

Wstęp
- 5061
- 808
- Seweryn Augustyniak
12 marca 2013
autor: Lubos Rendek
Wstęp
Niezależnie od tego, czy administrujesz małą sieć domową, czy sieć korporacyjną dla dużej firmy, przechowywanie danych jest zawsze problemem. Może to być brak miejsca na dysku lub nieefektywne rozwiązanie tworzenia kopii zapasowych. W obu przypadkach GlusterFS może być właściwym narzędziem do rozwiązania problemu, ponieważ umożliwia skalowanie zasobów w poziomie, a także w pionie. W tym przewodniku skonfigurujemy rozproszone i replikowane/lustrzane przechowywanie danych. Jak sama nazwa sugeruje, że rozproszony tryb pamięci GlusterFS pozwoli ci równomiernie redystrybuować dane w wielu węzłach sieci.
Co to jest Glusterfs
Po przeczytaniu wprowadzenia powinieneś mieć już dobry pomysł, czym jest Glusterfs. Możesz myśleć o tym jako o usłudze agregacji dla całej pustej przestrzeni dysku w całej sieci. Łączy wszystkie węzły z instalacją GlusterFS przez TCP lub RDMA, tworząc pojedyncze zasoby pamięci łączące wszystkie dostępne miejsce na dysku z jednym woluminem pamięci ( Rozpowszechniane tryb) lub używa maksymalnej dostępnej przestrzeni dysku na wszystkich notatkach do odzwierciedlenia danych ( Replikowane tryb ). Dlatego każda głośność składa się z wielu węzłów, które w terminologii GlusterFS są wywoływane Cegły.
Wstępne założenia
Chociaż Glusterfs może zainstalować i używać w dowolnym dystrybucji Linux, ten artykuł będzie używał przede wszystkim Ubuntu Linux. Powinieneś jednak być w stanie użyć tego przewodnika w dowolnym dystrybucji Linux, takiej jak Redhat, Fedora, Suse itp. Jedyną częścią, która będzie inna, będzie proces instalacji GlusterFS.
Ponadto ten przewodnik użyje 3 przykładowych nazw hostów:
- składowanie.Server1 - Glusterfs Storage Server
- składowanie.server2 - GlusterFS Storage Server
- składowanie.Klient - GlusterFS Storage Client
Użyj pliku DNS Server lub /etc /hosts, aby zdefiniować nazwy hosta i dostosować swój scenariusz do tego przewodnika.
Instalacja GlusterFS
Serwer GlusterFS musi być zainstalowany na wszystkich hostach, które chcesz dodać do ostatecznego woluminu pamięci. W naszym przypadku będzie to przechowywanie.serwer1 i pamięć.serwer2. Możesz użyć GlusterFS jako pojedynczego serwera i połączenia klienta, aby działać jako serwer NFS. Jednak prawdziwą wartością GlusterFS jest używanie wielu hostów serwerów do jednego z nich. Użyj następującego polecenia Linux na obu serwerach, aby zainstalować serwer GlusterFS:
składowanie.server1 $ sudo apt-get install glusterfs-server
I
składowanie.server2 $ sudo apt-get install glusterfs-server
Powyższe polecenia zainstalują i uruchomi GlusterFs-Server w obu systemach. Potwierdź, że oba serwery działają z:
$ sudo service glusterfs-server status
Rozproszona konfiguracja pamięci
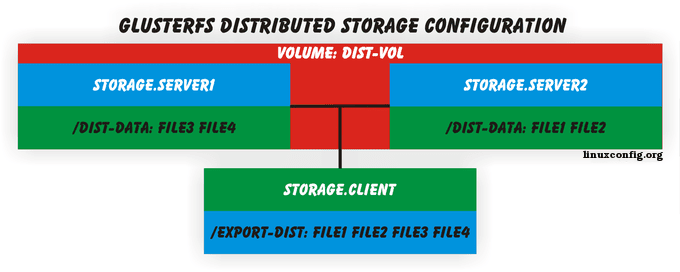
Najpierw utworzymy rozproszony wolumin GlusterFS. W trybie rozproszonym GlusterFS będzie równomiernie rozpowszechniać wszelkie dane we wszystkich podłączonych cegiełkach. Na przykład, jeśli klienci zapisują pliki File1, File2, File3 i File4 do katalogu zamontowanego GLUSTERFS, a następnie serwer, serwer.Storage1 będzie zawierał File1, File2 i serwer.Storage2 otrzyma File3 i File4. Ten scenariusz jest zilustrowany przy użyciu poniższego schematu.
Sonda rówieśnicza
Po pierwsze, musimy zmusić oba serwery GlusterFS do rozmowy ze sobą, co oznacza, że skutecznie tworzymy pulę zaufanych serwerów.
składowanie.Server1 $ sudo gluster Peer Proade Storage.serwer2
Sonda udana
Powyższe polecenie doda przechowywanie.serwer2 do zaufanej puli serwerów. Te ustawienia są replikowane na dowolnych podłączonych serwerach, więc nie musisz uruchamiać powyższego polecenia na innych porcjach. Do tej pory oba serwery będą dostępne plik konfiguracji równorzędnej podobny do tego poniżej:
$ cat/etc/glusterd/peers/951B8732-42f0-42e1-A32f-0e1c4baec4f1
UUID = 951B8732-42F0-42E1-A32F-0E1C4BAEC4F1
State = 3
nazwa hosta1 = przechowywanie.serwer2
Utwórz wolumen pamięci
Następnie możemy użyć obu serwerów do zdefiniowania nowego woluminu pamięci składającego się z dwóch cegieł, po jednym dla każdego serwera.
składowanie.Server1 $ sudo gluster wolumin Utwórz pamięć Dist-Vol.server1:/dist-data \ Storage.server2:/dist-data
Tworzenie dystansu objętościowego zakończyło się powodzeniem. Rozpocznij wolumin, aby uzyskać dostęp do danych.
Powyższe polecenie utworzyło nowy tom o nazwie Dist-vol składający się z dwóch cegieł. Jeśli katalog /dist-data nie istnieje, zostanie również utworzony na obu serwerach przez powyższe polecenie. Jak już wspomniano wcześniej, możesz dodać tylko jedną cegłę do woluminu, a tym samym sprawiając, że serwer ClusterFS działa jako serwer NFS. Możesz sprawdzić, czy Twój nowy tom został utworzony przez:
$ sudo gluster volume Info Dist-vol
Nazwa woluminu: Dist-VOL
Typ: Distribute
Status: utworzony
Liczba cegieł: 2
Typ transportu: TCP
Cegły:
Brick1: Przechowywanie.server1:/dist-data
Brick2: Przechowywanie.server2:/dist-data
Rozpocznij objętość przechowywania
Teraz jesteśmy gotowi rozpocząć nowy tom:
składowanie.server1 $ sudo gluster wolumin start dist-vol
Rozpoczęcie wielkości objętościowe zakończyło się sukcesem
składowanie.server1 $ sudo gluster Info Dist-Vol
Nazwa woluminu: Dist-VOL
Typ: Distribute
Status: Rozpoczął się
Liczba cegieł: 2
Typ transportu: TCP
Cegły:
Brick1: Przechowywanie.server1:/dist-data
Brick2: Przechowywanie.server2:/dist-data
To kończy konfigurację serwera danych GlusterFS w trybie rozproszonym. Rezultatem końcowym powinien być nowa rozproszona objętość o nazwie Dist-vol składająca się z dwóch cegieł.
Konfigurowanie klienta
Teraz, gdy utworzyliśmy nową wolumin GlusterFS, możemy użyć klienta GlusterFS do zamontowania tego woluminu do dowolnych hostów. Zaloguj się do hosta klienta i zainstaluj klienta Glustefs:
składowanie.Klient $ sudo apt-get install glusterfs-client
Następnie utwórz punkt mocowania, do którego zamontujesz nową wolumin Glusterfs Dist-Vol, na przykład Eksport-Dist:
składowanie.klient $ sudo mkdir /export-dist
Teraz możemy zamontować objętość dist-vol glusterfs za pomocą uchwyt Komenda:
składowanie.Klient $ sudo munota -t glusterfs pamięć.Server1: Dist-Vol /Eksport-Dist
Wszystkie krzyki bądź gotowy. Użyj uchwyt polecenie, aby sprawdzić, czy poprawnie zamontowałeś głośność GlusterFS:
$ Mount | Grep Glusterf
Testowanie konfiguracji rozproszonej GlusterFS
Wszystko jest gotowe, abyśmy mogli rozpocząć niektóre testy. Na stronie klienta skrzyni 4 plików w katalogu zamontowanym Glusterfs:
składowanie.Klient $ Touch /Export-Dist /File1 File2 File3 File4
Glusterfs przyjmą teraz wszystkie pliki i rozdzielą je równomiernie wśród wszystkich cegieł w objętości Dist-Vol. Dlatego przechowywanie.Server1 będzie zawierać:
składowanie.server1 $ ls /dist-data /
File3 File4
i przechowywanie.Server2 będzie zawierać:
składowanie.server2 $ ls /dist-data
File1 File2
Oczywiście Twoje wyniki mogą być inne.
Replikowana konfiguracja pamięci
Procedura utworzenia powielania powtórzonego objętości GlusterFS jest podobna do wyjaśnionej wcześniej objętości rozproszonej. W rzeczywistości jedyną różnicą jest sposób tworzenia tomu klastra. Ale chodźmy od samego początku:
Sonda rówieśnicza
Po pierwsze, musimy zmusić oba serwery GlusterFS do rozmowy ze sobą, co oznacza, że skutecznie tworzymy pulę zaufanych serwerów.
składowanie.Server1 $ sudo gluster Peer Proade Storage.serwer2
Sonda udana
Jeśli to już zrobione, możesz pominąć ten krok.
Utwórz wolumen pamięci
W tym kroku musimy utworzyć głośność repliki.
$ Sudo Gluster Volume Utwórz replikę Rep-Vol 2 \ Storage.server1:/Rep-Data Storage.server2:/Rep-Data tworzenie reprezentacji woluminów zakończyło się powodzeniem. Rozpocznij wolumin, aby uzyskać dostęp do danych.
Podstawowym tłumaczeniem powyższego polecenia może być to, że utworzyliśmy powtórzony wolumin (replika) o nazwie Rep-Vol . Liczba 2 w poleceniu wskazuje liczbę pasków, co oznacza, że podczas rozszerzenia tego głośności zawsze musimy dodać liczbę cegieł równych wielokrotnej liczbie paska głośności (2, 4, 8 16 itd.).
Rozpocznij objętość przechowywania
Nadszedł czas, aby rozpocząć nasz nowy powtórzony tom:
$ sudo gluster Volume start Rep-ol
Początkowe powtórka głośności zakończyła się sukcesem
Sprawdzić stan:
składowanie.server1 $ sudo gluster Info Rep-vol
Nazwa woluminu: Repl-VOL
Typ: powtórz
Status: Rozpoczął się
Liczba cegieł: 2
Typ transportu: TCP
Cegły:
Brick1: Przechowywanie.server1:/Rep-Data
Brick2: Przechowywanie.server2:/Rep-Data
Konfigurowanie klienta
Konfiguracja klienta jest taka sama, jak podczas konfigurowania klienta dla rozproszonego mocowania głośności.
Zainstaluj klient:
składowanie.Klient $ sudo apt-get install glusterfs-client
Utwórz punkt mocowania:
składowanie.Klient $ sudo mkdir /export-repl
Zamontuj głośność glusterfs repl-vol za pomocą uchwyt Komenda:
składowanie.Klient $ sudo munota -t glusterfs pamięć.Server1: Rep-VOL /Export-Repl
Wszystkie krzyki są teraz gotowi. Użyj uchwyt polecenie, aby sprawdzić, czy poprawnie zamontowałeś głośność GlusterFS:
$ Mount | Grep Glusterf
Testowanie Glusterfs Replikowane konfiguracja
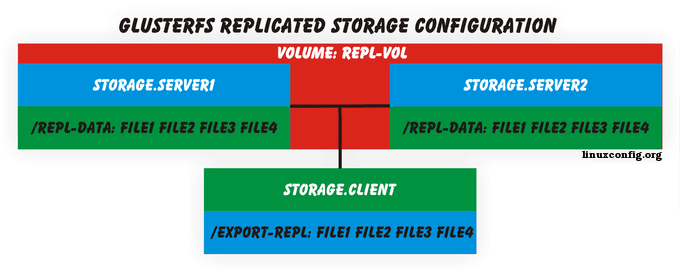
Punktem powtórzonego woluminu GlusterFS jest to, że dane będą płynnie odzwierciedlone we wszystkich węzłach. Zatem podczas tworzenia plików w /report-zastąpieniu /
$ Touch /Export-Repl /File1 File2 File3 File4
Wszystkie pliki będą dostępne na obu serwerach:
składowanie.server1 $ LS /Rep-Data /
File1 File2 File3 File4
I
składowanie.server2 $ LS /Rep-Data /
File1 File2 File3 File4
Rozszerzające się objętości GlusterFS
W przypadku, gdy musisz zwiększyć swoje przechowywanie danych, aby zawierać dodatkowe cegły, proces jest prosty:
$ Sudo Gluster Volume Add-Brick Rep-vol Storage.server3:/Rep-Vol Storage.server4: Rep-VOL /Export-Repl
To doda kolejne dwie cegłę pamięci do reprezentacji. Po dodaniu nowych cegieł może być konieczne ponowne zrównoważenie całego tomu z:
$ sudo gluster Volume Remalance Rep-Vol Fix-Layout Start
i zsynchronizuj / migruj wszystkie dane z:
$ sudo gluster Volume Remalance Rep-vol migrare-data start
Ponadto możesz sprawdzić postęp zrównoważenia
$ Sudo Gluster Volume Remalance Vol0 Status
Ustawienia bezpieczeństwa
Oprócz powyższej konfiguracji możesz zwiększyć bezpieczeństwo całego woluminu, umożliwiając tylko niektórym hostom dołączenie do puli zaufania. Na przykład, jeśli chcemy tylko hosta z 10.1.1.10 Aby zostać wpuszonym na udział w repub
$ sudo gluster tom zestaw repl-vol auth.Pozwól 10.1.1.10
W przypadku, gdy potrzebujemy całej podsieci, po prostu użyj gwiazdka:
$ sudo gluster tom zestaw repl-vol auth.Pozwól 10.1.1.*
Wniosek
Glusterfs to potężne oprogramowanie licencjonowane GPL3. Można go również użyć jako szybkiego oprogramowania RAID 1, definiując dwie oddzielne cegły urządzeń fizycznych na jednym hoście w powtórzonej głośności Glusterfs. Oczywiście lepiej byłoby skorzystać z RAID oprogramowania do tej pracy, ale nadal istnieje taka możliwość. Uważam, że GlusterFS jest łatwy w użyciu i konfiguracji.
Załącznik
Tutaj po prostu wymienię kilka błędów i odpowiedzi, które napotkałem podczas gry z Glusterfs:
Niepoprawna liczba cegieł
Nieprawidłowa liczba cegieł dostarczonych 1 dla replikowania typu z liczbą 2
Jeśli utworzyłeś głośność z liczbą paska 2, musisz dodać w tym czasie co najmniej 2 dodatkowe cegły.
Przechowywanie hosta.Server1 nie znajomy
Przechowywanie hosta.Server1 nie znajomy
Najpierw dodaj serwer GlusterFS do puli zaufania, zanim spróbujesz włączyć go do woluminu.
Powiązane samouczki Linux:
- Lustra Ubuntu
- Rzeczy do zrobienia po zainstalowaniu Ubuntu 20.04 Focal Fossa Linux
- Rzeczy do zainstalowania na Ubuntu 20.04
- Wprowadzenie do automatyzacji, narzędzi i technik Linuksa
- Rzeczy do zrobienia po zainstalowaniu Ubuntu 22.04 JAMMY Jellyfish…
- Jak korzystać z ADB Android Debug Bridge do zarządzania Androidem…
- Ubuntu 20.04 Przewodnik
- Plik WGET Pobierz na Linux
- Rzeczy do zainstalowania na Ubuntu 22.04
- Ubuntu 22.04 Kopia zapasowa i przywracanie systemu