

Jak zainstalować i skonfigurować Hive z wysoką dostępnością - Część 7

- 1751
- 543
- Maurycy Napierała
Ul jest Hurtownia danych Model w Hadoop Eco-System. Może działać jako narzędzie ETL na górze Hadoop. Umożliwienie wysokiej dostępności (HA) na Hive nie jest podobne, jak to robimy w usługach głównych, takich jak Namenode i Resource Manager.
Automatyczne awaryjne nie nastąpi w Ul (Hiveserver2). Jeśli w ogóle Hiveserver2 (HS2) Niepowodzenie, uruchamianie zadań na tym nieudanym HS2 dostanie porażkę. Musimy ponownie przesłać zadanie, aby zadanie mogło działać na innych Hiveserver2. Więc włączając Ha NA HS2 to nic innego, że zwiększenie liczby HS2 komponenty w Grupa.
W tym artykule zobaczymy kroki do zainstalowania i włączenia Duża dostępność z Ul.
Wymagania
- Najlepsze praktyki wdrażania serwera Hadoop na CentOS/RHEL 7 - Część 1
- Konfigurowanie warunków wstępnych Hadoop i utwardzania bezpieczeństwa - część 2
- Jak zainstalować i skonfigurować Cloudera Manager w Centos/Rhel 7 - Część 3
- Jak zainstalować CDH i skonfigurować umiejscowienie serwisowe w Centos/RHEL 7 - Część 4
- Jak skonfigurować wysoką dostępność dla nazwy - część 5
- Jak skonfigurować wysoką dostępność dla menedżera zasobów - część 6
Zacznijmy…
Hive Instalacja i konfiguracja
1. Zaloguj się do Menedżer Cloudera na poniższym adresie URL i przejdź do Menedżer Cloudera -> Dodaj usługę.
http: // 13.233.129.39: 7180/cmf/dom
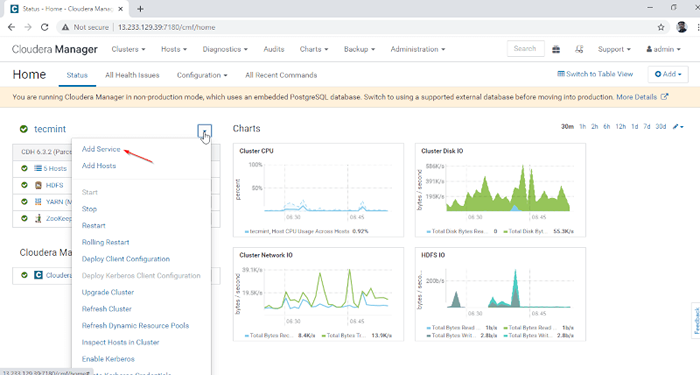 Dodaj usługę w Cloudera Manager
Dodaj usługę w Cloudera Manager 2. Wybierz usługę 'Ul'.
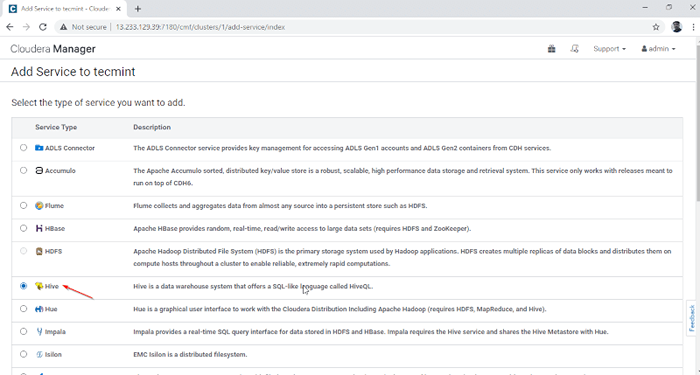 Wybierz usługę Hive
Wybierz usługę Hive 3. Przypisz usługi na węzłach.
- Wejście - Jest to usługa klienta, w której użytkownik może uzyskać dostęp do Hive. Zwykle usługa ta zostanie umieszczona Krawędź Węzły poświęcone użytkownikom.
- Hive przerzuty - Jest to centralne repozytorium do przechowywania metadanych Hive.
- Serwer WebHcat - Jest to interfejs API internetowy dla hcatalogu i innych usług Hadoop.
- Hiveserver2 - Jest to interfejs klientów do wykonywania zapytania w Hive.
Po wybraniu serwerów kliknijKontynuować' kontynuować.
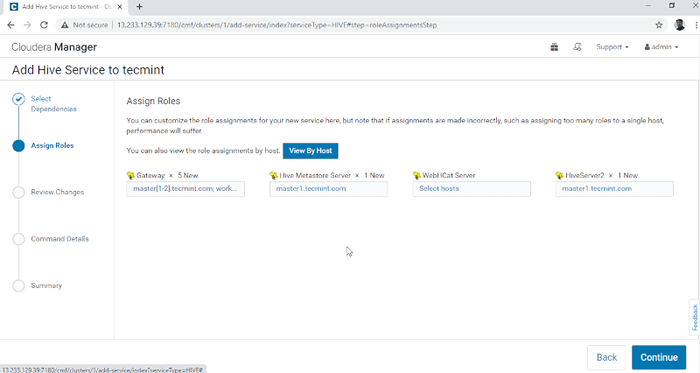 Przypisz usługę jako węzły
Przypisz usługę jako węzły 4. Hive Renastore potrzebuje bazy danych do przechowywania metadanych. Tutaj używamy domyślnego PostgreSQL baza danych, która jest wbudowana z CDH.
Poniżej wymienione szczegóły bazy danych zostaną wprowadzone automatycznie ”,”Połączenie testowe„Zostanie pominięty, ponieważ wspomniana baza danych zostanie utworzona w locie. W czasie rzeczywistym musimy utworzyć bazę danych w zewnętrznej bazie danych i przetestować połączenie, aby kontynuować. Po zakończeniu kliknijKontynuować'.
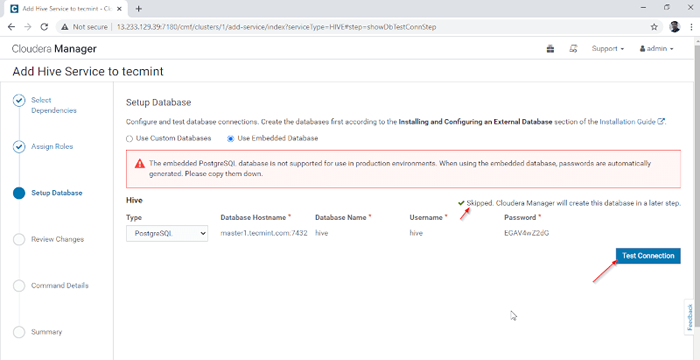 Konfiguracja bazy danych
Konfiguracja bazy danych 5. Skonfiguruj Hive Warehouse informator, /użytkownik/hive/magazyn jest domyślną ścieżką katalogu do przechowywania tabel Hive. Kliknij 'Kontynuować'.
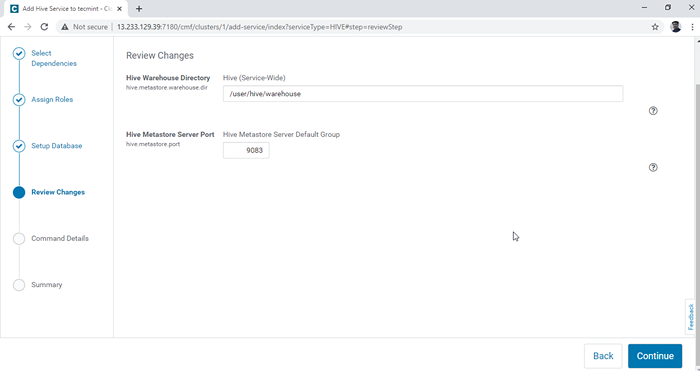 Wybierz Direktory Hive Warehouse
Wybierz Direktory Hive Warehouse 6. Rozpoczyna się instalacja Hive.
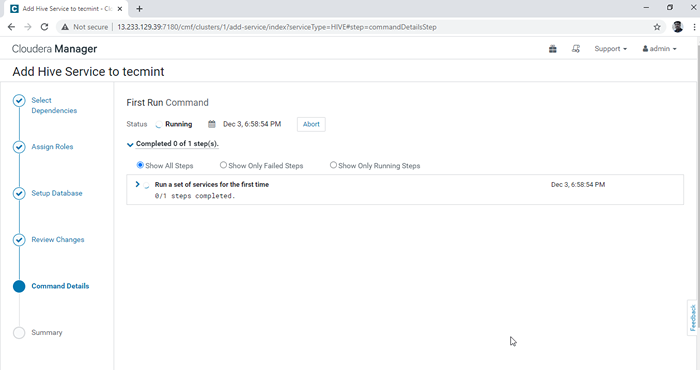 Postęp instalacyjny Hive
Postęp instalacyjny Hive 7. Po zakończeniu instalacji możesz uzyskać 'Skończone„Status. Kliknij 'Kontynuować'Aby kontynuować.
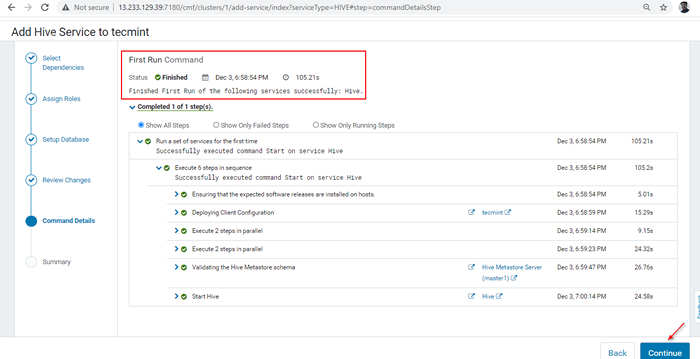 Ukończona instalacja Hive
Ukończona instalacja Hive 8. Instalacja i konfiguracja Hive zakończona pomyślnie. Kliknij 'Skończyć„Aby zakończyć procedurę instalacji.
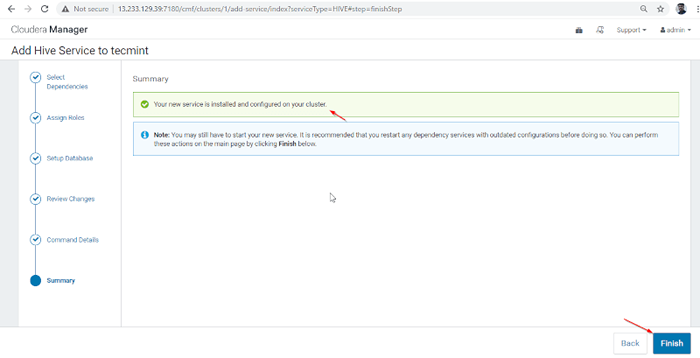 Zakończ instalację ula
Zakończ instalację ula 9. Możesz zobaczyć Ul Usługa dodana Grupa Poprzez Pulpit nawigacyjny Cloudera Manager.
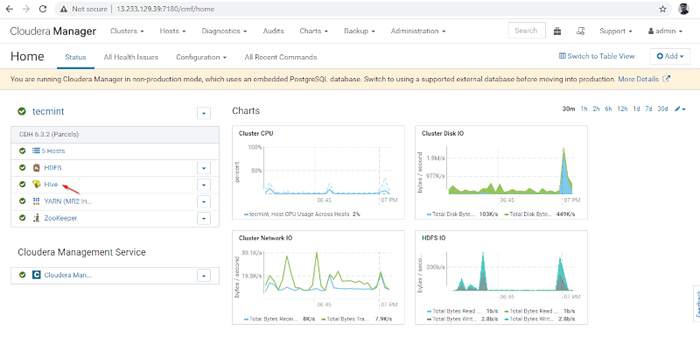 Dodano usługę Hive
Dodano usługę Hive 10. Możesz zobaczyć Hiveserver2 W Instancje z Ul. Dodaliśmy Hiveserver2 W Master1.
Menedżer Cloudera -> Ul -> Instancje -> Hiveserver2.
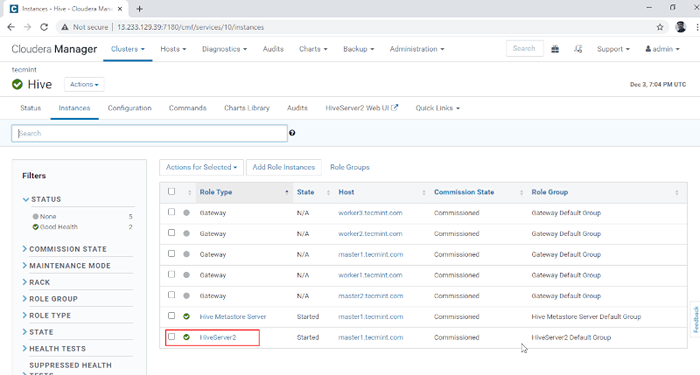 Zobacz instancje HiveServer2
Zobacz instancje HiveServer2 Umożliwianie wysokiej dostępności na Hive
11. Następnie dodaj rolę ula, idąc do Menedżer Cloudera -> Ul -> działania -> Dodaj rolę Instancje.
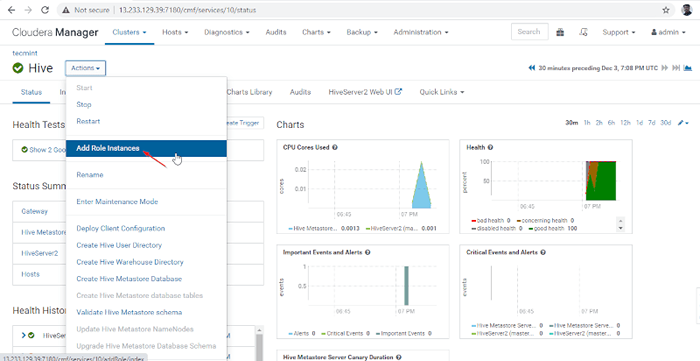 Dodaj instancję roli ula
Dodaj instancję roli ula 12. Wybierz serwery, na których chcesz umieścić dodatkowe Hiveserver2. Możesz dodać więcej niż dwa, nie ma limitu. Tutaj dodajemy dodatkowe Hiveserver2 W Master2.
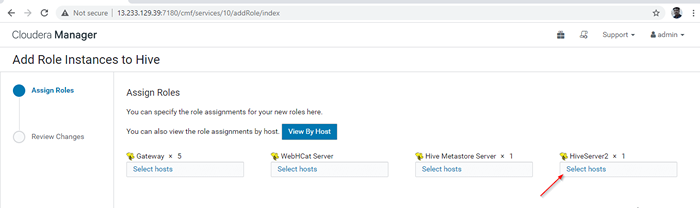 Wybierz serwer do Hive
Wybierz serwer do Hive 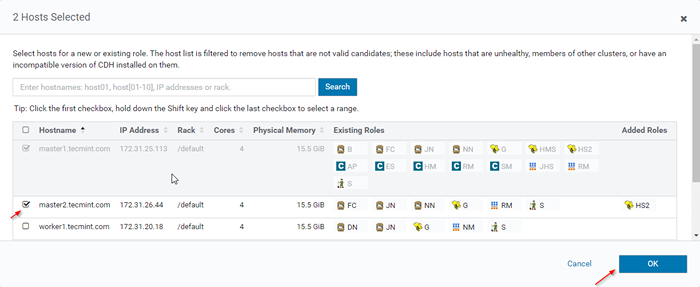 Wybierz serwer hosta
Wybierz serwer hosta 13. Po wybraniu serwera kliknijKontynuować'.
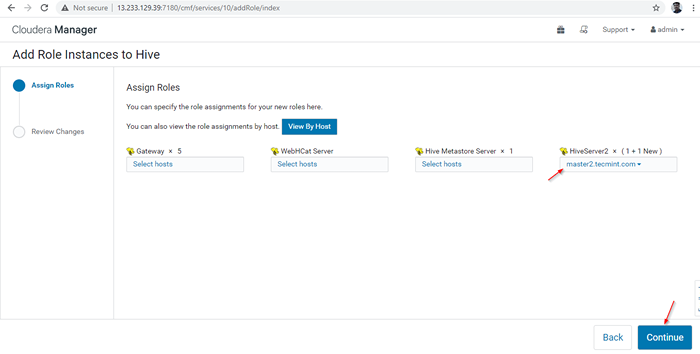 Dodano serwer
Dodano serwer 14. A Hiverserver2 zostanie dodane do Instancje Hive, Musisz to zacząć od pójścia Menedżer Cloudera -> Ul -> Instancje -> (Wybierz HiveServer2 dodane nowo) -> Działanie dla wybranych -> Początek.
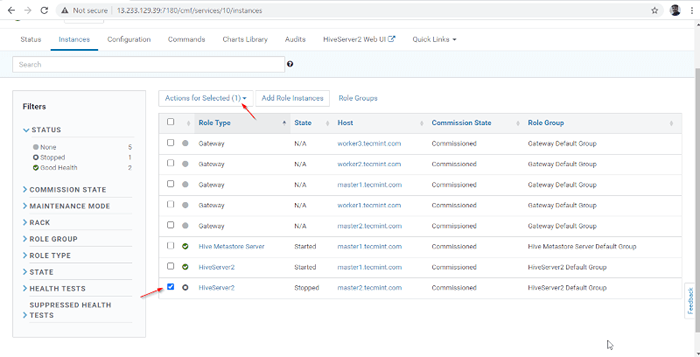 Wybierz serwer Hive
Wybierz serwer Hive 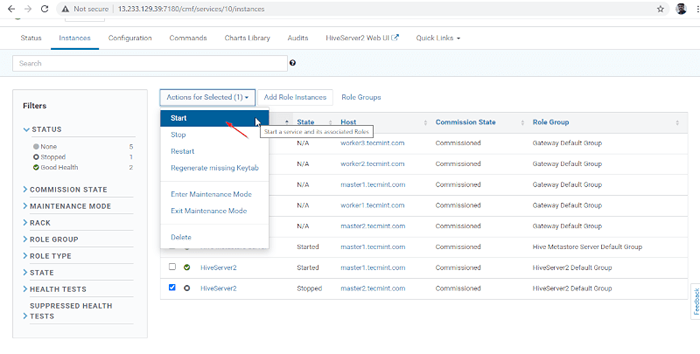 Rozpocznij serwer Hive
Rozpocznij serwer Hive 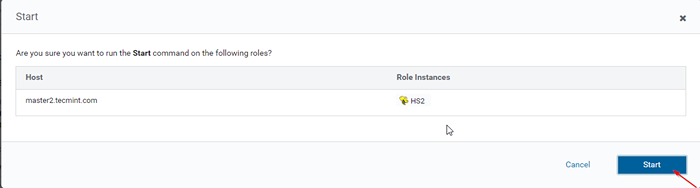 Uruchom serwer Hive
Uruchom serwer Hive 15. Raz Hiveserver2 Zaczął się Master2, Otrzymasz status 'Skończone'. Kliknij Zamknąć.
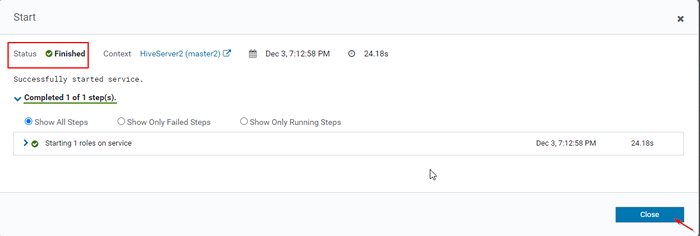 Status: skonczone
Status: skonczone 16. Możesz zobaczyć, zarówno Hiveserver2s biegną.
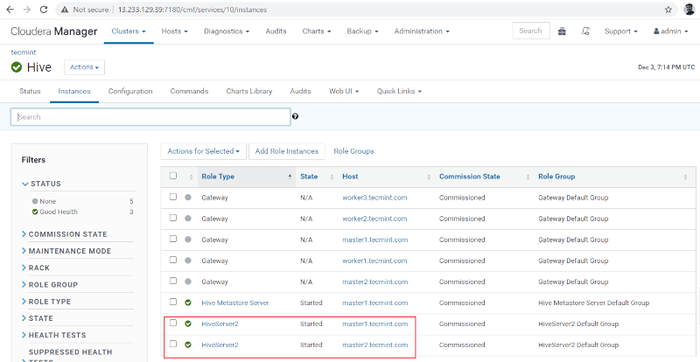 Sprawdź status serwerów Hive
Sprawdź status serwerów Hive Weryfikacja dostępności ula
Możemy połączyć Hiveserver2 za pośrednictwem Beeline, która jest cienkim klientem i linią poleceń. Używa sterownika JDBC do ustalenia połączenia.
17. Zaloguj się do serwera, gdzie Hive Gateway biegnie.
[[e -mail chroniony] ~] $ beeline
 Połącz się z HiveServer2
Połącz się z HiveServer2 18. Wejdz do JDBC ciąg połączenia, aby podłączyć Hiveserver2. W związku z tym strunowy Wspominamy Hiverserver2 (Master2) z domyślnym numerem portu 10000. Ten ciąg połączenia będzie się połączył tylko z Hiveserver2 który działa Master2.
Beeline> !Connect "jdbc: hive2: // master1.Tecmint.com: 10000 "
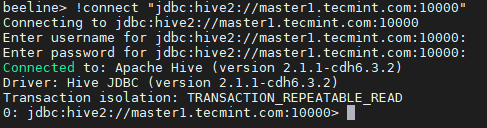 Ciąg połączenia JDBC
Ciąg połączenia JDBC 19. Uruchom próbkę zapytania.
0: jdbc: hive2: // master1.Tecmint.com: 10000> Pokaż bazy danych;
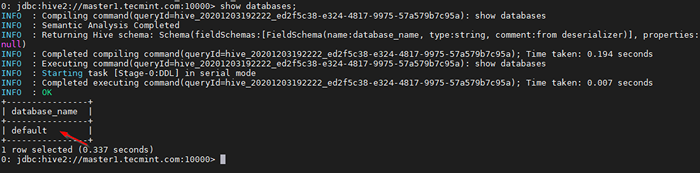 Uruchom zapytanie próbki
Uruchom zapytanie próbki Jest to domyślna baza danych, która jest wbudowana.
20. Użyj poniższego polecenia, aby zakończyć sesję ula.
0: jdbc: hive2: // master1.Tecmint.com: 10000> !zrezygnować
 Przestań sesję ula
Przestań sesję ula 21. Możesz użyć tego samego sposobu na połączenie Hiveserver2 kontynuować Master2.
Beeline> !Connect "jdbc: hive2: // master2.Tecmint.com: 10000 "
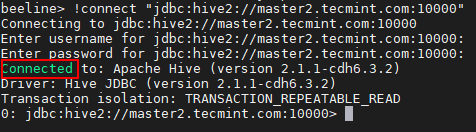 Połącz się z serwerem Hive
Połącz się z serwerem Hive 23. Możemy połączyć Hiveserver2 W Odkrycie Zookeeper tryb. W tej metodzie nie musimy wspominać Hiveserver2 Zamiast tego w ciągu połączenia używamy Zookeeper Aby odkryć dostępne Hiveserver2.
Tutaj możemy użyć równoważenia obciążenia zewnętrznego, aby zrównoważyć obciążenie między dostępnymi Hiverserver2. Poniższa konfiguracja musi włączyć Tryb odkrywania Zookeeper Idąc do Menedżer Cloudera -> Ul -> Konfiguracja.
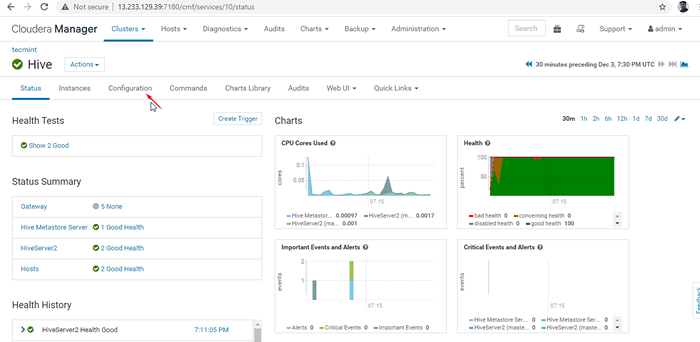 Włącz tryb odkrywania Zookeeper
Włącz tryb odkrywania Zookeeper 24. Następnie przeszukaj właściwość „HiveServer2 Zaawansowana konfiguracja fragment konfiguracji”I kliknij + symbol, aby dodać poniższą właściwość.
Nazwa: Hive.serwer2.wsparcie.dynamiczny.praca.Wartość odkrywania: prawdziwy opis:
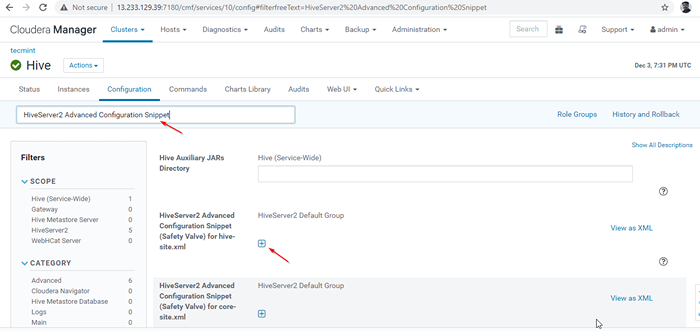 HiveServer2 Zaawansowana konfiguracja fragment konfiguracji
HiveServer2 Zaawansowana konfiguracja fragment konfiguracji 25. Po wprowadzeniu właściwości kliknij 'Zapisz zmiany'.
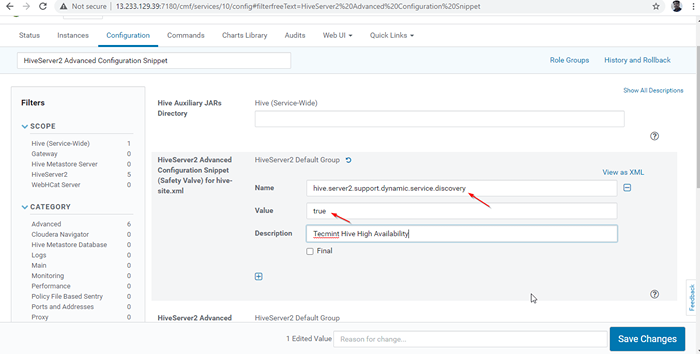 Dodaj właściwość
Dodaj właściwość 26. Gdy wprowadziliśmy zmiany w konfiguracji, trzeba ponownie uruchomić dotknięte usługi, klikając symbol koloru pomarańczowego, aby ponownie uruchomić Usługi.
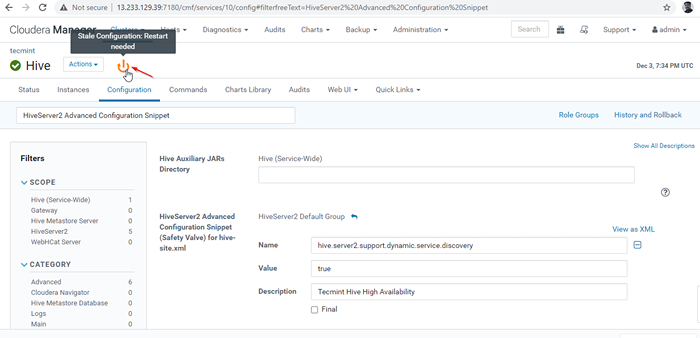 Uruchom ponownie usługi
Uruchom ponownie usługi 27. Kliknij 'Uruchom ponownie przestarzałe„Usługi.
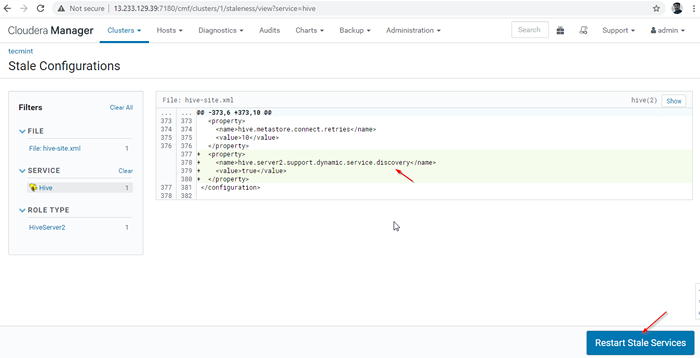 Uruchom ponownie stare usługi
Uruchom ponownie stare usługi 28. Dostępne są dwie opcje. Jeśli klaster jest w produkcji na żywo, musimy preferować ponowne uruchomienie, aby zminimalizować awarię. Ponieważ nowo instalujemy, możemy wybrać drugą opcję 'Ponownie wdrożyć konfigurację klienta'i kliknij'Zrestartuj teraz'.
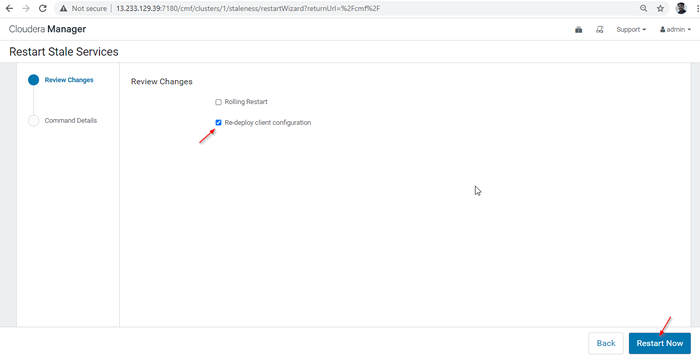 Ponownie wdrożyć konfigurację klienta
Ponownie wdrożyć konfigurację klienta 29. Po pomyślnym zakończeniu ponownego uruchomienia otrzymasz status 'Skończone'. Kliknij 'Skończyć„Aby ukończyć proces.
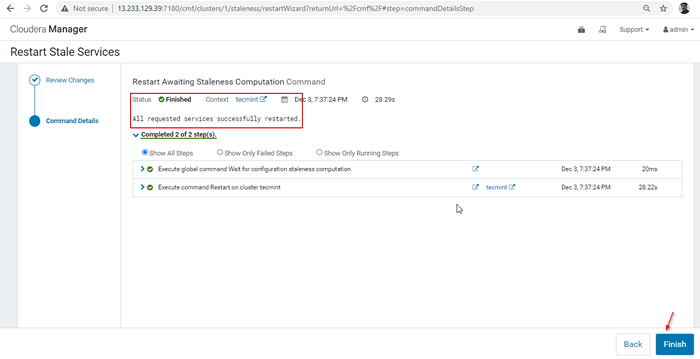 Zakończyć proces
Zakończyć proces 30. Teraz połączymy Hiveserver2 za pomocą Odkrycie Zookeeper tryb. w JDBC połączenie, ciąg, którego musimy użyć Zookeeper serwery z numerem portu 2081. Zbierz serwery Zookeeper, idąc Menedżer Cloudera -> Zookeeper -> Instancje -> (Zanotuj nazwy serwerów).
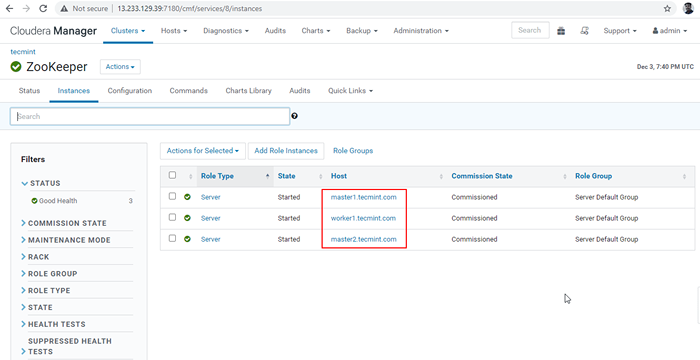 Serwery Zookeeper
Serwery Zookeeper To są trzy serwery o Zookeeper, 2181 to numer portu.
Master1.Tecmint.com: 2181 Master2.Tecmint.com: 2181 Worker1.Tecmint.com: 2181
31. Teraz wejdź linia powietrzna.
[[e -mail chroniony] ~] $ beeline
 Połącz się z Beeline
Połącz się z Beeline 32. Wejdz do JDBC ciąg połączenia, jak wspomniano poniżej. Musimy wspomnieć Tryb odkrywania usług I Przestrzeń nazw Zookeeper. 'Hiveserver2„jest domyślną przestrzenią nazw HiveServer2.
Beeline>!Connect "jdbc: hive2: // master1.Tecmint.com: 2181, Master2.Tecmint.com: 2181, robotnik1.Tecmint.com: 2181/; serviceDiscoveryMode = Zookeeper; ZookeeperNamespace = Hiveserver2 ”
 Wprowadź ciąg połączenia JDBC
Wprowadź ciąg połączenia JDBC 33. Teraz sesja jest połączona z Hiveserver2 kontynuować Master1. Uruchom próbkę zapytania, aby potwierdzić. Użyj poniższej komendy, aby utworzyć bazę danych.
0: jdbc: hive2: // master1.Tecmint.com: 2181, maszt> Utwórz bazę danych TecMint;
 Utwórz bazę danych
Utwórz bazę danych 34. Użyj poniższej komendy, aby wymienić bazę danych.
0: jdbc: hive2: // master1.Tecmint.com: 2181, maszt> pokaż bazy danych;
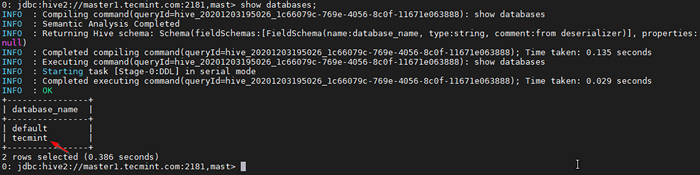 Lista bazy danych
Lista bazy danych 35. Teraz potwierdzimy wysoką dostępność w Tryb odkrywania Zookeeper. Iść do Menedżer Cloudera i zatrzymaj Hiveserver2 NA Master1 że testowaliśmy powyżej.
Menedżer Cloudera -> Ul -> Instancje -> (Wybierz Hiveserver2 NA Master1) -> Działanie dla wybranych -> Zatrzymywać się.
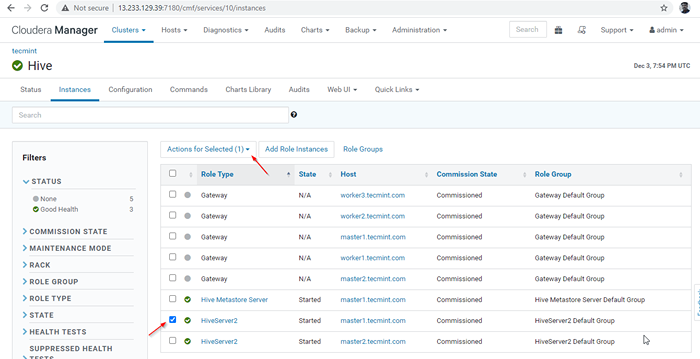 Wybierz serwer Hive
Wybierz serwer Hive 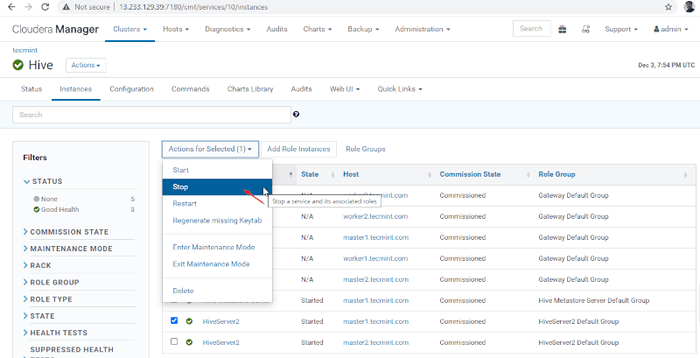 Zatrzymaj serwer Hive
Zatrzymaj serwer Hive 36. Kliknij 'Zatrzymywać się'. Po zatrzymaniu otrzymasz status 'Skończone'. Sprawdź Hiveserver2 NA Master1 Przechodząc do Ul -> Instancje.
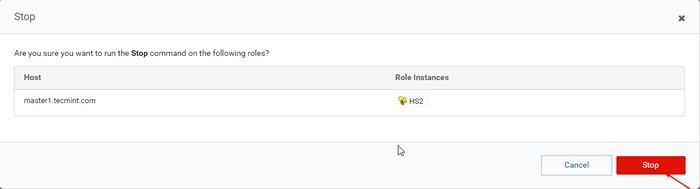 Zatrzymaj serwer Hive
Zatrzymaj serwer Hive 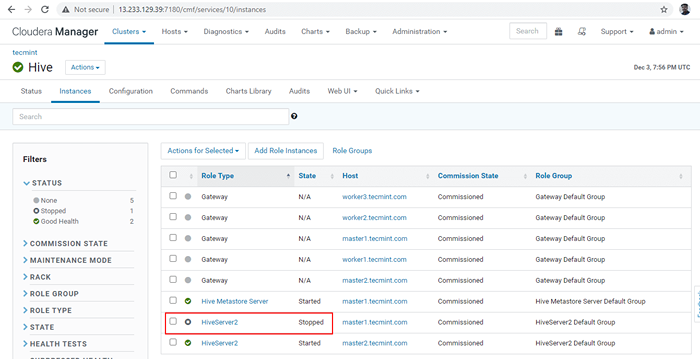 Sprawdź serwer Hive
Sprawdź serwer Hive 37. Wejdź do linia powietrzna i podłącz Hiveserver2 używając tego samego JDBC ciąg połączenia z Tryb odkrywania Zookeeper Tak jak w powyższych krokach.
[[e -mail chroniony] ~] $ beeline beeline>!Connect "jdbc: hive2: // master1.Tecmint.com: 2181, Master2.Tecmint.com: 2181, robotnik1.Tecmint.com: 2181/; serviceDiscoveryMode = Zookeeper; ZookeeperNamespace = Hiveserver2 ”
 Połącz Hiveserver2
Połącz Hiveserver2 Teraz będziesz podłączony do Hiveserver2 kontynuować Master2.
38. Sprawdź za pomocą zapytania.
0: jdbc: hive2: // master1.Tecmint.com: 2181, maszt> pokaż bazy danych;
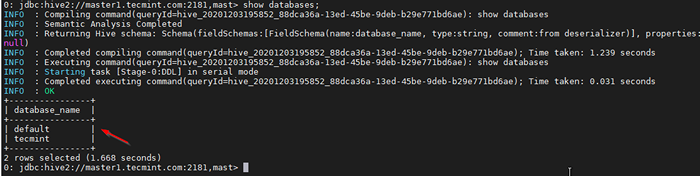 Sprawdzaj zapytanie o próbki
Sprawdzaj zapytanie o próbki Wniosek
W tym artykule przeszliśmy przez szczegółowe kroki, aby mieć Hive Data Warehouse Model w naszym Grupa z Duża dostępność. W środowisku produkcyjnym w czasie rzeczywistym więcej niż trzy Hiveserver2 zostanie umieszczony z Tryb odkrywania Zookeeper włączony.
Tutaj wszystkie Hiveserver2 rejestrują się w Zookeeper pod wspólnym Przestrzeń nazw. Zookeeper dynamicznie odkrywa dostępne Hiveserver2 i ustanawia sesję ula.
- « Jak zainstalować VMware Workstation 16 Pro w systemach Linux
- Jak zainstalować klaster Kubernetes na Centos 8 »