

LFCS Jak używać polecenia GNU „SED” do tworzenia, edytowania i manipulowania plikami w Linux - część 1

- 726
- 120
- Igor Madej
Fundacja Linux ogłosiła LFCS (Sysadmin z certyfikatem Linux Foundation) Certyfikacja, nowy program, którego celem jest pomoc osobom na całym świecie w uzyskaniu certyfikatów w zakresie Basic to Intermediate System Administration Systems dla systemów Linux. Obejmuje to wspieranie systemów i usług uruchamiających, a także rozwiązywanie problemów i analizy z pierwszej ręki oraz inteligentne podejmowanie decyzji w celu eskalacji problemów z zespołami inżynieryjnymi.
 Certyfikowane sysadmin Linux Foundation - część 1
Certyfikowane sysadmin Linux Foundation - część 1 Proszę obejrzeć poniższy film, który pokazuje program certyfikacji Fundacji Linux.
Seria będzie zatytułowana przygotowanie do LFCS (Sysadmin z certyfikatem Linux Foundation) Części 1 Poprzez 10 i omówić następujące tematy dla Ubuntu, Centos i OpenSuse:
Część 1: Jak używać polecenia GNU „SED” do tworzenia, edytowania i manipulowania plikami w Linux Część 2: Jak zainstalować i używać vi/m jako edytora pełnego tekstu Część 3: Archiwizacja plików/katalogów i znajdowanie plików na systemie plików Część 4: Partycjonowanie urządzeń pamięci, formatowanie systemów plików i konfigurowanie partycji wymiany Część 5: Mount/Unmount Local and Network (Samba i NFS) w systemie Linux Część 6: Montaż partycji jako urządzeń RAID - tworzenie i zarządzanie tworzeniem kopii zapasowych systemu Część 7: Zarządzanie procesem i usługami uruchamiania systemu (Sysvinit, SystemD i Upstart Część 8: Zarządzanie użytkownikami i grupami, uprawnienia i atrybuty plików oraz umożliwienie dostępu SUDO na kontach Część 9: Zarządzanie pakietami Linux z Yum, RPM, APT, DPKG, Aptitude i Zypper Część 10: Uczenie się podstawowych scenariuszy i rozwiązywania problemów z systemem plikówWażny: Ze względu na zmiany w wymaganiach dotyczących certyfikacji LFCS Luty. 2, 2016, Uwzględniamy następujące niezbędne tematy do serii LFCS opublikowanej tutaj. Aby przygotować się do tego egzaminu, jesteś bardzo zachęcany do korzystania z serii LFCE.
Część 11: Jak zarządzać i tworzyć LVM za pomocą poleceń VGCreate, LVCreate i Lvextend Część 12: Jak zbadać Linuksa za pomocą zainstalowanych dokumentacji i narzędzi pomocy Część 13: Jak skonfigurować i rozwiązywać problemy z Grand Unified Bootloader (GRUB) Część 14: Monitoruj przetwarzanie Linuxa użycie zasobów i ustawiaj limity procesu na zasadzie dla użytkownika Część 15: Jak ustawić lub modyfikować parametry środowiska wykonawczego jądra w systemach Linux Część 16: Jak ustawić listy kontroli dostępu (ACL) i kwoty dysku dla użytkowników i grup Część 17: Jak zainstalować Cygwin, środowisko linii komendy przypominające system Windows Część 18: Ostateczny przewodnik konfiguracji serwera FTP, aby umożliwić anonimowe logowanie Część 19: Skonfiguruj podstawowy rekuryujący serwer DNS i skonfiguruj strefy dla domeny Część 20: Wdrożenie obowiązkowej kontroli dostępu z Selinux lub Apparmor w LinuxTen post jest częścią 1 a Seria 20-tutorialska, które obejmie niezbędne domeny i kompetencje, które są wymagane dla LFCS Egzamin certyfikacyjny. To powiedziawszy, zwolnij swój terminal i zacznijmy.
Przetwarzanie strumieni tekstu w Linux
Linux traktuje wejście i wyjście z programów jako strumieni (lub sekwencji) znaków. Aby rozpocząć zrozumienie przekierowania i rur, musimy najpierw zrozumieć trzy najważniejsze typy strumieni we/wy (wejściowe i wyjściowe), które w rzeczywistości są specjalnymi plikami (według konwencji w UNIX i Linux, strumieniach danych i peryferyjnych lub plikach urządzeń, są również traktowane jako zwykłe pliki).
Różnica pomiędzy > (operator przekierowania) i | (Operator rurociągu) polega na tym, że podczas gdy pierwsze łączy polecenie z plikiem, ten ostatni łączy wyjście polecenia z innym poleceniem.
# polecenie> plik # polecenie 1 | Command2
Ponieważ operator przekierowania tworzy lub zastępuje pliki w milczeniu, musimy używać ich z ekstremalną ostrożnością i nigdy nie pomylić go z rurociągiem. Jedną zaletą rur w systemach Linux i UNIX jest to, że nie ma pliku pośredniego związanego z rury - stdout pierwszego polecenia nie jest zapisywany w pliku, a następnie odczytany przez drugie polecenie.
Do następujących ćwiczeń użyjemy wiersza „Szczęśliwe dziecko”(Anonimowy autor).
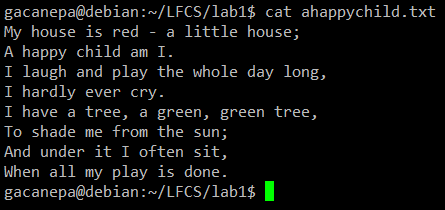 Przykład polecenia CAT
Przykład polecenia CAT Za pomocą SED
Imię sed jest skrót od edytora strumieniowego. Dla tych, którzy nie znają tego terminu, edytor strumienia służy do wykonywania podstawowych transformacji tekstu w strumieniu wejściowym (plik lub wejście z rurociągu).
Najbardziej podstawowym (i popularnym) wykorzystaniem SED jest zastąpienie postaci. Zaczniemy od zmiany każdego wystąpienia małej litery y do wielkiego Y i przekierowanie wyjścia do ahappychild2.tekst. G Flaga wskazuje, że SED powinien wykonać podstawienie wszystkich przypadków terminu na każdym wierszu pliku. Jeśli ta flaga zostanie pominięta, SED zastąpi tylko pierwsze wystąpienie terminu na każdej linii.
Podstawowa składnia:
# sed 's/term/zamiennik/flaga' '
Nasz przykład:
# sed 's/y/y/g' ahappychild.txt> ahappychild2.tekst
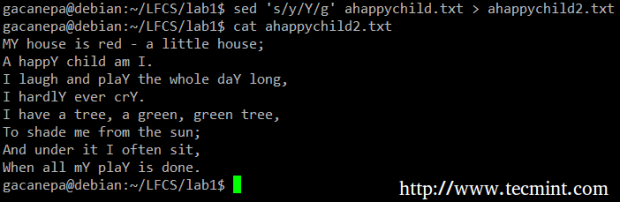 Przykład polecenia SED
Przykład polecenia SED Jeśli chcesz wyszukać lub wymienić charakter specjalny (taki jak /, \, I) Musisz uciec, w terminie lub ciągach zastępczych, z cięciem wstecznym.
Na przykład zastąpimy to słowo i ampersand. W tym samym czasie zastąpimy słowo I z Ty Kiedy pierwszy zostanie znaleziony na początku linii.
# sed 's/i/\ &/g; s/^i/you/g' ahappychild.tekst
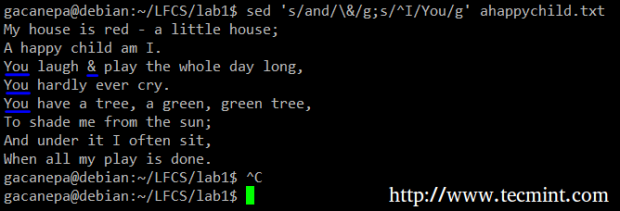 SED Zastąp ciąg
SED Zastąp ciąg W powyższym poleceniu a ^ (znak CARET) to dobrze znane wyrażenie regularne, które jest używane do przedstawienia początku linii.
Jak widać, możemy połączyć dwa lub więcej poleceń zastępczych (i użyć w nich wyrażeń regularnych), oddzielając je półkolisem i dołączając zestaw w pojedynczych cytatach.
Kolejnym zastosowaniem SED jest (lub usuwanie) wybranej części pliku. W poniższym przykładzie wyświetlimy pierwsze 5 wierszy /var/log/wiadomości od 8 czerwca.
# sed -n '/^Jun 8/p'/var/log/wiadomości | sed -n 1,5p
Zauważ, że domyślnie SED drukuje każdą linię. Możemy zastąpić to zachowanie -N opcja, a następnie powiedz SED, aby wydrukował (wskazany przez P) Tylko część pliku (lub rury), która pasuje do wzoru (8 czerwca na początku linii w pierwszym przypadku i wierszach od 1 do 5 obejmujących w drugim przypadku).
Wreszcie, może być przydatne podczas kontroli skryptów lub plików konfiguracyjnych w celu sprawdzenia samego kodu i pomijania komentarzy. Następujące sed jedno-liniowo usuwa (D) puste linie lub te, które zaczynają się od # ( | Charakter wskazuje logikę lub między dwoma wyrażeniami regularnymi).
# sed '/^# \ |^$/d' apache2.conf
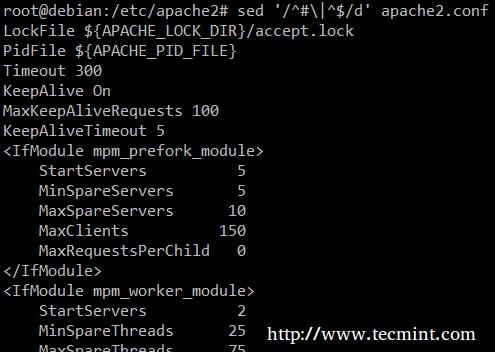 SED String mecz
SED String mecz polecenie uniq
Uniq Polecenie pozwala nam zgłaszać lub usuwać zduplikowane wiersze w pliku, domyślnie piszę do stdout. Musimy to zauważyć Uniq nie wykrywa powtarzanych linii, chyba że są one sąsiadujące. Zatem, Uniq jest powszechnie używany wraz z poprzednim sortować (który służy do sortowania wierszy plików tekstowych). Domyślnie, sortować bierze pierwsze pole (oddzielone przestrzeniami) jako pole kluczowe. Aby określić inne pole kluczowe, musimy użyć -k opcja.
Przykłady
du -sch/ścieżka/do/katalog/* Polecenie zwraca wykorzystanie przestrzeni dysku na podkazanie i pliki w określonym katalogu w formacie czytelnym człowieka (pokazuje również całkowitą na katalog) i nie zamawia danych wyjściowych według rozmiar. Możemy użyć następującego polecenia, aby sortować według rozmiaru.
# du -sch /var /* | sort -h
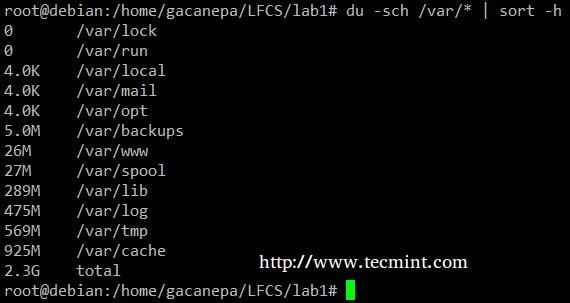 SORT PRZYKŁAD
SORT PRZYKŁAD Możesz policzyć liczbę zdarzeń w dzienniku według daty, mówiąc Uniq Aby wykonać porównanie przy użyciu pierwszych 6 znaków (-w 6) każdej linii (gdzie określono datę) i poprzedzając każdą linię wyjściową liczbą wystąpień (-C) z następującym poleceniem.
# cat/var/log/poczta.Log | uniq -c -w 6
 Licz liczby w pliku
Licz liczby w pliku Na koniec możesz połączyć sortować I Uniq (jak zwykle). Rozważ następujący plik z listą dawców, datę darowizny i kwoty. Załóżmy, że chcemy wiedzieć, ilu jest unikalnych dawców. Użyjemy następującego polecenia, aby wyciąć pierwsze pole (pola są wyznaczone przez dwukropek), sortować według nazwy i usunąć zduplikowane wiersze.
# cat sortuniq.txt | CUT -D: -f1 | SORT | Uniq
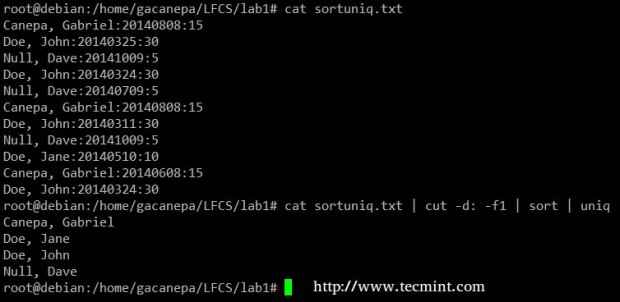 Znajdź unikalne rekordy w pliku
Znajdź unikalne rekordy w pliku Przeczytaj także: 13 Przykłady poleceń „CAT”
polecenie GREP
Grep wyszukuje pliki tekstowe lub (wyjście polecenia) w celu wystąpienia określonego wyrażenia regularnego i wysyła dowolną linię zawierającą dopasowanie do standardowego wyjścia.
Przykłady
Wyświetlić informacje z /etc/passwd dla użytkownika Gacanepa, ignorowanie przypadku.
# grep -i gacanepa /etc /passwd
 Przykład polecenia GREP
Przykład polecenia GREP Pokaż całą zawartość /itp którego imię zaczyna RC a następnie dowolny pojedynczy numer.
# ls -l /itp. | GREP RC [0-9]
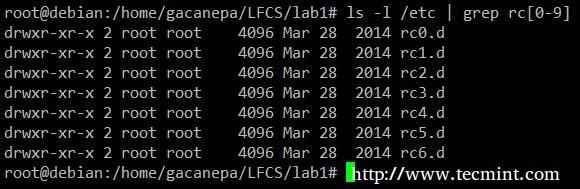 Wymień zawartość za pomocą GREP
Wymień zawartość za pomocą GREP Przeczytaj także: 12 przykładów poleceń „grep”
TR Wykorzystanie polecenia
tr Polecenie może być użyte do tłumaczenia (zmiany) lub usuwania znaków ze stdin i zapisu wyniku do stdout.
Przykłady
Zmień wszystkie małe litery na wielki poziom w sortuniq.plik txt.
# cat sortuniq.txt | Tr [: dolny:] [: Upper:]
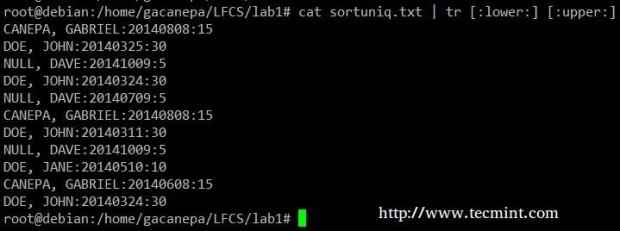 Sortuj struny w pliku
Sortuj struny w pliku Wyciśnij ogranicznik w wyjściu ls -l tylko jedno miejsce.
# ls -l | Tr -s "
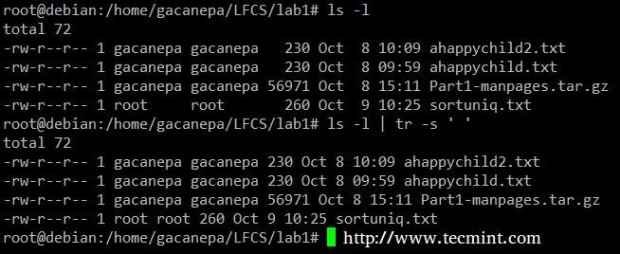 Ściśnij ogranicznik
Ściśnij ogranicznik wyciąć użycie polecenia
cięcie Polecenie wyodrębnia części linii wejściowych (ze stdin lub plików) i wyświetla wynik na standardowym wyjściu, na podstawie liczby bajtów (-B opcja), znaki (-C) lub pola (-F). W tym ostatnim przypadku (w oparciu o pola) domyślnym separatorem pola jest zakładką, ale inny ogranicznik można określić za pomocą za pomocą -D opcja.
Przykłady
Wyodrębniają konta użytkowników i przypisane do nich domyślne powłoki /etc/passwd ( -D opcja pozwala nam określić ograniczenie pola i -F przełącznik wskazuje, które pola zostaną wyodrębnione.
# cat /etc /passwd | CUT -D: -F1,7
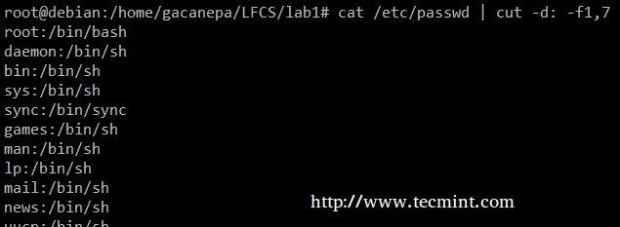 Wyodrębnij konta użytkowników
Wyodrębnij konta użytkowników Podsumowując, utworzymy strumień tekstowy składający się z pierwszego i trzeciego nie blankiego plików wyjścia ostatni Komenda. Użyjemy Grep jako pierwszy filtr do sprawdzenia sesji użytkownika Gacanepa, Następnie wyciśnij ograniczenia tylko do jednego miejsca (Tr -s"). Następnie wyodrębnimy pierwsze i trzecie pola z cięcie, i na koniec sortuj według drugiego pola (adresy IP w tym przypadku) pokazujący unikalny.
# Ostatni | Grep Gacanepa | tr -s "| cut -d" -f1,3 | sort -k2 | Uniq
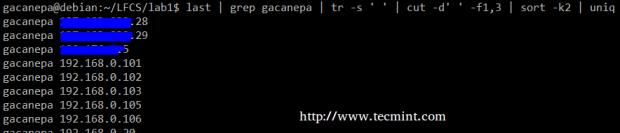 ostatni przykład polecenia
ostatni przykład polecenia Powyższe polecenie pokazuje, w jaki sposób można łączyć wiele poleceń i rur, aby uzyskać przefiltrowane dane zgodnie z naszymi pragnieniami. Zapraszam do uruchomienia go przez części, aby pomóc Ci zobaczyć wyjście, które jest potokowe z jednego polecenia do drugiego (przy okazji może to być świetne doświadczenie edukacyjne!).
Streszczenie
Chociaż ten przykład (wraz z resztą przykładów w bieżącym samouczku) może nie wydawać się bardzo przydatne na pierwszy rzut oka, są one miłym punktem wyjścia do rozpoczęcia eksperymentu z poleceniami używanymi do tworzenia, edytowania i manipulowania plikami z Linux wiersz poleceń. Zostaw swoje pytania i komentarze poniżej - będą one bardzo mile widziane!
Linki referencyjne
- O LFC
- Po co uzyskać certyfikat Linux Foundation?
- Zarejestruj się na egzamin LFCS
- « LFCS Jak instalować i używać VI/VIM jako edytora pełnego tekstu - Część 2
- WPSCAN - Skaner w podatności na podatność WordPress Black Box »