

Najlepsze praktyki wdrażania serwera Hadoop na CentOS/RHEL 7 - Część 1

- 2523
- 626
- Juliusz Janicki
W tej serii artykułów zamierzamy omówić całość Budynek klastra Cloudera Hadoop budynek z Sprzedawca I Przemysłowy Zalecane najlepsze praktyki.
Część 1: Najlepsze praktyki wdrażania serwera Hadoop na CentOS/RHEL 7 Część 2: Konfigurowanie warunków wstępnych Hadoop i utwardzania bezpieczeństwa Część 3: Jak zainstalować i skonfigurować Cloudera Manager na Centos/RhEL 7 Część 4: Jak zainstalować CDH i skonfigurować umiejscowienie serwisowe w CentOS/RHEL 7 Część 5: Jak skonfigurować wysoką dostępność Namenode Część 6: Jak skonfigurować wysoką dostępność dla menedżera zasobów Część 7: Jak zainstalować i skonfigurować Hive z wysoką dostępnością Część 8: Jak zainstalować i skonfigurować Sentry (narzędzie autoryzacji) Część 9: Jak zainstalować Kerberos (kerberowanie klastra) do uwierzytelniania Hadoop Część 10: Jak dostroić klaster (strojenie przędzy) na centos/RHEL 7OS instalacja i działanie OS Wymagania wstępne to pierwsze kroki do budowy Klaster Hadoop. Hadoop może działać na różnych smaku platformy Linux: Centos, Czerwony kapelusz, Ubuntu, Debian, SUSE itp., W produkcji w czasie rzeczywistym większość Klastry Hadoop są zbudowane na szczycie RHEL/CENTOS, użyjemy Centos 7 do demonstracji w tej serii samouczków.
W organizacji instalacja systemu operacyjnego można wykonać za pomocą Kickstart. Jeśli jest to klaster węzłów od 3 do 4, instalacja ręczna jest możliwa, ale jeśli zbudujemy duży klaster z więcej niż 10 węzłami, nudne jest zainstalowanie OS jeden po drugim. W tym scenariuszu metoda Kickstart pojawia się na zdjęciu, możemy kontynuować masową instalację za pomocą Kickstart.
Osiągnięcie dobrej wydajności od Środowisko Hadoop zależy od dostarczenia właściwego sprzętu i oprogramowania. Tak więc budowanie produkcji Klaster Hadoop Obejmuje wiele rozważań dotyczących sprzętu i oprogramowania.
W tym artykule przejdziemy przez różne testy porównawcze dotyczące instalacji systemu operacyjnego i najlepszych praktyk wdrażania Serwer klastra Cloudera Hadoop NA Centos/Rhel 7.
Ważna uwaga i najlepsze praktyki wdrażania serwera Hadoop
Poniżej znajdują się najlepsze praktyki konfigurowania wdrażania Serwer klastra Cloudera Hadoop NA Centos/Rhel 7.
- Serwery Hadoop nie wymagają standardowych serwerów przedsiębiorstwa do budowy klastra, wymaga sprzętu towarowego.
- W klastrze produkcyjnym zalecane są dyski od 8 do 12. Zgodnie z naturą obciążenia, musimy zdecydować o tym. Jeśli klaster jest przeznaczony do aplikacji wymagających obliczeniowych, posiadanie od 4 do 6 dysków jest najlepszą praktyką, aby uniknąć problemów we/wy.
- Napędy danych powinny być podzielone indywidualnie, na przykład - począwszy od /Data01 Do /Data10.
- Konfiguracja RAID nie jest zalecana dla węzłów pracowniczych, ponieważ sam Hadoop zapewnia tolerancję błędów na dane poprzez domyślnie odtworzenie bloków do 3. Więc Jbod jest najlepszy dla węzłów pracowniczych.
- Dla serwerów głównych, RAID 1 to najlepsza praktyka.
- Domyślny system plików Centos/Rhel 7.X Jest XFS. Hadoop obsługuje XFS, ext3 i ext4. Zalecany system plików jest ext3, ponieważ jest testowany pod kątem dobrej wydajności.
- Wszystkie serwery powinny mieć tę samą wersję systemu operacyjnego, co najmniej to samo drobne wydanie.
- Najlepszą praktyką jest posiadanie jednorodnego sprzętu (wszystkie węzły pracownicze powinny mieć te same charakterystyki sprzętowe (pamięć RAM, przestrzeń dysku i rdzeń itp.).
- Zgodnie z obciążeniem klastrowym (zrównoważone obciążenie pracą, intensywne obliczenie, intensywne we/wy) i rozmiar, planowanie zasobów (RAM, CPU) na serwer będą się różnić.
Znajdź poniższy przykład partycjonowania dysku serwerów pamięci 24 TB.
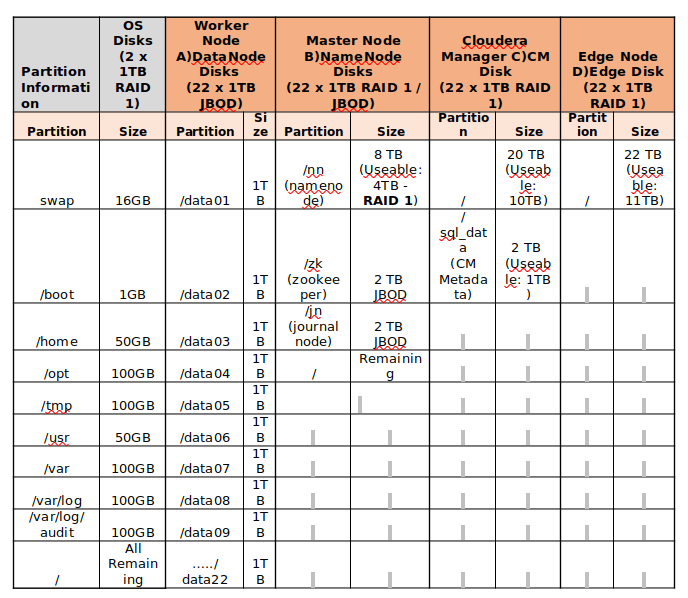 Partycjonowanie dysku
Partycjonowanie dysku Instalowanie CentOS 7 dla wdrożenia serwera Hadoop
Rzeczy, które musisz wiedzieć przed zainstalowaniem Centos 7 serwer dla Serwer Hadoop.
- Minimalna instalacja wystarczy Serwery Hadoop (Węzły robotnicze;.
- Konfigurowanie sieci, nazwa hosta i inne ustawienia związane z systemem operacyjnym można wykonać po instalacji systemu operacyjnego.
- W czasie rzeczywistym dostawcy serwerów będą mieć własną konsolę do interakcji i zarządzania serwerami, na przykład - serwery Dell mają IDRAC, który jest urządzeniem, osadzonym w serwerach. Za pomocą tego interfejsu IDRAC możemy zainstalować system operacyjny z posiadaniem obrazu systemu operacyjnego w naszym systemie lokalnym.
W tym artykule zainstalowaliśmy system operacyjny (Centos 7) W wirtualnej maszynie VMware. Tutaj nie będziemy mieć wielu dysków do wykonywania partycji. Centos jest podobny do Rhel (ta sama funkcjonalność), więc zobaczymy kroki do zainstalowania Centos.
1. Zacznij od pobrania Centos 7.X ISO Obraz w lokalnym systemie Windows i wybierz go podczas uruchamiania maszyny wirtualnej. Wybierać 'Zainstaluj Centos 7' jak pokazano.
 Zainstaluj menu rozruchowe Centos 7
Zainstaluj menu rozruchowe Centos 7 2. Wybierz Język, domyślnie będzie język angielski, i kliknij Kontynuować.
 Wybierz język Centos 7
Wybierz język Centos 7 3. Wybór oprogramowania - Wybierz 'Minimalna instalacja„i kliknij”Zrobione'.
 Wybór oprogramowania Centos
Wybór oprogramowania Centos 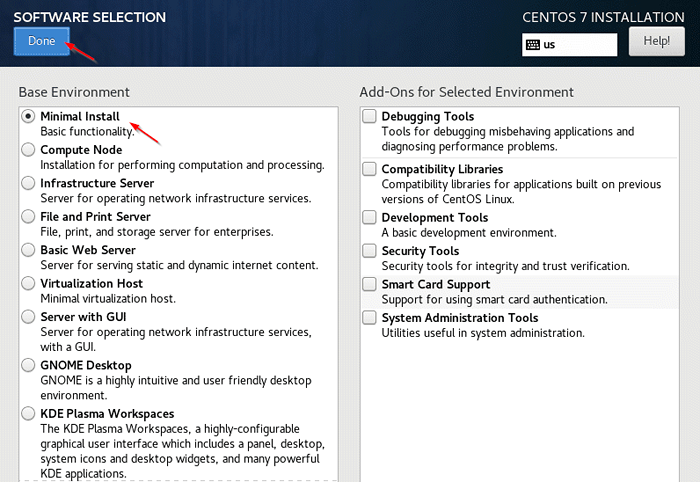 Minimalna instalacja centu 7
Minimalna instalacja centu 7 4. Ustaw hasło roota Jak skłoni nas do ustawienia.
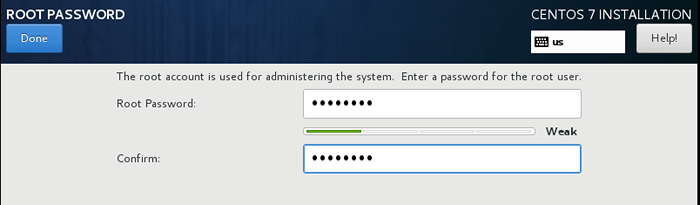 Ustaw hasło roota
Ustaw hasło roota 5. Miejsce instalacji - To ważny krok, aby być ostrożnym. Musimy wybrać dysku, w którym należy zainstalować system operacyjny, dedykowany dysk należy wybrać dla systemu operacyjnego. Kliknij 'Miejsce instalacji„I wybierz dysk, w czasie rzeczywistym będzie tam wiele dysków, musimy wybrać, preferowane”SDA'.
 Wybierz miejsce docelowe instalacji
Wybierz miejsce docelowe instalacji 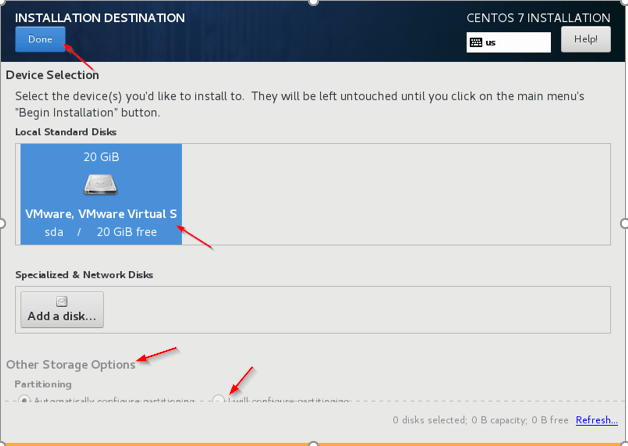 Wybierz dysk do instalacji Centos
Wybierz dysk do instalacji Centos 6. Inne opcje przechowywania - Wybierz drugą opcję (skonfiguruję partycjonowanie), aby skonfigurować partycje związane z systemem operacyjnym, jak /var, /var/log, /dom, /TMP, /optować, /zamieniać.
 Manual Centos Particing
Manual Centos Particing 7. Po zakończeniu rozpocznij instalację.
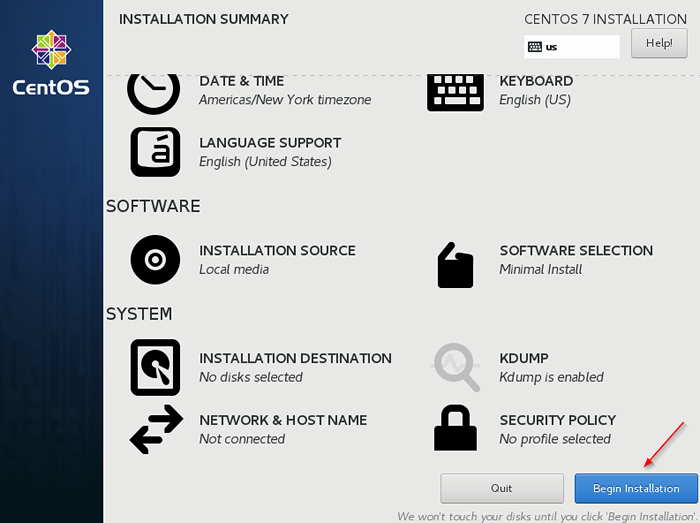 Rozpocznij instalację Centos
Rozpocznij instalację Centos  Instalacja Centos 7
Instalacja Centos 7 8. Po zakończeniu instalacji ponownie uruchom serwer.
 Instalacja Centos 7 zakończona
Instalacja Centos 7 zakończona 9. Zaloguj się do serwera i ustaw nazwę hosta.
# Status hostnamekectl # hostNamEctl Set-Hostname TecMint # Status HostNamEctl
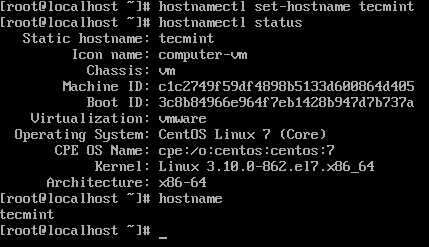 Ustaw nazwę hosta na Centos
Ustaw nazwę hosta na Centos Streszczenie
W tym artykule przeszliśmy kroki instalacji systemu operacyjnego i najlepsze praktyki dla partycjonowania systemu plików. Są to wszystkie ogólne wytyczne, zgodnie z naturą obciążenia pracą, możemy być konieczne skoncentrowanie się na większej liczbie niuansów, aby osiągnąć najlepszą wydajność klastra. Planowanie klastrów jest sztuką dla Hadoop administrator. W następnym artykule będziemy mieli głębokie zanurzenie się w warunkach wstępnych na poziomie systemu operacyjnego i utwardzanie bezpieczeństwa.
- « Jak podzielić ekran vim poziomo i pionowo w Linux
- 10 najlepszych bram i narzędzi do zarządzania API open source »