

Jak zainstalować iskrę na RHEL 8
- 3248
- 624
- Igor Madej
Apache Spark to rozproszony system obliczeń. Składa się z mistrza i jednego lub więcej niewolników, w których mistrz rozdziela pracę między niewolnikami, dając w ten sposób możliwość korzystania z naszych wielu komputerów do pracy nad jednym zadaniem. Można zgadnąć, że jest to rzeczywiście potężne narzędzie, w którym zadania wymagają dużych obliczeń do wykonania, ale można je podzielić na mniejsze fragmenty kroków, które można popchnąć do niewolników do pracy. Po uruchomieniu naszego klastra możemy pisać programy, aby działać w Python, Java i Scala.
W tym samouczku będziemy pracować na jednym komputerze z Red Hat Enterprise Linux 8 i zainstalujemy Master Spark i niewolnik na tym samym komputerze, ale pamiętaj, że kroki opisujące konfigurację niewolników można zastosować do dowolnej liczby komputerów, tworząc w ten sposób prawdziwy klaster, który może przetwarzać ciężkie obciążenia. Dodamy również niezbędne pliki jednostkowe do zarządzania i uruchomimy prosty przykład w stosunku do klastra dostarczonego z rozproszonym pakietem, aby upewnić się, że nasz system jest operacyjny.
W tym samouczku nauczysz się:
- Jak zainstalować Spark Master i Slave
- Jak dodać pliki jednostek systemowych
- Jak zweryfikować udane połączenie mistrzowskie
- Jak uruchomić proste przykładowe zadanie w klastrze
Spark Shell z Pyspark. Zastosowane wymagania i konwencje oprogramowania
| Kategoria | Wymagania, konwencje lub wersja oprogramowania |
|---|---|
| System | Red Hat Enterprise Linux 8 |
| Oprogramowanie | Apache Spark 2.4.0 |
| Inny | Uprzywilejowany dostęp do systemu Linux jako root lub za pośrednictwem sudo Komenda. |
| Konwencje | # - Wymaga, aby podane polecenia Linux są wykonywane z uprawnieniami root bezpośrednio jako użytkownik root lub za pomocą sudo Komenda$ - Wymaga, aby podane polecenia Linux zostały wykonane jako zwykły użytkownik niepewny |
Jak zainstalować iskrę na instrukcjach Redhat 8 krok po kroku
Apache Spark działa na JVM (maszyna wirtualna Java), więc do uruchomienia aplikacji wymagana jest działająca instalacja Java 8. Poza tym w opakowaniu jest wysyłane wiele skorup, jeden z nich to Pyspark, skorupa oparta na Python. Aby z tym pracować, potrzebujesz również zainstalowanego i skonfigurowanego Python 2.
- Aby uzyskać adres URL najnowszego pakietu Spark, musimy odwiedzić witrynę Plaints Spark. Musimy wybrać lustro najbliżej naszej lokalizacji i skopiować adres URL dostarczany przez stronę pobierania. Oznacza to również, że twój adres URL może być inny niż poniższy przykład. Zainstalujemy pakiet poniżej
/optować/, Wprowadzamy więc katalog jakoźródło:# cd /opt
I nakarm aquired adres URL
wgetAby uzyskać pakiet:# wget https: // www-eu.Apache.Org/Dist/Spark/Spark-2.4.0/Spark-2.4.0-bin-hadoop2.7.TGZ
- Rozpakujemy Tarball:
# TAR -xvf Spark -2.4.0-bin-hadoop2.7.TGZ
- I utwórz symbolizję, aby nasze ścieżki były łatwiejsze do zapamiętania w kolejnych krokach:
# ln -s /opt /spark -2.4.0-bin-hadoop2.7 /Opt /Spark
- Tworzymy niepewnego użytkownika, który będzie uruchamiał obie aplikacje, master i niewolnik:
# UserAdd Spark
I ustaw go jako właściciela całości
/Opt/Sparkkatalog, rekurencyjnie:# Chown -r Spark: Spark /Opt /Spark*
- Tworzymy
Systemdplik jednostki/etc/systemd/system/spisk-master.pracadla usługi głównej z następującą zawartością:
Kopiuj[Jednostka] Opis = Apache Spark Master After = Network.Target [Service] Type = Forking User = Spark Group = Spark ExecStart =/opt/Spark/Sbin/Start-Master.sh execstop =/opt/spark/sbin/stop-master.sh [instalacja] WantedBy = Multi-użytkownik.celA także jeden dla usługi niewolników, który będzie
/etc/systemd/system/slaw-slave.praca.pracaZ poniższymi treściami:
Kopiuj[Jednostka] Opis = Apache Spark Slave After = Network.Target [Service] Type = Forking User = Spark Group = Spark ExecStart =/opt/Spark/Sbin/Start-Slave.sh iskra: // rhel8lab.Linuxconfig.org: 7077 execstop =/opt/spark/sbin/stop-slave.sh [instalacja] WantedBy = Multi-użytkownik.celZwróć uwagę na podświetlony adres URL iskier. Jest to skonstruowane z
Spark: //: 7077, W takim przypadku maszyna laboratoryjna, która uruchomi mistrz, ma nazwę hostaRhel8lab.Linuxconfig.org. Imię twojego mistrza będzie inne. Każdy niewolnik musi być w stanie rozwiązać tę nazwę hosta i dotrzeć do mistrza na określonym porcie, którym jest port7077domyślnie. - Po wprowadzeniu plików serwisowych musimy zapytać
SystemdAby je przeczytać:# SystemCtl Demon-Reload
- Możemy zacząć naszego mistrza Spark
Systemd:# Systemctl Start Spark-Master.praca
- Aby sprawdzić, czy nasz Master działa i funkcjonuje, możemy użyć statusu SystemD:
# SystemCtl Status Spark-Master.Service Spark-Master.Service - Apache Spark Master Załadowany: Załadowany (/etc/systemd/System/Spark -Master.praca; wyłączony; PREDET PREDOR: Wyłączony) Aktywne: Aktywne (uruchamianie) od FRI 2019-01-11 16:30:03 CET; 53 minuty Proces: 3308 execstop =/opt/spark/sbin/stop-master.sh (kod = wyjazd, status = 0/Success) Proces: 3339 execStart =/opt/spark/sbin/start-master.sh (kod = wyjazd, status = 0/Success) Główny PID: 3359 (Java) Zadania: 27 (limit: 12544) Pamięć: 219.3M CGroup: /System.Slice/Spark-Master.Service 3359/usr/lib/jvm/java-1.8.0-Openjdk-1.8.0.181.B13-9.El8.x86_64/jre/bin/java -cp/opt/spark/conf/:/opt/spark/jars/* -xmx1g org org.Apache.iskra.wdrożyć.gospodarz.Mistrz -Host […] 11 stycznia 16:30:00 Rhel8lab.Linuxconfig.Org Systemd [1]: Uruchomienie Apache Spark Master… 11 stycznia 16:30:00 Rhel8lab.Linuxconfig.Org start-master.SH [3339]: Uruchamianie org.Apache.iskra.wdrożyć.gospodarz.Master, logowanie do/opt/spark/logs/spark-spark-org.Apache.iskra.wdrożyć.gospodarz.Master-1 […]
Ostatni wiersz wskazuje również główny plik dziennika mistrza, który jest w
dziennikikatalog w ramach katalogu bazowego Spark,/Opt/Sparkw naszym przypadku. Patrząc na ten plik, powinniśmy zobaczyć linię na końcu podobną do poniższego przykładu:2019-01-11 14:45:28 Info Master: 54-Zostałem wybrany liderem! Nowy stan: żywy
Powinniśmy również znaleźć linię, która mówi nam, gdzie słucha interfejs główny:
2019-01-11 16:30:
Jeśli skierujemy przeglądarkę do portu maszyny hosta
8080, Powinniśmy zobaczyć stronę statusu mistrza, bez żadnych pracowników w tej chwili.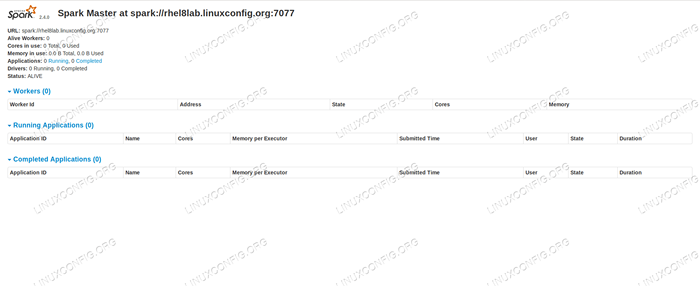 Strona statusu Spark Bez pracowników.
Strona statusu Spark Bez pracowników. Zwróć uwagę na linię URL na stronie statusu Spark Master. To jest ten sam adres URL, którego musimy użyć dla każdego pliku jednostki niewolnika, w którym utworzyliśmy
Krok 5.
Jeśli otrzymamy komunikat o błędzie „odmówionego połączenia” w przeglądarce, prawdopodobnie musimy otworzyć port w zaporze:# Firewall-CMD-Zone = public --add-port = 8080/tcp-Permanent Succes
- Nasz mistrz działa, dołączymy do niego niewolnik. Rozpoczynamy usługę niewolników:
# Systemctl Start Spark-Slave.praca
- Możemy sprawdzić, czy nasz niewolnik działa z systemem:
# SystemCtl Status Spark-Slave.Service Spark Slave.Service - Apache Spark Slave Załadowany: Załadowany (/etc/systemd/system/slaw -slave.praca; wyłączony; PREDERTOR PREDET: niepełnosprawny) Active: Active (Uruchamianie) od PRI 2019-01-11 16:31:41 CET; 1h 3min temu proces: 3515 execstop =/opt/spark/sbin/stop-slave.sh (kod = wychodzący, status = 0/Success) Proces: 3537 execStart =/opt/spark/sbin/start-slave.sh iskra: // rhel8lab.Linuxconfig.ORG: 7077 (kod = wyjazd, status = 0/Success) Główny PID: 3554 (Java) Zadania: 26 (Limit: 12544) Pamięć: 176.1M CGroup: /System.Slice/Slaw-Slave.Service 3554/usr/lib/jvm/java-1.8.0-Openjdk-1.8.0.181.B13-9.El8.x86_64/jre/bin/java -cp/opt/spark/conf/:/opt/spark/jars/* -xmx1g org org.Apache.iskra.wdrożyć.pracownik.Pracownik […] 11 stycznia 16:31:39 Rhel8lab.Linuxconfig.Org Systemd [1]: Rozpoczęcie Apache Spark Slave… 11 stycznia 16:31:39 Rhel8lab.Linuxconfig.Org Start-Slave.SH [3537]: Uruchamianie org.Apache.iskra.wdrożyć.pracownik.Pracownik, logowanie do/opt/spark/logs/Spark-SPAR […]
Wyjście to zapewnia również ścieżkę do pliku dziennika niewolnika (lub pracownika), który będzie w tym samym katalogu, z „pracownikiem” w nazwie. Sprawdzając ten plik, powinniśmy zobaczyć coś podobnego do poniższego wyjścia:
2019-01-11 14:52:23 Informacje Pracownik: 54-Łączenie z Master Rhel8Lab.Linuxconfig.Org: 7077… 2019-01-11 14:52:23 Info ContexThandler: 781-Rozpoczęty.S.J.S.ServletContexThandler@62059f4a /Metrics/Json, NULL, Dostępne,@Spark 2019-01-11 14:52:23 Info TransportClientFactory: 267-Pomyślnie utworzone połączenie z RHEL8LAB.Linuxconfig.Org/10.0.2.15: 7077 Po 58 ms (0 MS wydanych na bootstraps) 2019-01-11 14:52:24 Informacje Pracownik: 54-Pomyślnie zarejestrowany w Master Spark: // Rhel8lab.Linuxconfig.Org: 7077
Wskazuje to, że pracownik jest skutecznie podłączony do Mistrza. W tym samym pliku dziennym znajdziemy wiersz, który mówi nam, że adres URL, na którym słucha pracownik:
2019-01-11 14:52:23 Info WorkerWebui: 54-Związany WorkerWebui do 0.0.0.0, i zaczął się od http: // rhel8lab.Linuxconfig.Org: 8081
Możemy wskazać naszą przeglądarkę na stronę statusu pracownika, gdzie jest wymieniona mistrz.
 Strona statusu Pracownika Spark, podłączona do Master.
Strona statusu Pracownika Spark, podłączona do Master.
W pliku dziennika mistrza powinna pojawić się linia weryfikacji:
2019-01-11 14:52:24 Info Master: 54-Rejestracja pracownika 10.0.2.15: 40815 z 2 rdzeniami, 1024.0 MB RAM
Jeśli teraz ponownie załadujemy stronę Status Master, pracownik również powinien się tam pojawić, z linkiem do strony statusu.
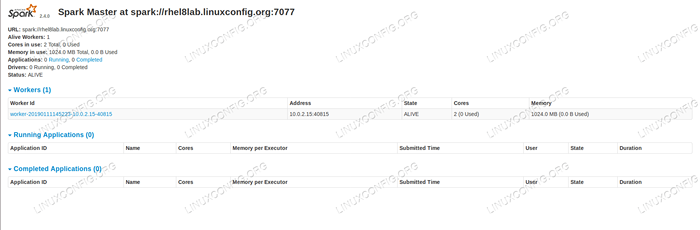 Strona statusu Spark Master z załączonym jednym pracownikiem.
Strona statusu Spark Master z załączonym jednym pracownikiem. Źródła te sprawdzają, czy nasz klaster jest dołączony i gotowy do pracy.
- Aby uruchomić proste zadanie w klastrze, wykonujemy jeden z przykładów wysłanych z pobranym pakietem. Rozważ następujący prosty plik tekstowy
/Opt/Spark/Test.plik:
KopiujLinia 1 Word1 Word2 Word3 Linia 2 Word1 Linia3 Word1 Word2 Word3 Word4Wykonamy
Liczba słów.pyPrzykład, który będzie liczył zdanie każdego słowa w pliku. Możemy użyćiskraUżytkownik, nieźródłoPotrzebne uprawnienia.$/opt/spark/bin/spark-submit/opt/spark/przykłady/src/main/python/słow.PY/Opt/Spark/Test.Plik 2019-01-11 15:56:57 Info SparkContext: 54-Zgłoszona aplikacja: PythonWordCount 2019-01-11 15:56:57 Informacje SecurityManager: 54-Zmiana widoku ACLS na: Spark 2019-01-11 15:56: 57 Info SecurityManager: 54 - Zmiana Modyfikuj ACLS na: Spark […]
W miarę wykonywania zadania podano długie wyjście. Blisko końca wyjścia, wynik jest pokazany, klaster oblicza potrzebne informacje:
2019-01-11 15:57:05 Info Dagscheduler: 54-Zadanie 0 zakończone: Zbierz AT/Opt/Spark/Przykłady/src/main/Python/WordCount.PY: 40, wziął 1.619928 s Linia3: 1 Linia 2: 1 Linia 1: 1 Word4: 1 Word1: 3 Word3: 2 Word2: 2 […]
Dzięki temu widzieliśmy naszą iskrę Apache w akcji. Dodatkowe węzły niewolników można zainstalować i podłączyć do skalowania mocy obliczeniowej naszego klastra.
Powiązane samouczki Linux:
- Jak utworzyć klaster Kubernetes
- Instalacja Oracle Java na Ubuntu 20.04 Focal Fossa Linux
- Rzeczy do zainstalowania na Ubuntu 20.04
- Jak zainstalować Java na Manjaro Linux
- Linux: Zainstaluj Java
- Jak zainstalować Kubernetes na Ubuntu 20.04 Focal Fossa Linux
- Jak zainstalować Kubernetes na Ubuntu 22.04 JAMMY Jellyfish…
- Ubuntu 20.04 Hadoop
- Wprowadzenie do automatyzacji, narzędzi i technik Linuksa
- Ubuntu 20.04 WordPress z instalacją Apache