

Samouczek git dla początkujących

- 1257
- 256
- Laura Zygmunt
Jeśli używasz GNU/Linux dla dowolnej liczby szans, są całkiem niezłe, że słyszałeś o Git. Być może zastanawiasz się, czym dokładnie jest git i jak go używać? Git jest pomysłem Linus Torvalds, który rozwinął go jako system zarządzania kodem źródłowym podczas pracy nad jądrem Linux.
Od tego czasu został przyjęty przez wiele projektów oprogramowania i programistów ze względu na jego osiągnięcia szybkości i wydajności wraz z łatwością użytkowania. Git zyskał również popularność wśród pisarzy wszelkiego rodzaju, ponieważ można go używać do śledzenia zmian w dowolnym zestawie plików, a nie tylko kodzie.
W tym samouczku nauczysz się:
- Co to jest git
- Jak zainstalować GIT na GNU/Linux
- Jak skonfigurować git
- Jak używać git do tworzenia nowego projektu
- Jak klonować, zatwierdzić, scalać, pchać i rozgałęzić za pomocą polecenia GIT
Samouczek git dla początkujących Zastosowane wymagania i konwencje oprogramowania
| Kategoria | Wymagania, konwencje lub wersja oprogramowania |
|---|---|
| System | Każdy system operacyjny GNU/Linux |
| Oprogramowanie | git |
| Inny | Uprzywilejowany dostęp do systemu Linux jako root lub za pośrednictwem sudo Komenda. |
| Konwencje | # - Wymaga, aby podane polecenia Linux są wykonywane z uprawnieniami root bezpośrednio jako użytkownik root lub za pomocą sudo Komenda$ - Wymaga, aby podane polecenia Linux zostały wykonane jako zwykły użytkownik niepewny |
Co to jest git?
Więc co to jest git? GIT jest specyficzną implementacją kontroli wersji znanej jako rozproszony system kontroli rewizji, który śledzi zmiany w czasie do zestawu plików. Git umożliwia zarówno śledzenie historii lokalnej, jak i współpracy. Zaletą wspólnego śledzenia historii jest to, że dokumentuje nie tylko samą zmianę, ale kto, co, kiedy i dlaczego za zmianą. Podczas współpracy zmiany dokonane przez różnych współpracowników można później połączyć z zjednoczonym ciałem pracy.
Jaki jest rozproszony system kontroli rewizji?
Więc jaki jest rozproszony system kontroli rewizji? Rozproszone systemy kontroli rewizji nie są oparte na serwerze centralnym; Każdy komputer ma pełne repozytorium treści przechowywane lokalnie. Główną korzyścią jest to, że nie ma ani jednego punktu niepowodzenia. Serwer może być używany do współpracy z innymi osobami, ale jeśli stanie się coś nieoczekiwanego, każdy ma kopię zapasową danych przechowywanych lokalnie (ponieważ GIT nie zależy od tego serwera) i można go łatwo przywrócić do nowego serwer.
Kto jest git?
Chcę podkreślić, że GIT może być całkowicie lokalnie używany przez osobę, nie trzeba łączyć się z serwerem lub współpracować z innymi, ale ułatwia to w razie potrzeby. Być może myślisz coś w stylu „Wow, to brzmi jak dużo złożoności. To musi być naprawdę skomplikowane zaczynanie z git.". Cóż, byś się mylił!
Git koncentruje się na przetwarzaniu treści lokalnych. Jako początkujący możesz na razie bezpiecznie zignorować wszystkie sieciowe możliwości. Najpierw patrzymy na to, jak możesz używać GIT do śledzenia własnych projektów osobistych na lokalnym komputerze, a następnie przyjrzymy się przykładowi korzystania z funkcji sieci GIT i na koniec zobaczymy przykład rozgałęzienia.
Instalowanie git
Instalowanie GIT na GNU/Linux jest tak proste, jak korzystanie z menedżera pakietów w wierszu poleceń, jak instalacja dowolnego innego pakietu. Oto kilka przykładów tego, jak można to zrobić w niektórych popularnych dystrybucjach.
W systemach opartych na debian i debian, takich jak Ubuntu, używają apt.
$ sudo apt-get instaluj git
W systemach Redhat Enterprise Linux i Redhat, takich jak Fedora Użyj Yum.
$ sudo yum instaluj git
(Uwaga: w wersji 22 lub nowszej Fedora zastąp mniam DNF)
$ sudo dnf instaluj git
Na arch Linux Użyj Pacmana
$ sudo pacman -s git
Konfigurowanie git
Teraz git jest instalowany w naszym systemie i aby go użyć, musimy tylko wyciągnąć podstawową konfigurację. Pierwszą rzeczą, którą musisz zrobić, jest skonfigurowanie e-maila i nazwy użytkownika w Git. Zauważ, że nie są one używane do logowania do żadnej usługi; są po prostu używane do udokumentowania, jakie zmiany zostały wprowadzone podczas nagrywania zatrudnionych.
Aby skonfigurować e-mail i nazwę użytkownika, wprowadź następujące polecenia do terminala, zastępując e-mail i nazwę jako wartości między znakami cytatowymi.
$ git config -global użytkownik.e -mail „yourail@e -mailDOMain.com "$ git config -global użytkownik.Nazwa „Twoja nazwa użytkownika”
W razie potrzeby te dwie informacje można zmienić w dowolnym momencie, ponowne wydanie powyższych poleceń o różnych wartościach. Jeśli zdecydujesz się to zrobić, git zmieni twoją nazwę i adres e-mail dla historycznych zapisów zobowiązań, ale nie zmieni ich w poprzednich zatwierdzeniach, więc zaleca się upewnienie się, że początkowo nie ma błędów.
Aby zweryfikować swoją nazwę użytkownika i e-mail, wprowadź następujące:
$ git config -l
 Ustaw i zweryfikuj swoją nazwę użytkownika i e-mail z git
Ustaw i zweryfikuj swoją nazwę użytkownika i e-mail z git Tworzenie pierwszego projektu GIT
Aby skonfigurować projekt GIT po raz pierwszy, należy go zainicjować za pomocą następującego polecenia:
$ git init initsname
Katalog jest tworzony w bieżącym katalogu roboczym za pomocą podanej nazwy projektu. Będzie to zawierać pliki/foldery projektu (kod źródłowy lub inna podstawowa treść, często nazywana drzewem roboczym) wraz z plikami sterującymi używanymi do śledzenia historii. GIT przechowuje te pliki sterujące w .git Ukryty subkredyt.
Podczas pracy z GIT powinieneś stworzyć nowo utworzony folder projektu swój obecny katalog roboczy:
$ CD ProjectName
Użyjmy polecenia dotykowego, aby utworzyć pusty plik, którego będziemy używać do utworzenia prostego programu Hello World.
$ Touch Helloworld.C
Aby przygotować pliki w katalogu, które mają być zaangażowane w system kontroli wersji, którego używamy GIT Add. Jest to proces znany jako inscenizacja. Uwaga, możemy użyć . Aby dodać wszystkie pliki w katalogu, ale jeśli chcemy tylko dodać wybrane pliki lub pojedynczy plik, zastąpimy . z pożądaną nazwą pliku, jak zobaczysz w następnym przykładzie.
$ git add .
Nie bój się popełnić
Zobowiązanie jest przeprowadzane w celu stworzenia stałego historycznego zapisu dokładnie tego, jak istnieją pliki projektowe w tym momencie. Wykonujemy zatwierdzenie za pomocą -M flaga, aby stworzyć historyczne przesłanie ze względu na jasność.
To przesłanie zazwyczaj opisywałoby, jakie zmiany zostały wprowadzone lub jakie wydarzenie miało miejsce, abyśmy chcieli w tym czasie wykonać zatwierdzenie. Stan treści w momencie tego zatwierdzenia (w tym przypadku pusty plik „Hello World”, który właśnie stworzyliśmy) może zostać ponownie odwiedzony. Przyjrzymy się, jak to zrobić.
$ git commit -m „Pierwszy zatwierdzenie projektu, tylko pusty plik”
Teraz śmiałmy i utwórzmy kod źródłowy w tym pustym pliku. Korzystanie z wybranego edytora tekstu Wprowadź następujące (lub skopiuj i wklej) do Helloworld.p plik i zapisz go.
#Include int main (void) printf („hello, świat!\ n "); return 0;Teraz, gdy zaktualizowaliśmy nasz projekt, przejdźmy dalej i wykonajmy Git Add i Git Commip ponownie
$ git dodaj helloworld.c $ git commit -m "Dodano kod źródłowy do Helloworld.C"
Czytanie dzienników
Teraz, gdy mamy dwa zatwierdzenia w naszym projekcie, możemy zacząć widzieć, jak przydatne może być historyczny zapis zmian w naszym projekcie w czasie. Śmiało i wprowadź następujące do swojego terminala, aby zobaczyć jak dotąd przegląd tej historii.
$ git log
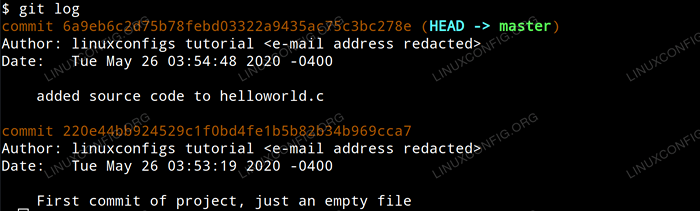 Czytanie dzienników git
Czytanie dzienników git Zauważysz, że każde zatwierdzenie jest zorganizowane przez własny unikalny identyfikator hash SHA-1 oraz że autor, data i zatwierdzenie są prezentowane dla każdego zatwierdzenia. Zauważysz również, że najnowsze zatwierdzenie jest określane jako GŁOWA na wyjściu. GŁOWA to nasza obecna pozycja w projekcie.
Aby zobaczyć, jakie zmiany zostały wprowadzone w danym zatwierdzeniu, po prostu wydaj polecenie Git Show z HASH ID jako argument. W naszym przykładzie wejdziemy:
$ git show 6A9EB6C2D75B78FEBD03322A9435AC75C3BC278E
Który wytwarza następujące dane wyjściowe.
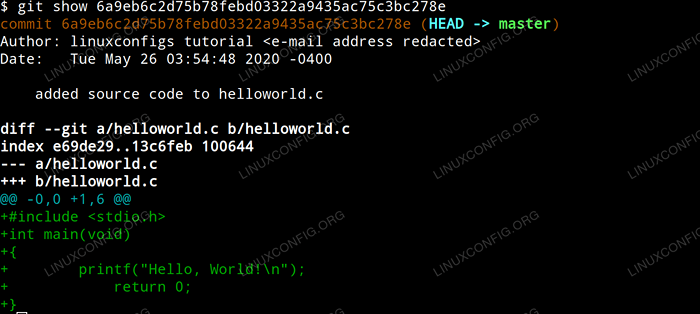 Pokaż zmiany GIT
Pokaż zmiany GIT Co jeśli chcemy powrócić do stanu naszego projektu podczas poprzedniego zatwierdzenia, zasadniczo całkowicie cofając zmiany, które wprowadziliśmy tak, jakby nigdy się nie wydarzyły?
Aby cofnąć zmiany, które wprowadziliśmy w naszym poprzednim przykładzie, jest to tak proste, jak zmiana GŁOWA używając Git Reset polecenie za pomocą identyfikatora zatwierdzenia, do którego chcemy powrócić jako argument. --twardy Mówi Git, że chcemy zresetować sam zatwierdzenie, obszar inscenizacji (pliki, które przygotowywaliśmy do popełnienia za pomocą GIT Add) i roboczego drzewa (pliki lokalne, które pojawiają się w folderze projektu na naszym dysku).
$ git reset -twardy 220E44BB924529C1F0BD4FE1B5B82B34B969CCA7
Po wykonaniu tego ostatniego polecenia, badanie treści
Witaj świecie.C
Plik ujawni, że powrócił do dokładnego stanu, w którym był podczas naszego pierwszego zatwierdzenia; pusty plik.
 Powrócić do zatwierdzenia za pomocą twardego resetowania do określonego
Powrócić do zatwierdzenia za pomocą twardego resetowania do określonego GŁOWA Śmiało i ponownie wprowadź Git Log do terminalu. Teraz zobaczysz nasze pierwsze zatwierdzenie, ale nie nasze drugie zatwierdzenie. Dzieje się tak, ponieważ GIT Log pokazuje tylko bieżące zatwierdzenie i wszystkie jego rodzicielskie zobowiązania. Aby zobaczyć drugie zatwierdzenie, że wprowadziliśmy reflog git. Git RefLog wyświetla odniesienia do wszystkich zmian, które wprowadziliśmy.
Gdybyśmy zdecydowali, że resetowanie do pierwszego zatwierdzenia było błędem, moglibyśmy użyć identyfikatora hash SHA-1 naszego drugiego zatwierdzenia, jak wyświetlono w wyjściu refLogów Git. To zasadniczo przerobiłoby to, co właśnie cofnęliśmy i spowodowałoby, że odzyskałoby treść w naszym pliku.
Praca ze zdalnym repozytorium
Teraz, gdy przekroczyliśmy podstawy pracy z git lokalnie, możemy zbadać, jak różni się przepływ pracy, gdy pracujesz nad projektem hostowanym na serwerze. Projekt może być hostowany na prywatnym serwerze GIT należącym do organizacji, z którą pracujesz lub może być hostowany w usłudze hostingowej repozytorium online, takiej jak Github.
Na potrzeby tego samouczka Załóżmy, że masz dostęp do repozytorium Github i chcesz zaktualizować projekt, który tam hostujesz.
Najpierw musimy sklonować repozytorium lokalnie za pomocą polecenia GIT Clone za pomocą adresu URL projektu i uczynić klonowany katalog projektu nasz obecny katalog roboczy.
$ Git Clone Project.URL/ProjectName.Git $ CD ProjectName
Następnie edytujemy lokalne pliki, wdrażając pożądane zmiany. Po edycji plików lokalnych dodajemy je do obszaru inscenizacji i wykonujemy zatwierdzenie tak jak w naszym poprzednim przykładzie.
$ git add . $ git commit -m „Wdrażanie moich zmian w projekcie”
Następnie musimy przesunąć zmiany, które wprowadziliśmy lokalnie na serwer GIT. Poniższe polecenie będzie wymagało uwierzytelnienia za pomocą poświadczeń na zdalnym serwerze (w tym przypadku nazwa użytkownika i hasło GitHub) przed naciskiem na zmiany.
Zauważ, że zmiany popchnięte do dzienników zatwierdzenia w ten sposób użyją e-maila i nazwy użytkownika, które określiliśmy podczas pierwszej konfiguracji git.
$ git push
Wniosek
Teraz powinieneś czuć się komfortowo instalowanie git, konfigurowanie go i używanie go do pracy z lokalnymi i zdalnymi repozytoriami. Masz praktyczną wiedzę, aby dołączyć do stale rozwijającej się społeczności ludzi, którzy wykorzystują moc i wydajność GIT jako rozproszony system kontroli rewizji. Cokolwiek możesz pracować, mam nadzieję, że te informacje zmieniają sposób, w jaki myślisz o swoim przepływie pracy na lepsze.
Powiązane samouczki Linux:
- Rzeczy do zainstalowania na Ubuntu 20.04
- Wprowadzenie do automatyzacji, narzędzi i technik Linuksa
- Rzeczy do zrobienia po zainstalowaniu Ubuntu 20.04 Focal Fossa Linux
- Najlepszy Linux Distro dla programistów
- Mint 20: Lepsze niż Ubuntu i Microsoft Windows?
- Mastering Bash Script Loops
- Pobierz Linux
- Zainstaluj Arch Linux na stacji roboczej VMware
- Rzeczy do zainstalowania na Ubuntu 22.04
- Rzeczy do zrobienia po zainstalowaniu Ubuntu 22.04 JAMMY Jellyfish…