne powiązane pliki XML
- Jak rozpocząć klaster Hadoop
- Jak uzyskać dostęp do interfejsu internetowego Namenode i ResourceManager
Apache Hadoop na Ubuntu 20.04 Focal Fossa | Kategoria | Wymagania, konwencje lub wersja oprogramowania |
|---|---|
| System | Zainstalowany Ubuntu 20.04 lub zaktualizowane Ubuntu 20.04 Focal Fossa |
| Oprogramowanie | Apache Hadoop, Java |
| Inny | Uprzywilejowany dostęp do systemu Linux jako root lub za pośrednictwem sudo Komenda. |
| Konwencje | # - Wymaga, aby podane polecenia Linux są wykonywane z uprawnieniami root bezpośrednio jako użytkownik root lub za pomocą sudo Komenda$ - Wymaga, aby podane polecenia Linux zostały wykonane jako zwykły użytkownik niepewny |
Utwórz użytkownika dla środowiska Hadoop
Hadoop powinien mieć własne dedykowane konto użytkowników w twoim systemie. Aby utworzyć jeden, otwórz terminal i wpisz następujące polecenie. Zostaniesz również poproszony o utworzenie hasła do konta.
$ sudo adduser hadoop
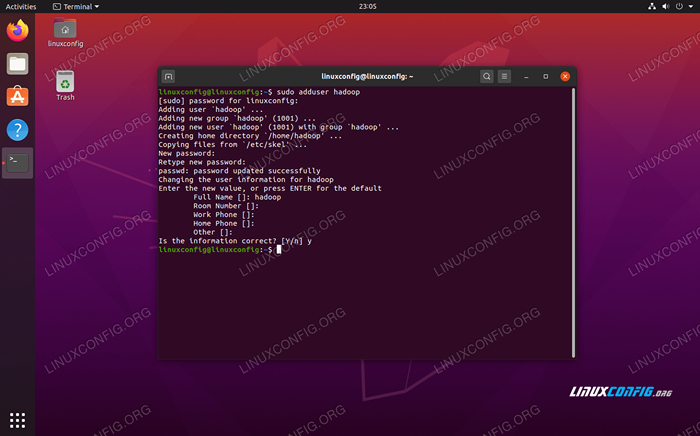 Utwórz nowego użytkownika Hadoop
Utwórz nowego użytkownika Hadoop Zainstaluj wymaganie wstępne Java
Hadoop opiera się na Javie, więc musisz zainstalować go w swoim systemie, zanim będziesz mógł użyć Hadoop. W chwili pisania tego pisma obecny Hadoop wersja 3.1.3 wymaga Java 8, więc to właśnie będziemy instalować w naszym systemie.
Użyj następujących dwóch poleceń, aby pobrać najnowsze listy pakietów trafny i zainstaluj Java 8:
$ sudo appt aktualizacja $ sudo apt instontuj openjdk-8-jdk openjdk-8-jre
Skonfiguruj SSH bez hasła
Hadoop polega na SSH, aby uzyskać dostęp do swoich węzłów. Będzie łączyć się z maszynami zdalnymi za pośrednictwem SSH, a także lokalnego komputera, jeśli masz na nim działając. Tak więc, chociaż w tym samouczku konfigurujemy Hadoop na naszym lokalnym komputerze, nadal musimy zainstalować SSH. Musimy również skonfigurować bez hasła SSH
Aby Hadoop mógł cicho nawiązać połączenia w tle.
- Będziemy potrzebować zarówno serwera OpenSsh, jak i pakietu klientów OpenSSH. Zainstaluj je z tym poleceniem:
$ sudo apt install openssh-server openSsh-client
- Przed kontynuowaniem najlepiej zalogować się do
HadoopKonto użytkownika, które utworzyliśmy wcześniej. Aby zmienić użytkowników w bieżącym terminalu, użyj następującego polecenia:$ su hadoop
- Po zainstalowaniu tych pakietów nadszedł czas na generowanie pary kluczy publicznych i prywatnych z następującym poleceniem. Zauważ, że terminal poprosi cię kilka razy, ale wszystko, co musisz zrobić, to uderzać
WCHODZIĆkontynuować.$ ssh -keygen -t rsa
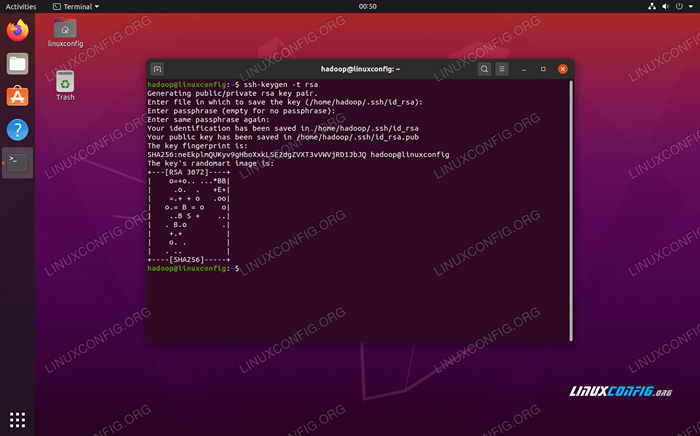 Generowanie klawiszy RSA dla SSH bez hasła
Generowanie klawiszy RSA dla SSH bez hasła - Następnie skopiuj nowo wygenerowany klucz RSA
id_rsa.pubdoautoryzowane_keys:$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/autoryzowane_keys
- Możesz upewnić się, że konfiguracja zakończyła się powodzeniem, sshing do LocalHost. Jeśli jesteś w stanie to zrobić bez monitu o hasło, możesz iść.
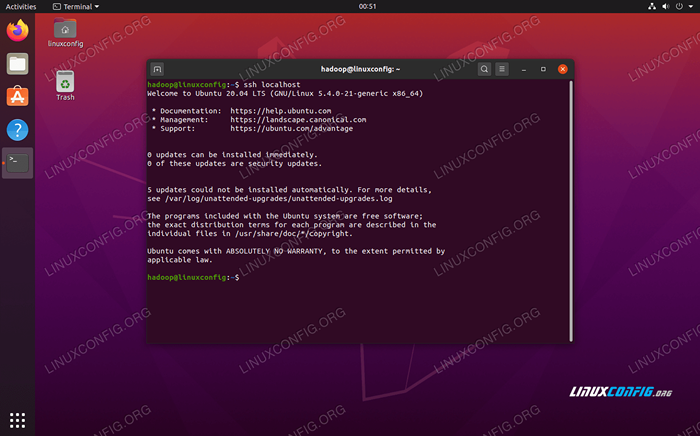 Sshing do systemu bez monitu o hasło oznacza, że zadziałało
Sshing do systemu bez monitu o hasło oznacza, że zadziałało
Zainstaluj hadoop i skonfiguruj powiązane pliki XML
Udaj się na stronę Apache, aby pobrać Hadoop. Możesz również użyć tego polecenia, jeśli chcesz pobrać Hadoop w wersji 3.1.3 bezpośrednio binarne:
$ wget https: // pobieranie.Apache.org/hadoop/common/hadoop-3.1.3/Hadoop-3.1.3.smoła.GZ
Wyodrębnij pobieranie do Hadoop Direkt domowy użytkownika z tym poleceniem:
$ tar -xzvf hadoop -3.1.3.smoła.GZ -C /Home /Hadoop
Konfigurowanie zmiennej środowiska
Następujące eksport Polecenia skonfigurują wymagane zmienne środowiskowe Hadoop w naszym systemie. Możesz skopiować i wkleić je do swojego terminala (może być konieczne zmianę wiersza 1, jeśli masz inną wersję Hadoop):
Eksport hadoop_home =/home/hadoop/hadoop-3.1.3 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin Eksport Hadoop_Opts = "-Djava.biblioteka.ścieżka = $ hadoop_home/lib/Native "Źródło .Bashrc plik w bieżącej sesji logowania:
$ źródło ~/.Bashrc
Następnie wprowadzimy pewne zmiany w Hadoop-env.cii plik, który można znaleźć w katalogu instalacyjnym Hadoop pod /etc/hadoop. Użyj Nano lub swojego ulubionego edytora tekstu, aby go otworzyć:
$ nano ~/hadoop-3.1.3/etc/hadoop/hadoop-env.cii
Zmienić Java_home zmienne do miejsca zainstalowania Java. W naszym systemie (i prawdopodobnie też, jeśli prowadzisz Ubuntu 20.04 i do tej pory podążamy razem z nami), zmieniamy tę linię na:
Eksport java_home =/usr/lib/jvm/java-8-openjdk-amd64
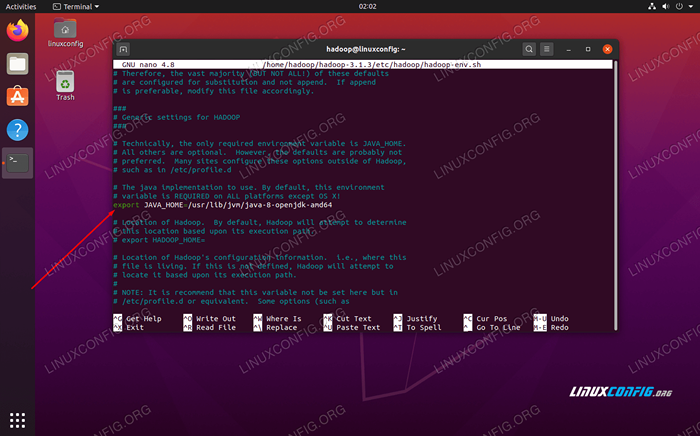 Zmień zmienną środowiskową java_home
Zmień zmienną środowiskową java_home To będzie jedyna zmiana, którą musimy tutaj wprowadzić. Możesz zapisać zmiany w pliku i zamknąć je.
Zmiany konfiguracji w witrynie rdzeniowym.plik XML
Kolejna zmiana, którą musimy dokonać Site Core.XML plik. Otwórz to za pomocą tego polecenia:
$ nano ~/hadoop-3.1.3/etc/hadoop/rdzeń.XML
Wprowadź następującą konfigurację, która instruuje HDFS, aby uruchomiła się w Port LocalHost 9000 i konfiguruje katalog danych tymczasowych.
fs.Defaultfs HDFS: // LocalHost: 9000 Hadoop.TMP.dir/home/hadoop/hadooptmpdata 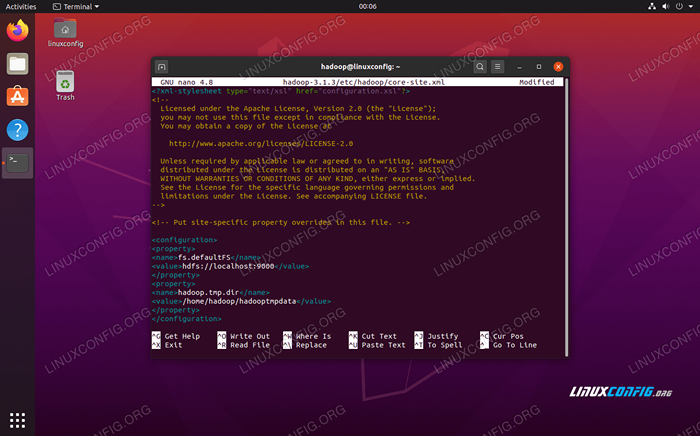 Site Core.Zmiany plików konfiguracyjnych XML
Site Core.Zmiany plików konfiguracyjnych XML Zapisz zmiany i zamknij ten plik. Następnie utwórz katalog, w którym dane tymczasowe zostaną przechowywane:
$ mkdir ~/hadooptmpdata
Zmiany konfiguracji w witrynie HDFS.plik XML
Utwórz dwa nowe katalogi dla Hadoop, aby przechowywać informacje o nazwie i datanode.
$ mkdir -p ~/hdfs/namenode ~/hdfs/datanode
Następnie edytuj następujący plik, aby powiedzieć Hadoop, gdzie znaleźć te katalogi:
$ nano ~/hadoop-3.1.3/etc/hadoop/HDFS-Site.XML
Wprowadzić następujące zmiany w Site HDFS.XML Plik, przed zapisaniem i zamknięciem:
DFS.Replikacja 1 DFS.nazwa.Plik DIR: /// home/hadoop/hdfs/namenode dfs.dane.plik DIR: /// home/hadoop/hdfs/datanode 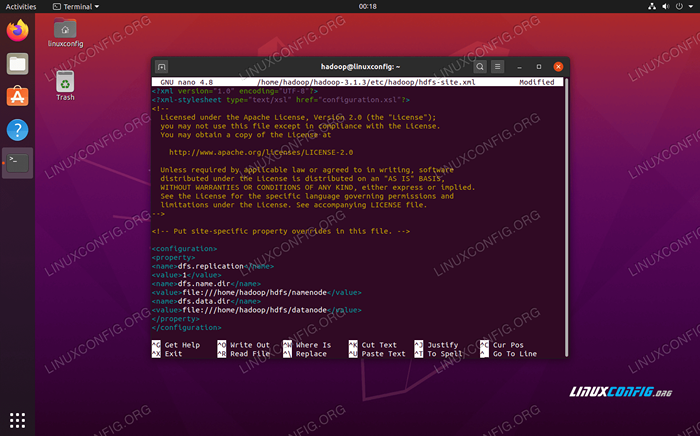 Site HDFS.Zmiany plików konfiguracyjnych XML
Site HDFS.Zmiany plików konfiguracyjnych XML Zmiany konfiguracyjne w witrynie Mapred.plik XML
Otwórz plik konfiguracyjny MapReduce XML za pomocą następującego polecenia:
$ nano ~/hadoop-3.1.3/etc/Hadoop/Mapred-Site.XML
I dokonaj następujących zmian przed zapisaniem i zamknięciem pliku:
MapReduce.struktura.Imię Parn 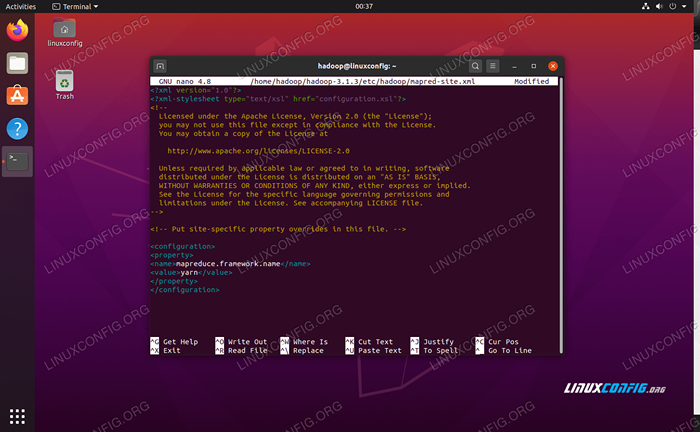 Mapred.Zmiany plików konfiguracyjnych XML
Mapred.Zmiany plików konfiguracyjnych XML Zmiany konfiguracji w witrynie przędzy.plik XML
Otwórz plik konfiguracyjny przędzy za pomocą następującego polecenia:
$ nano ~/hadoop-3.1.3/etc/hadoop/przędza.XML
Dodaj następujące wpisy w tym pliku, zanim zapisze zmiany i zamknięcie go:
MapReduceyarn.Nodemanager.Aux-Services MAPREDUCE_SHUFLE 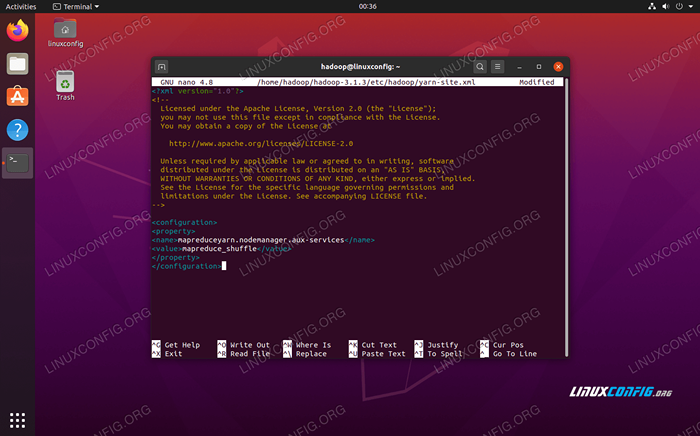 Zmiany plików konfiguracji konfiguracji przędzy
Zmiany plików konfiguracji konfiguracji przędzy Rozpoczynając klaster Hadoop
Przed użyciem klastra po raz pierwszy musimy sformatować nazwę nazewniczą. Możesz to zrobić za pomocą następującego polecenia:
$ hdfs namenode -Format
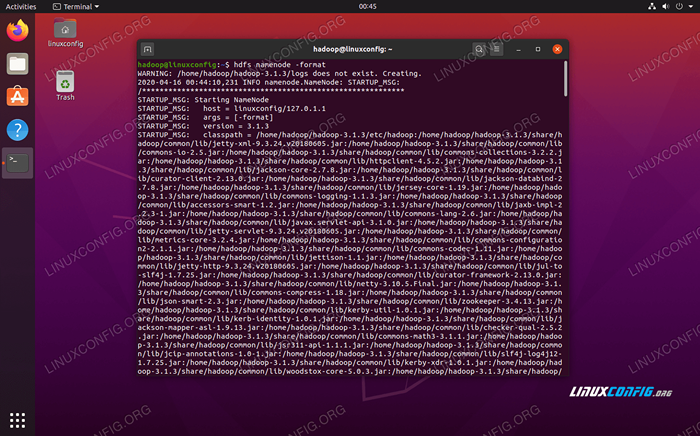 Formatowanie nazwy nazwy HDFS
Formatowanie nazwy nazwy HDFS Twój terminal wypluje wiele informacji. Tak długo, jak nie widzisz żadnych komunikatów o błędach, możesz założyć, że zadziałało.
Następnie uruchom HDFS za pomocą start-DFS.cii scenariusz:
$ start-dfs.cii
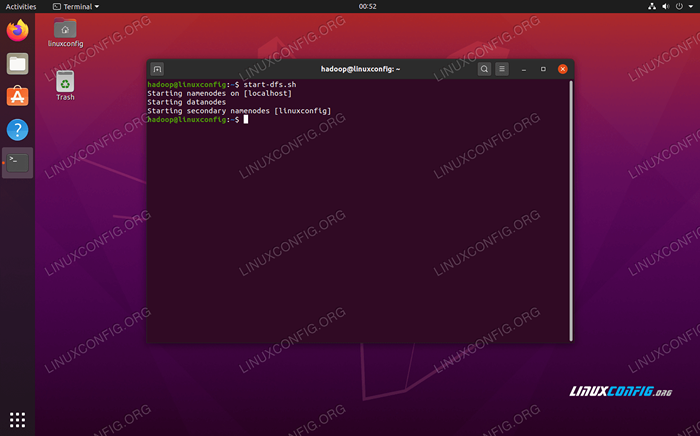 Uruchom start-DFS.Skrypt SH
Uruchom start-DFS.Skrypt SH Teraz rozpocznij usługi przędzy za pośrednictwem Start-Yarn.cii scenariusz:
$ start-yarn.cii
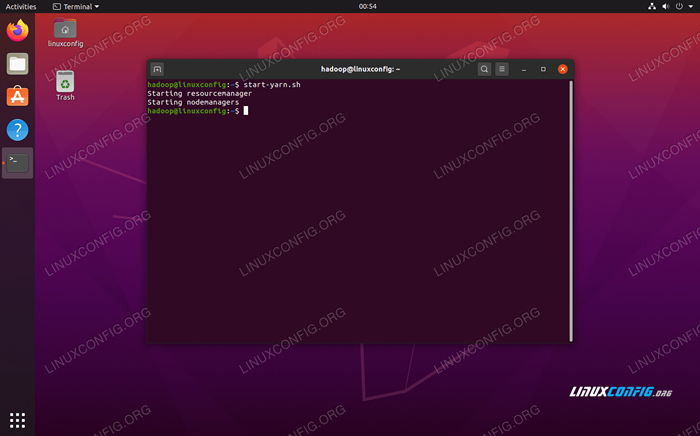 Uruchom start-yarn.Skrypt SH
Uruchom start-yarn.Skrypt SH Aby sprawdzić, czy wszystkie usługi/demony Hadoop zostały uruchomione z powodzeniem, możesz użyć JPS Komenda. To pokaże wszystkie procesy obecnie korzystające z Java, które działają w twoim systemie.
$ JPS
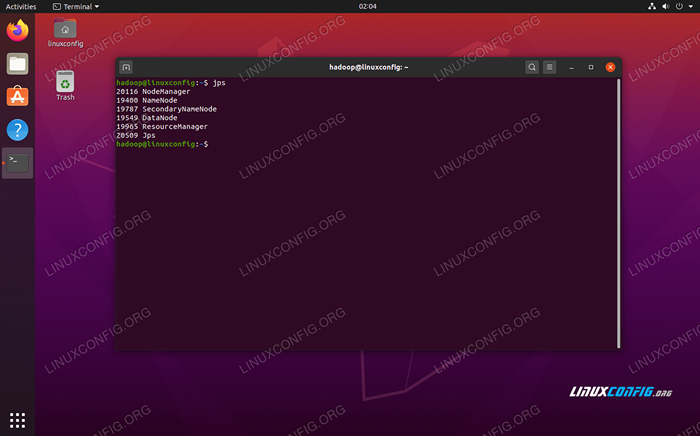 Wykonaj JPS, aby zobaczyć wszystkie procesy zależne od Java i sprawdź uruchomione komponenty Hadoop
Wykonaj JPS, aby zobaczyć wszystkie procesy zależne od Java i sprawdź uruchomione komponenty Hadoop Teraz możemy sprawdzić bieżącą wersję Hadoop za pomocą jednego z następujących poleceń:
Wersja $ Hadoop
Lub
Wersja $ HDFS
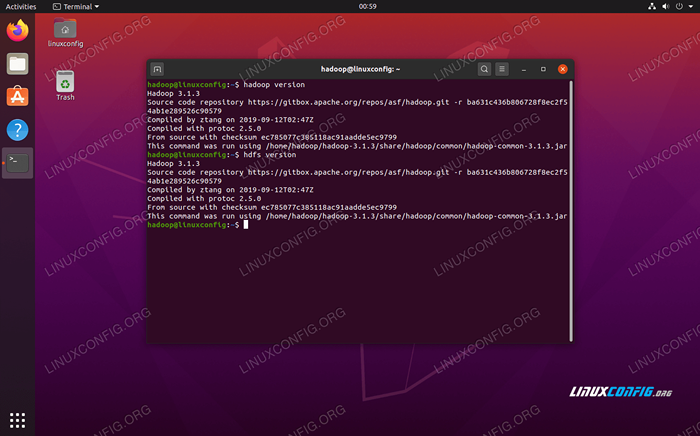 Weryfikacja instalacji Hadoop i bieżącej wersji
Weryfikacja instalacji Hadoop i bieżącej wersji Interfejs wiersza poleceń HDFS
Wiersz poleceń HDFS służy do dostępu do HDFS i tworzenia katalogów lub wydawania innych poleceń w celu manipulowania plikami i katalogami. Użyj następującej składni polecenia, aby utworzyć niektóre katalogi i wymienić je:
$ hdfs dfs -mkdir /test $ hdfs dfs -mkdir /hadooponubuntu $ hdfs dfs -ls /
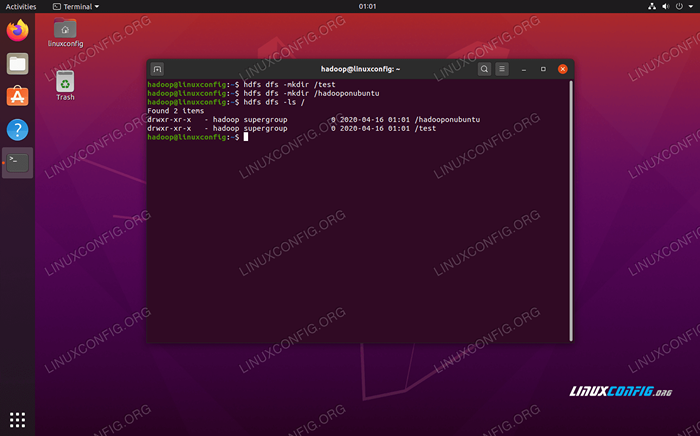 Interakcja z wierszem poleceń HDFS
Interakcja z wierszem poleceń HDFS Uzyskaj dostęp do nazwy i przędzy z przeglądarki
Możesz uzyskać dostęp zarówno do interfejsu internetowego dla Namenode, jak i Menedżer zasobów przędzy za pośrednictwem dowolnej wybranej przeglądarki, takiej jak Mozilla Firefox lub Google Chrome.
W przypadku interfejsu internetowego Namenode przejdź do http: // hadoop-hostname-or-ip: 50070
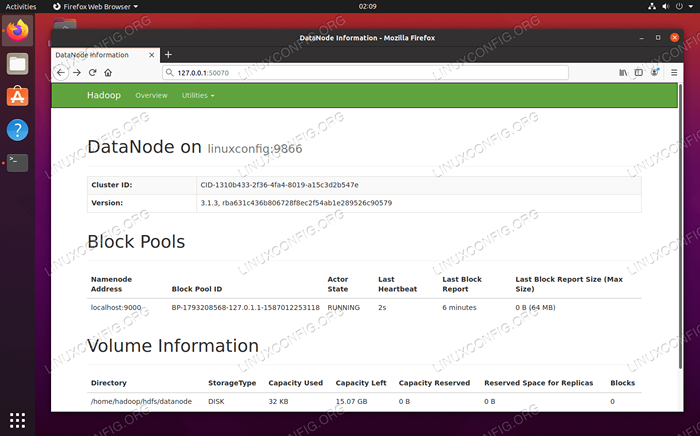 Interfejs internetowy Datanode dla Hadoop
Interfejs internetowy Datanode dla Hadoop Aby uzyskać dostęp do interfejsu internetowego Manager Resource YARN, który wyświetli wszystkie obecnie działające zadania w klastrze Hadoop, przejdź do http: // hadoop-hostname-or-p: 8088
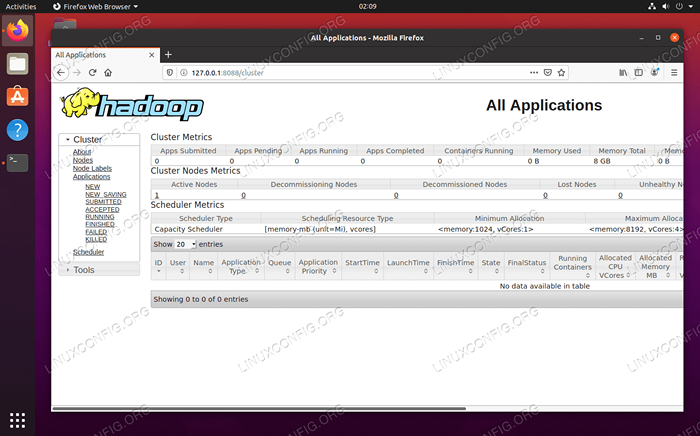 Interfejs internetowy menedżera zasobów przędzy dla Hadoop
Interfejs internetowy menedżera zasobów przędzy dla Hadoop Wniosek
W tym artykule widzieliśmy, jak zainstalować Hadoop w jednym klastrze węzłów w Ubuntu 20.04 Focal Fossa. Hadoop zapewnia nam obsługujące rozwiązanie do radzenia sobie z dużymi zbiorami danych, umożliwiając nam korzystanie z klastrów do przechowywania i przetwarzania naszych danych. Ułatwia naszą żywotność podczas pracy z dużymi zestawami danych z elastyczną konfiguracją i wygodnym interfejsem internetowym.
Powiązane samouczki Linux:
- Rzeczy do zainstalowania na Ubuntu 20.04
- Jak utworzyć klaster Kubernetes
- Ubuntu 20.04 WordPress z instalacją Apache
- Jak zainstalować Kubernetes na Ubuntu 20.04 Focal Fossa Linux
- Jak pracować z WooCommerce Rest API z Pythonem
- Zagnieżdżone pętle w skryptach Bash
- Rzeczy do zrobienia po zainstalowaniu Ubuntu 20.04 Focal Fossa Linux
- Mastering Bash Script Loops
- Jak zainstalować Kubernetes na Ubuntu 22.04 JAMMY Jellyfish…
- Wprowadzenie do automatyzacji, narzędzi i technik Linuksa